

















































More Related Content
What's hot (20)
Viewers also liked (19)





![[NYJavaSig] Riding the Distributed Streams - Feb 2nd, 2017](https://cdn.slidesharecdn.com/ss_thumbnails/ridingdistributedstreams-nyjavasig-02-02-2017-170203005616-thumbnail.jpg?width=560&fit=bounds)











Similar to Fault Tolerance and Processing Semantics in Apache Apex (19)



















Recently uploaded (20)




















Fault Tolerance and Processing Semantics in Apache Apex
- 1. Apache Apex (incubating) Fault Tolerance and Processing Semantics Thomas Weise, Architect & Co-founder, PPMC member Pramod Immaneni, Architect, PPMC member March 24th 2016
- 2. Apache Apex Features • In-memory Stream Processing • Partitioning and Scaling out • Windowing (temporal boundary) • Reliability ᵒ Stateful ᵒ Automatic Recovery ᵒ Processing Guarantees • Operability • Compute Locality • Dynamic updates 2
- 4. Native Hadoop Integration 4 • YARN is the resource manager • HDFS used for storing any persistent state
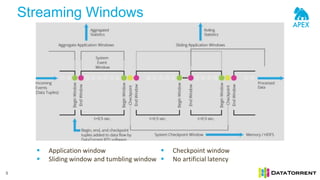
- 5. Streaming Windows 5 Application window Sliding window and tumbling window Checkpoint window No artificial latency
- 6. Fault Tolerance 6 • Operator state is checkpointed to persistent store ᵒ Automatically performed by engine, no additional coding needed ᵒ Asynchronous and distributed ᵒ In case of failure operators are restarted from checkpoint state • Automatic detection and recovery of failed containers ᵒ Heartbeat mechanism ᵒ YARN process status notification • Buffering to enable replay of data from recovered point ᵒ Fast, incremental recovery, spike handling • Application master state checkpointed ᵒ Snapshot of physical (and logical) plan ᵒ Execution layer change log
- 7. Checkpointing Operator State 7 • Save state of operator so that it can be recovered on failure • Pluggable storage handler • Default implementation ᵒ Serialization with Kryo ᵒ All non-transient fields serialized ᵒ Serialized state written to HDFS ᵒ Writes asynchronous, non-blocking • Possible to implement custom handlers for alternative approach to extract state or different storage backend (such as IMDG) • For operators that rely on previous state for computation ᵒ Operators can be marked @Stateless to skip checkpointing • Checkpoint frequency tunable (by default 30s) ᵒ Based on streaming windows for consistent state
- 8. • In-memory PubSub • Stores results emitted by operator until committed • Handles backpressure / spillover to local disk • Ordering, idempotency Operator 1 Container 1 Buffer Server Node 1 Operator 2 Container 2 Node 2 Buffer Server 8
- 9. Application Master State 9 • Snapshot state on plan change ᵒ Serialize Physical Plan (includes logical plan) ᵒ Infrequent, expensive operation • WAL (Write-ahead-Log) for state changes ᵒ Execution layer changes ᵒ Container, operator state, property changes • Containers locate master through DFS ᵒ AM can fail and restart, other containers need to find it ᵒ Work preserving restart • Recovery ᵒ YARN restarts application master ᵒ Apex restores state from snapshot and replays log
- 10. • Container process fails • NM detects • In case of AM (Apex Application Master), YARN launches replacement container (for attempt count < max) • Node Manager Process fails • RM detects NM failure and notifies AM • Machine fails • RM detects NM/AM failure and recovers or notifies AM • RM fails - RM HA option • Entire YARN cluster down – stateful restart of Apex application Failure Scenarios 10
- 11. NM NM Resource Manager Apex AM 3 2 1 Apex AM 1 2 3 NM Failure Scenarios NM 11
- 12. Failure Scenarios … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 0 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 7 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 10 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 7 12
- 13. Processing Guarantees 13 At-least-once • On recovery data will be replayed from a previous checkpoint ᵒ No messages lost ᵒ Default, suitable for most applications • Can be used to ensure data is written once to store ᵒ Transactions with meta information, Rewinding output, Feedback from external entity, Idempotent operations At-most-once • On recovery the latest data is made available to operator ᵒ Useful in use cases where some data loss is acceptable and latest data is sufficient Exactly-once ᵒ At-least-once + idempotency + transactional mechanisms (operator logic) to achieve end-to-end exactly once behavior
- 14. End-to-End Exactly Once 14 • Becomes important when writing to external systems • Data should not be duplicated or lost in the external system even in case of application failures • Common external systems ᵒ Databases ᵒ Files ᵒ Message queues • Platform support for at least once is a must so that no data is lost • Data duplication must still be avoided when data is replayed from checkpoint ᵒ Operators implement the logic dependent on the external system • Aid of platform features such as stateful checkpointing and windowing • Three different mechanisms with implementations explained in next slides
- 15. Files 15 • Streaming data is being written to file on a continuous basis • Failure at a random point results in file with an unknown amount of data • Operator works with platform to ensure exactly once ᵒ Platform responsibility • Restores state and restarts operator from an earlier checkpoint • Platform replays data from the exact point after checkpoint ᵒ Operator responsibility • Replayed data doesn’t get duplicated in the file • Accomplishes by keeping track of file offset as state ᵒ Details in next slide • Implemented in operator AbstractFileOutputOperator in apache/incubator- apex-malhar github repository available here • Example application AtomicFileOutputApp available here
- 16. Exactly Once Strategy 16 File Data Offset • Operator saves file offset during checkpoint • File contents are flushed before checkpoint to ensure there is no pending data in buffer • On recovery platform restores the file offset value from checkpoint • Operator truncates the file to the offset • Starts writing data again • Ensures no data is duplicated or lost Chk
- 17. Transactional databases 17 • Use of streaming windows • For exactly once in failure scenarios ᵒ Operator uses transactions ᵒ Stores window id in a separate table in the database ᵒ Details in next slide • Implemented in operator AbstractJdbcTransactionableOutputOperator in apache/incubator-apex-malhar github repository available here • Example application streaming data in from kafka and writing to a JDBC database is available here
- 18. Exactly Once Strategy 18 d11 d12 d13 d21 d22 d23 lwn1 lwn2 lwn3 op-id wn chk wn wn+1 Lwn+11 Lwn+12 Lwn+13 op-id wn+1 Data Table Meta Table • Data in a window is written out in a single transaction • Window id is also written to a meta table as part of the same transaction • Operator reads the window id from meta table on recovery • Ignores data for windows less than the recovered window id and writes new data • Partial window data before failure will not appear in data table as transaction was not committed • Assumes idempotency for replay
- 19. Stateful Message Queue 19 • Data is being sent to a stateful message queue like Apache Kafka • On failure data already sent to message queue should not be re-sent • Exactly once strategy ᵒ Sends a key along with data that is monotonically increasing ᵒ On recovery operator asks the message queue for the last sent message • Gets the recovery key from the message ᵒ Ignores all replayed data with key that is less than or equal to the recovered key ᵒ If the key is not monotonically increasing then data can be sorted on the key at the end of the window and sent to message queue • Implemented in operator AbstractExactlyOnceKafkaOutputOperator in apache/incubator-apex-malhar github repository available here
- 20. Resources 20 • Subscribe - http://apex.incubator.apache.org/community.html • Download - http://apex.incubator.apache.org/downloads.html • Apex website - http://apex.incubator.apache.org/ • Twitter - @ApacheApex; Follow - https://twitter.com/apacheapex • Facebook - https://www.facebook.com/ApacheApex/ • Meetup - http://www.meetup.com/topics/apache-apex
- 21. Q&A 21