







集成学习
普通决策树与随机森林的对比
生成circles数据集
X,y = datasets.make_moons(n_samples=500,noise=0.3,random_state=42)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()

画图函数
def plot_decision_boundary(model, X, y):
x0_min, x0_max = X[:,0].min()-1, X[:,0].max()+1
x1_min, x1_max = X[:,1].min()-1, X[:,1].max()+1
x0, x1 = np.meshgrid(np.linspace(x0_min, x0_max, 100), np.linspace(x1_min, x1_max, 100))
Z = model.predict(np.c_[x0.ravel(), x1.ravel()])
Z = Z.reshape(x0.shape)
plt.contourf(x0, x1, Z, cmap=plt.cm.Spectral)
plt.ylabel('x1')
plt.xlabel('x0')
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(y))
plt.show()
使用决策树进行预测
构建决策树并训练
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=6)
dt_clf.fit(X, y)
plot_decision_boundary(dt_clf,X,y)
画图
由于决策树喜欢直来直往,所以预测结果如下

交叉验证
from sklearn.model_selection import cross_val_score
print(cross_val_score(dt_clf,X, y, cv=5).mean()) #cv决定做几轮交叉验证
#分折交叉验证,会按照原始类别比例分割数据集
from sklearn.model_selection import StratifiedKFold
strKFold = StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
print(cross_val_score(dt_clf,X, y,cv=strKFold).mean())
#留一法交叉验证
from sklearn.model_selection import LeaveOneOut
loout = LeaveOneOut()
print(cross_val_score(dt_clf,X, y,cv=loout).mean())
#可以控制划分迭代次数、每次划分时测试集和训练集的比例(也就是说:可以存在既不在训练集也不再测试集的情况)
from sklearn.model_selection import ShuffleSplit
shufspl = ShuffleSplit(train_size=.5,test_size=.4,n_splits=8) #迭代8次;
print(cross_val_score(dt_clf,X, y,cv=shufspl).mean())

使用Voting Classifier 投票
构建投票分类器
Voting Classifier 投票是一种硬性投票,即得到预测结果之后进行投票
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('knn_clf',KNeighborsClassifier(n_neighbors=7)),
('gnb_clf',GaussianNB()),
('dt_clf', DecisionTreeClassifier(max_depth=6))
],voting='hard')
voting_clf.fit(X_train,y_train)
voting_clf.score(X_test,y_test)

画图
plot_decision_boundary(voting_clf,X,y)

Soft Voting 分类器
Soft Voting 分类器是一种软投票,他参照各个分类器所产生的概率进行投票
构建投票分类器
voting_clf = VotingClassifier(e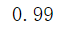
stimators=[
('knn_clf',KNeighborsClassifier(n_neighbors=7)),
('gnb_clf',GaussianNB()),
('dt_clf', DecisionTreeClassifier(max_depth=6))
],voting='soft')
voting_clf.fit(X_train,y_train)
voting_clf.score(X_test,y_test)

画图

bagging
解析
建立多个模型,从数据中随机选取部分数据训练不同的模型,通过多个模型的预测结果来确定最终的预测结果。
多个决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),n_estimators=500,max_samples=100,bootstrap=True)
bagging_clf.fit(X_train,y_train)
bagging_clf.score(X,y)

画图

个人感觉这个的预测结果跟单个决策树的结果差不多,也是直来直去的
Out of Bag-oob
跟bagging的做法相似,唯一的不同是每个模型在选取一部分数据之后,下一个模型选择仅从未被选中的数据中选择数据集
代码实现
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),#分类器
n_estimators=500,#分类器个数
max_samples=100,#每个模型训练取样本数
bootstrap=True,#放回取样
oob_score=True)#out of bag
bagging_clf.fit(X,y)
bagging_clf.oob_score_

画图

这个的预测结果也差不多,也许换做其他的数据集效果会好些
随机森林
随机森林与由多个决策树构成的集成学习实质效果是一样的
代码实现
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=500,random_state=666,oob_score=True)
rf_clf.fit(X,y)
rf_clf.oob_score_

画图

极端树
极端随机树算法与随机森林算法都是由许多决策树构成。极限树与随机森林的主要区别随机森林应用的是Bagging模型,极端树使用的所有的样本,只是特征是随机选取的,因为分裂是随机的,所以在某种程度上比随机森林得到的结果更加好。
代码实现
from sklearn.ensemble import ExtraTreesClassifier
et_clf = ExtraTreesClassifier(n_estimators=500,random_state=666,bootstrap=True,oob_score=True)
et_clf.fit(X,y)
et_clf.oob_score_

画图

Ada Boosting
对于每一个模型训练产生的预测结果进行加权,上一个模型预测失败的数据权值将会提高,下一个模型使用的数据是经过加权后的数据
代码实现
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=6),n_estimators=500)
ada_clf.fit(X_train,y_train)
ada_clf.score(X_test,y_test)

画图

Gradient Boosting
只训练预测错误的数据
代码实现
from sklearn.ensemble import GradientBoostingClassifier
gd_clf = GradientBoostingClassifier(max_depth=6,n_estimators=500)
gd_clf.fit(X_train,y_train)
gd_clf.score(X_test,y_test)

画图




















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











