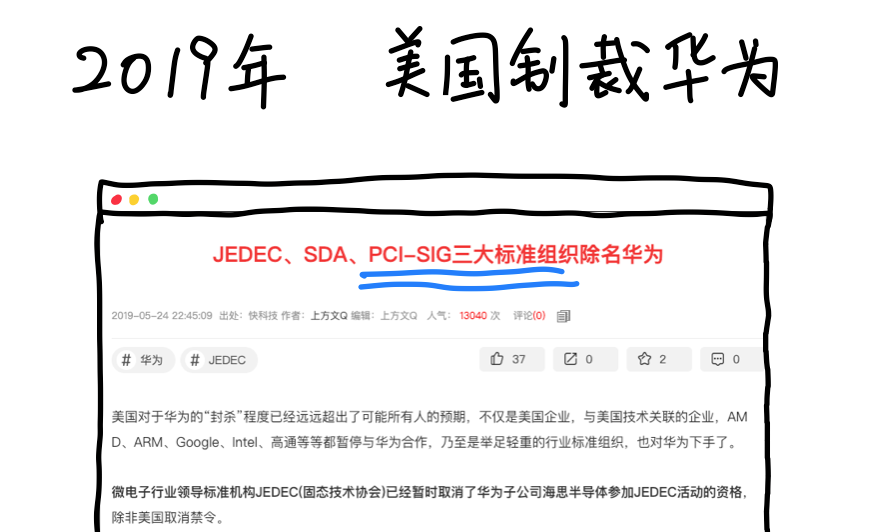
美国为了彻底封锁中国的AI技术发展,把英伟达专门给中国「特供」的性能阉割版芯片H20也给禁了。
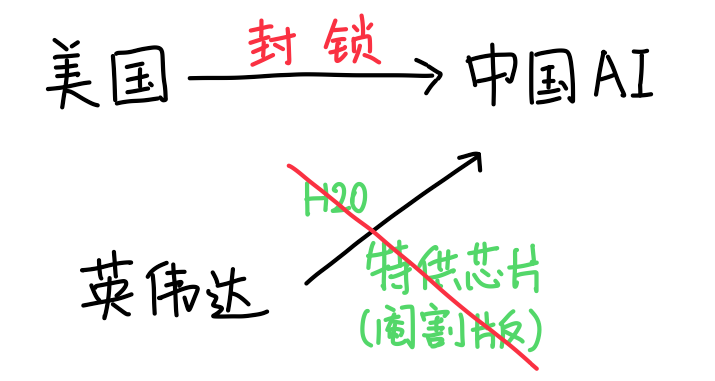
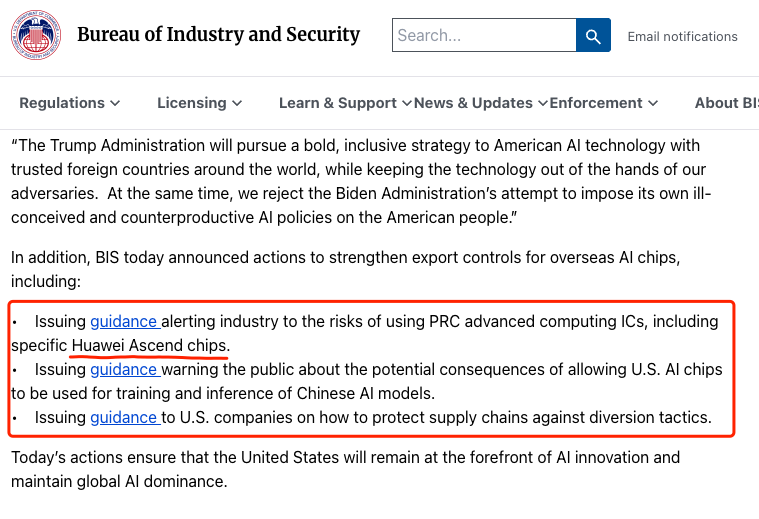
不准拿美国芯片来跑中国的AI模型,否则会被警告。
要防止从其他地方买美国芯片再转运到中国。
最离谱的一条是:在全世界任何地方都不准用华为的昇腾芯片。




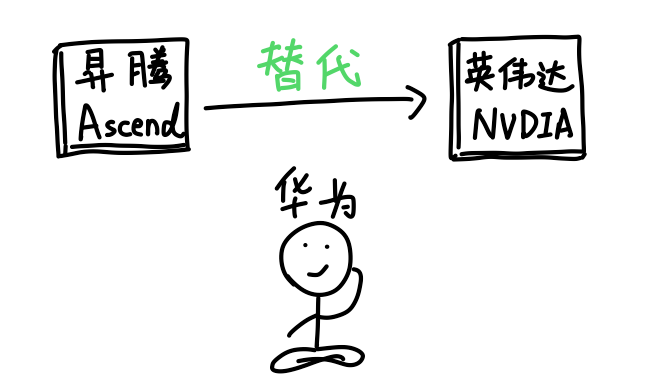
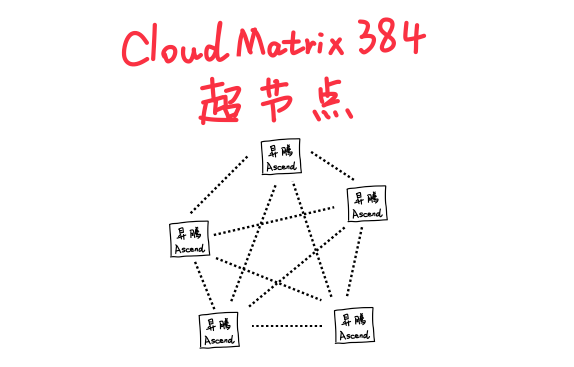
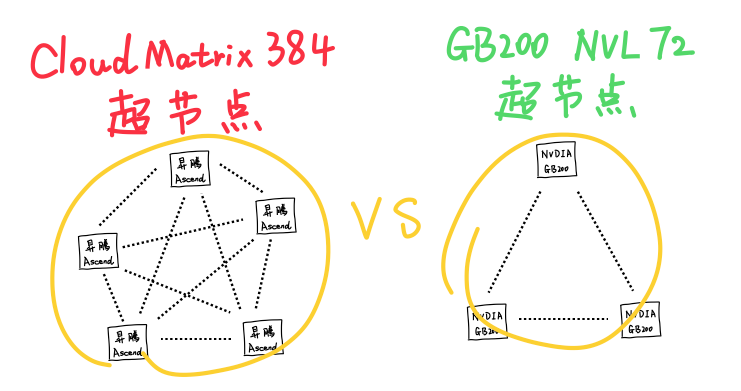



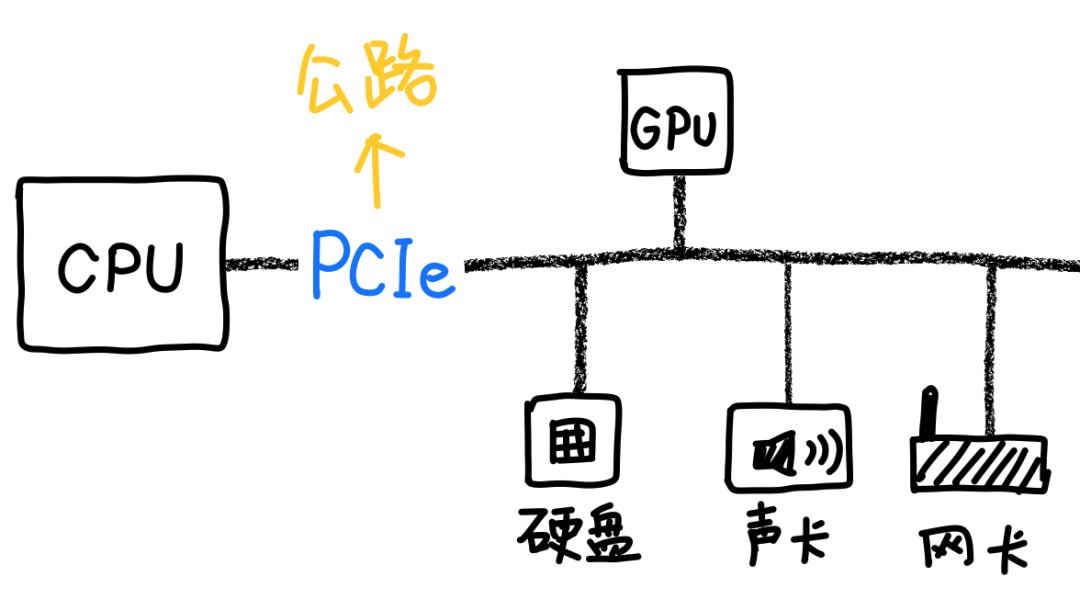
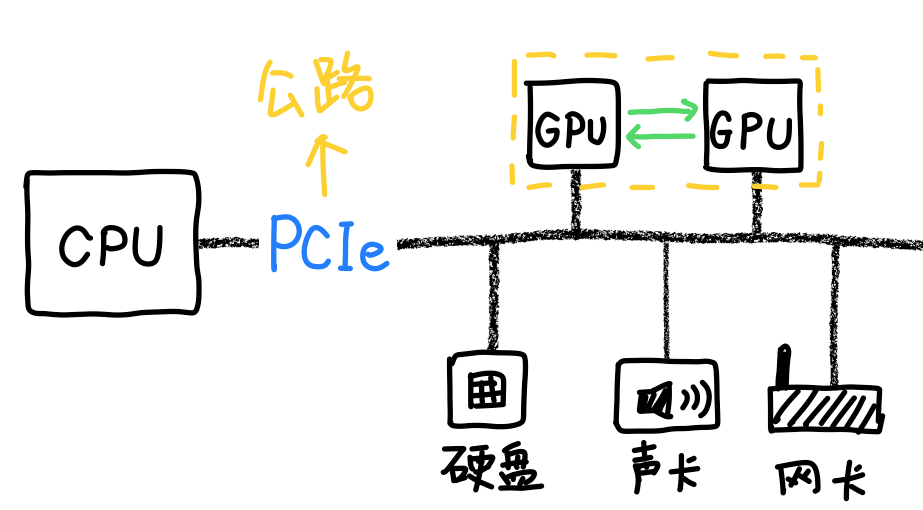
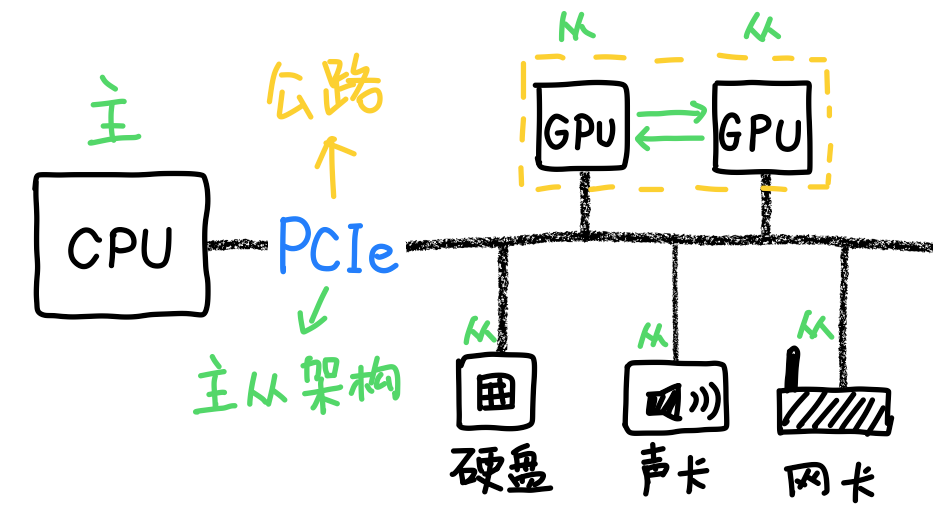
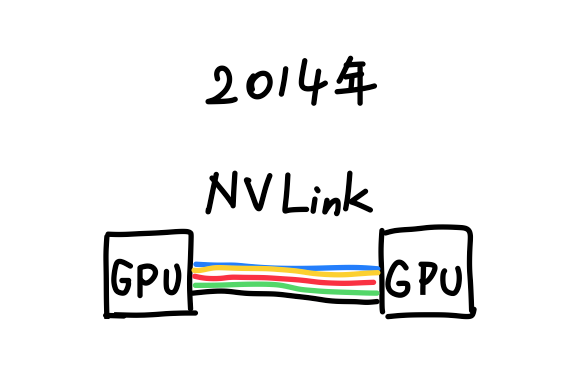
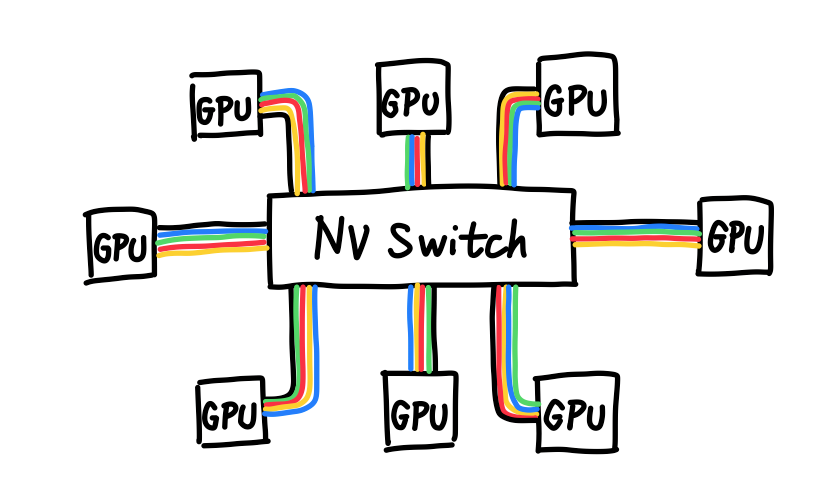

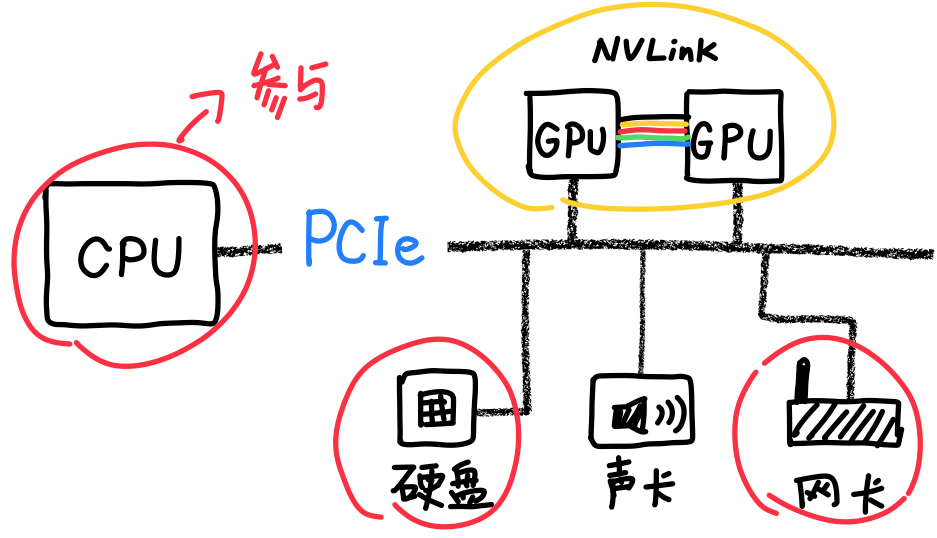
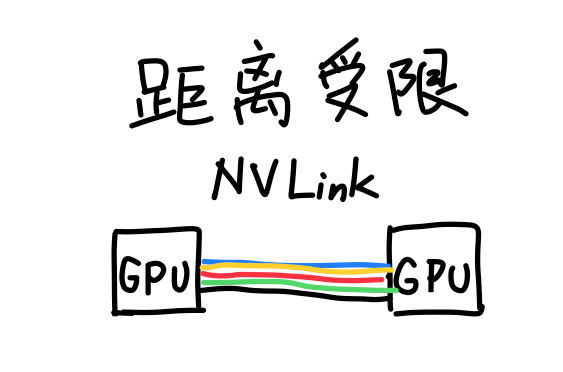
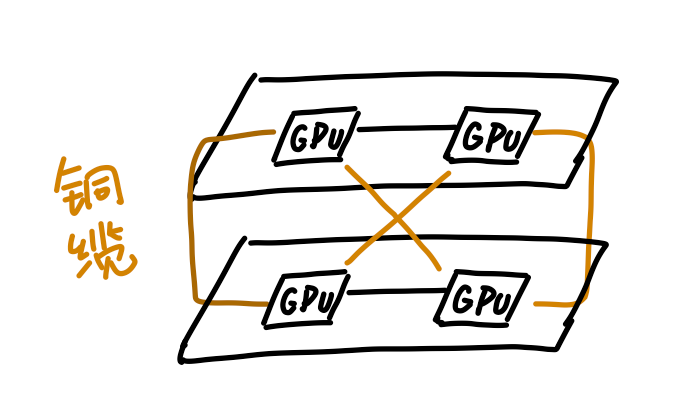


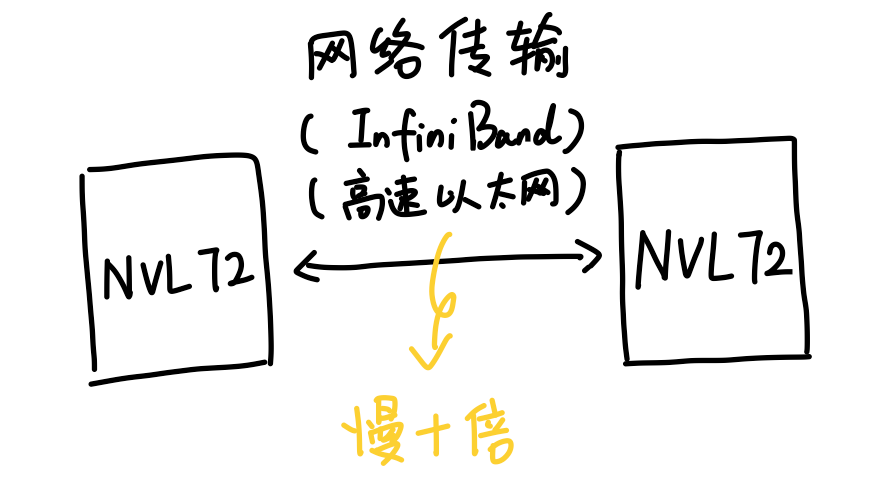




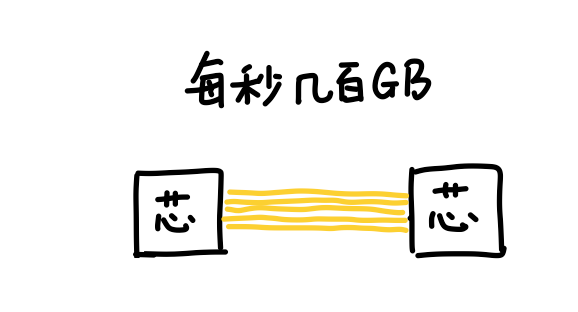

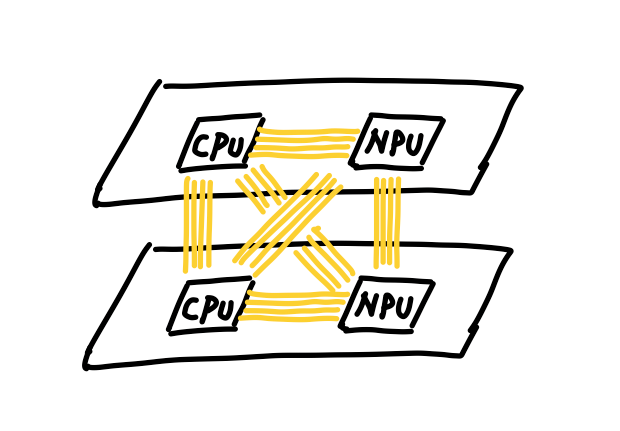

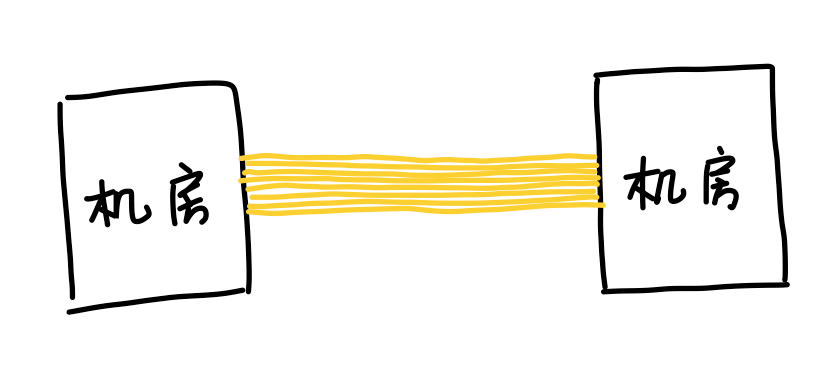


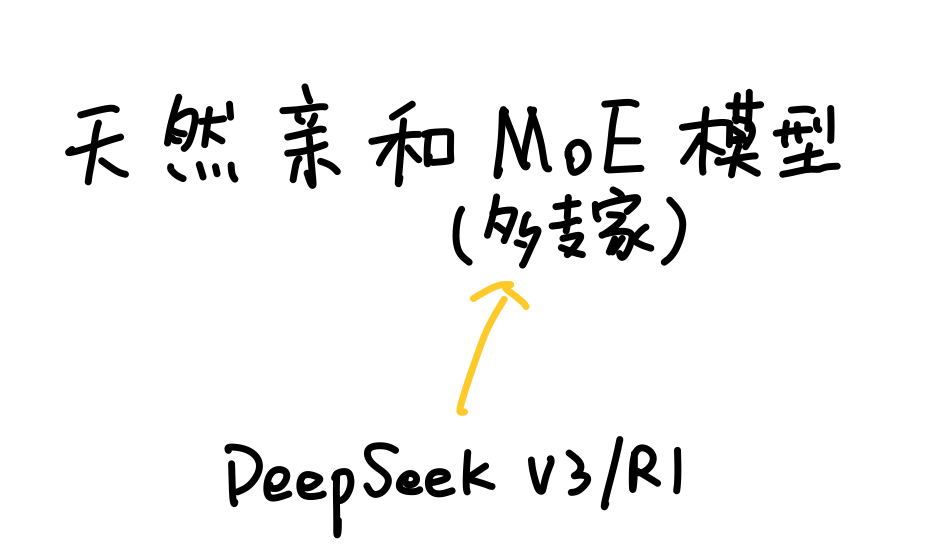
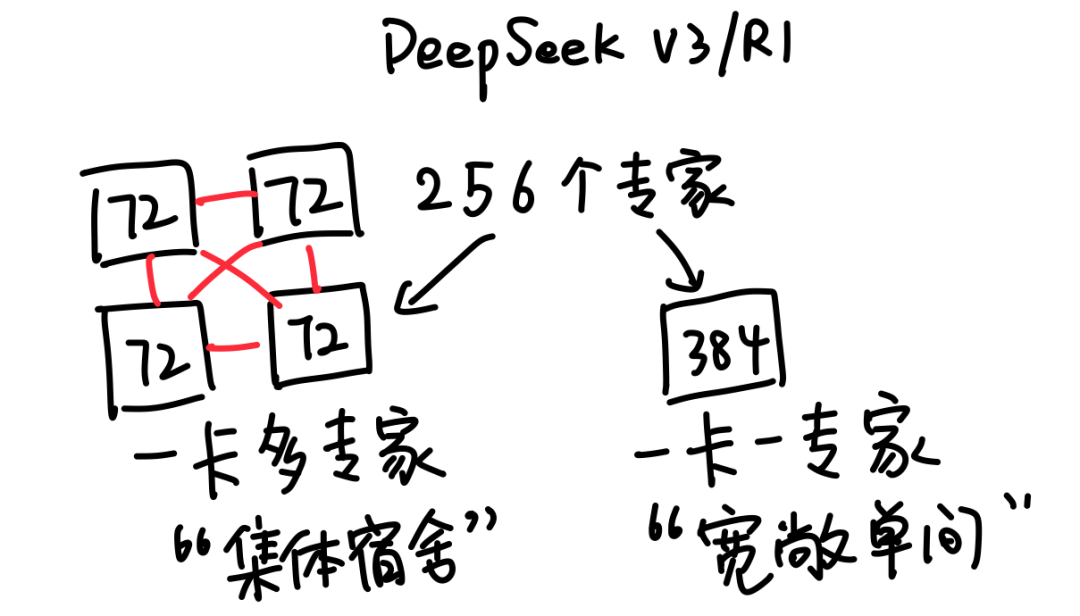





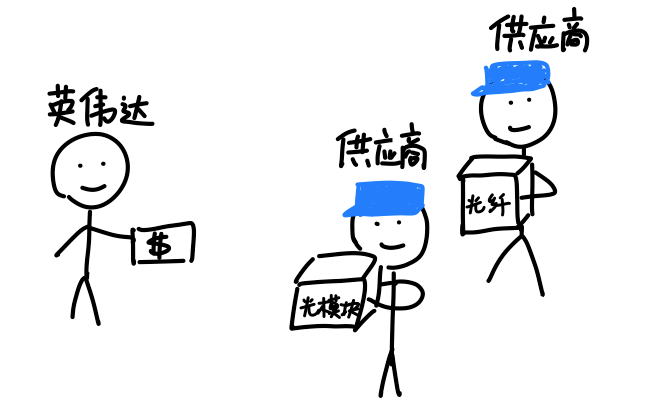
所以英伟达最终决定退而求其次,继续用铜缆。

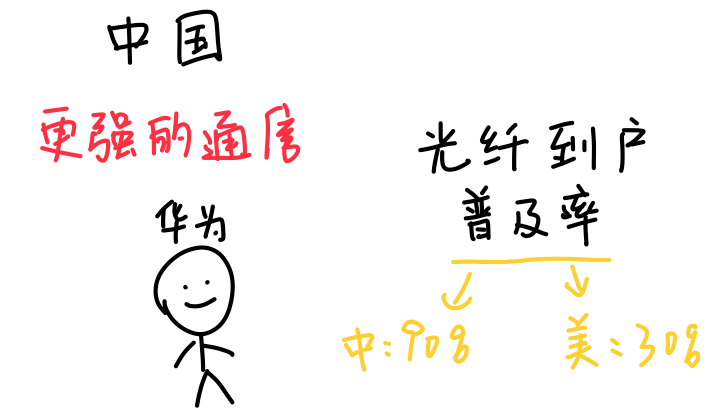
而华为表示:光通信,这个我可太熟了!

华为本来就是做通信出身,九十年代就在做网络交换机,2000年前后华为的光通信技术就已经做到国际领先。

如果把华为做过的光通信总距离连起来,估计都能绕地球十几圈了,这得积累多少经验和技术呢。

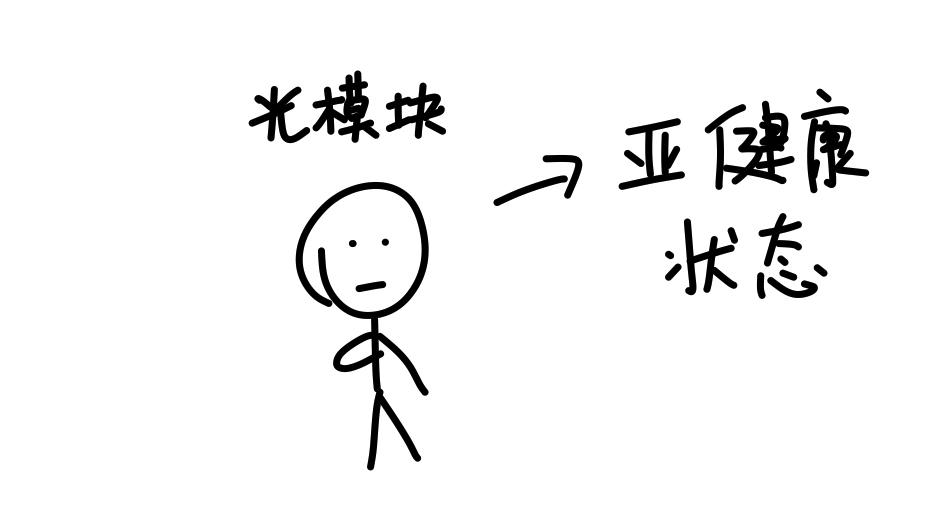


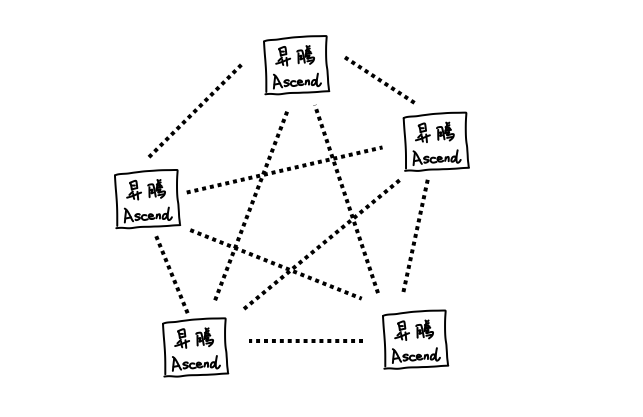
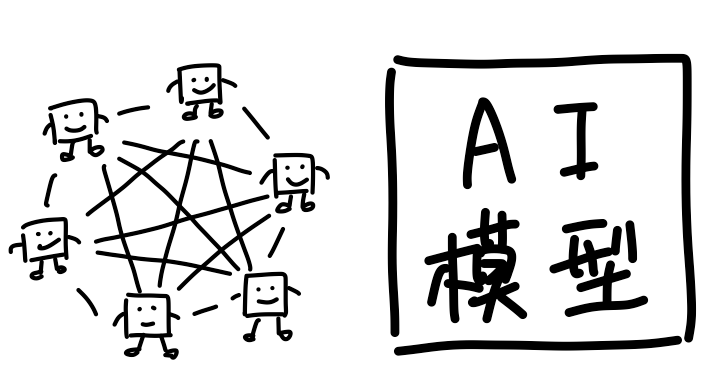
所以光通信,尤其是所有芯片之间都用光通信的方案,对英伟达是一匹烈马,但对于华为来说就刚刚好,过去积累的经验和能力正好用上。


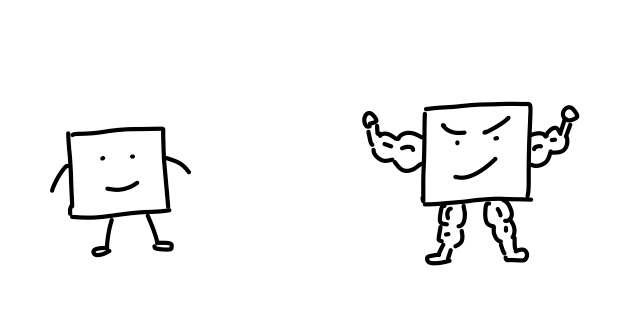
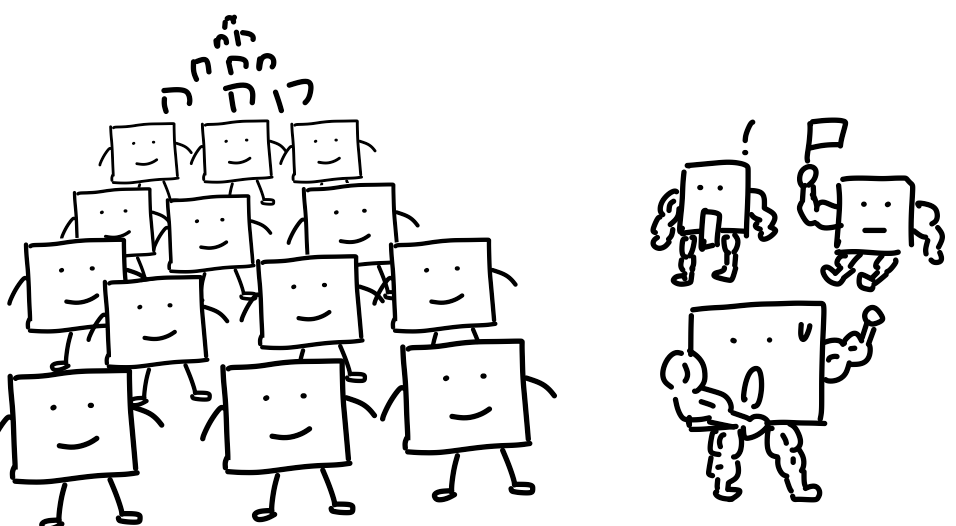
所以回过头来你就会发现,英伟达靠的是更强的单卡,把算力尽量压缩到更小的空间里,而华为靠的是更强的通信,把卡的数量规模堆得更大。
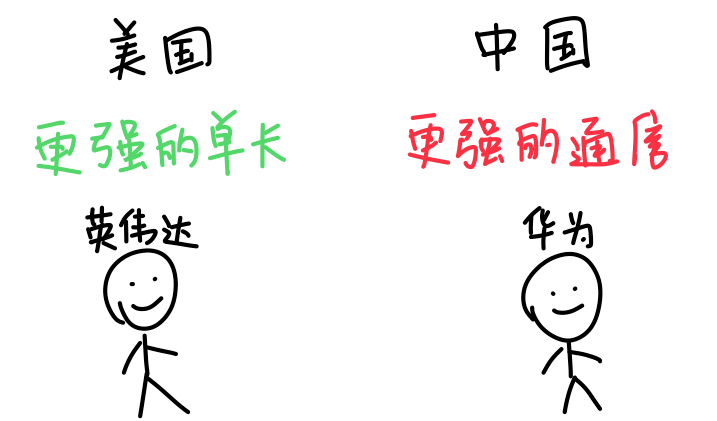
这两条路线,我觉得跟中美两国的产业土壤差异有关。英伟达超强的单卡能力,最早是被美国的3D游戏和图像计算产业给卷出来的。

—收工—
Advertisements
喜欢gonewithsmoke朋友的这个帖子的话,👍 请点这里投票,"赞" 助支持!
帖子内容是网友自行贴上分享,如果您认为其中内容违规或者侵犯了您的权益,请与我们联系,我们核实后会第一时间删除。
打开微信,扫一扫[Scan QR Code]
进入内容页点击屏幕右上分享按钮
楼主本月热帖推荐:
>>>查看更多帖主社区动态...