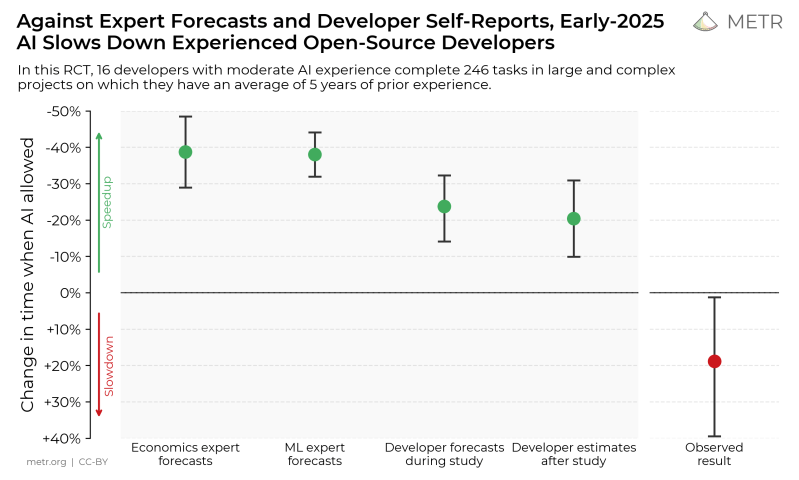
Recently AI risk and benefit evaluation company METR ran a randomized control test (RCT) on a gaggle of experienced open source developers to gain objective data on how the use of LLMs affects their productivity. Their findings were that using LLM-based tools like Cursor Pro with Claude 3.5/3.7 Sonnet reduced productivity by about 19%, with the full study by [Joel Becker] et al. available as PDF.
This study was also intended to establish a methodology to assess the impact from introducing LLM-based tools in software development. In the RCT, 16 experienced open source software developers were given 246 tasks, after which their effective performance was evaluated.
A large focus of the methodology was on creating realistic scenarios instead of using canned benchmarks. This included adding features to code, bug fixes and refactoring, much as they would do in the work on their respective open source projects. The observed increase in the time it took to complete tasks with the LLM’s assistance was found to be likely due to a range of factors, including over-optimism about the LLM tool capabilities, LLMs interfering with existing knowledge on the codebase, poor LLM performance on large codebases, low reliability of the generated code and the LLM doing very poorly on using tacit knowledge and context.
Although METR suggests that this poor showing may improve over time, it seems fair to argue whether LLM coding tools are at all a useful coding partner.















Sounds very similar to research on productivity through adderall. Everyone thinks they are enhancing performance, and indeed they are furiously doing something, but it’s tweaker brain. You’re cleaning your bathroom grout with a toothbrush, which seems like you’re really getting something done… but it sure is a lot slower than just cleaning the bathroom like a normal human being and not a guy on meth.
I have bipolar, and I can tell you that you seem to get a lot done efficiently during a mania, but it’s seldom true. A very mild mania can get you off your butt and working, but anything after that goes about as well as this LLM/Coding study.
Also see: Ballmer Peak
“a programmer who is appropriately intoxicated (between 0.129-0.138% BAC) will achieve a high level of programming productivity”
Obligatory XKCD
https://xkcd.com/323/
For me, the difference between AI and BP is that I know BP works. It just takes lots of training to stay on the peak.
That was the first thing I thought of, with the “people were 19% less productive, even when they thought they were 21% MORe productive.
iir, adderall functions by replacing missing reward chemicals in people whose brains are missing them, helping them to keep focused on doing what they’re doing. give them to someone with normal brain chemistry and they figure they’re getting so much done because their brain is swimming in reward chemicals, whether they get anything done or not.
Although the neurotransmitter involved isn’t the reward chemical, but the “pay attention” chemical – dopamine. When you’re doing something rewarding, dopamine gets released to say to the brain “this is important, keep doing this.”. It used to be believed that dopamine was the reward chemical, but that’s an easy mistake to make.
That’s how adderall works – it focuses your attention instead of just providing reward (euphoria, pleasure), although the drug itself does cause both.
As far as I know, the “missing chemicals” theory of mechanism has been discredited for at least three decades, but for some curious reason it is still very often pushed at point of diagnosis. The official explanation now is that the mechanism is unknown but they accidentally found a drug that helps despite having a completely wrong theory of its operation. A very lucky coincidence.
Makes some sense because “amphetamine salts” were never a reward chemical in the brain. They are very addictive, though.
Not entirely, and you clearly missed the chemistry involved. They aren’t “missing” but either supplied insufficiently or the patients’ neurology is desensitised. I’m effect it does work as advertised, but everyone is slightly different so effectiveness and actual outcomes vary a lot.
Obviously someone who shouldn’t be on it will be affected differently, often negatively, but if the dose is correct you just feel mildly more awake and functional.
Adderall itself isn’t great for this, even if formulated to metabolize more slowly. It goes through your system too fast, making people do need higher doses crash out, and it’s addictive, and you should not take it every day. Unfortunately it’s often the only thing available that’s effective at all.
Note: Some, like myself, suffer next to zero side effects or withdrawal symptoms. I can (and have) taken these medications and gone to sleep.
Or the classic usability studies done in the 80’s about CLI vs. GUI. People using the command line reported more efficiency, but people using GUI displayed more actual productivity in most tasks.
Turns out people judge effort and effect to be interchangeable because the perceived value of the outcome is inflated by the work and time it took to get there. Fiddling around with the LLM feels like you’re doing a lot, because you are – it’s just that your work is contributing less to the outcome and more to chaperoning the LLM.
Also known as the IKEA effect.
The value proposition is that the LLM’s work output is additive to your work output, so working in tandem increases productivity, but that isn’t exactly what happens.
While the LLM is fast, much of its work output has to be rejected. It has low efficiency and low added value. If it was just that, the outcome would still be positive, but with the reduction in your personal efficiency to chaperone the LLM, the final sum is more negative than positive.
IF the LLM can be made more competent, less hallucinating, requiring less supervision etc. then the equation might turn out positive again, but as the results show this is not yet the case.
Depends, I think.
A DOS-based word processor that has optional mouse/lightpen support
but otherwise works just fine with keyboard shortcuts can be less distracting and enhance imagination.:
It’s just you and the word processor. No GUI, no mouse.
Just you and the flickering CRT monitor that stares into your sole.
That’s why some of us still use WordStar, MS-DOS Editor or Norton Commander.
The mood or atmosphere is a whole different to modern computing.
You’re “one” with your PC when you’re on plain DOS.
Just you and the 70Hz VGA text-mode or your green/amber Hercules monitor with afterglow.
In that case, I’d say you better take your feet off the table and start working.
What a nice word play!
Those studies didn’t apply generally then fyi, and definitely don’t today. There are far too many variables and differences in both workflow and outcomes to consider. Certain tasks are significantly more productive in one or the other, but often small changes can reverse that.
Otherwise, yes, “sunk cost” in work is a very real bias.
Not only sunk cost, but people perceive things like time spent on a task differently depending on whether they’re doing a bunch of small operations or one sustained action.
Typing on the keyboard makes you feel like you’re achieving things at a faster rate than you actually are because you’re performing a bunch of tiny actions repeatedly and rapidly.
You lose track of the actual time you’ve spent on the task because you intuitively use the small operation as your timing reference, and you don’t remember how many of them you’ve performed; how many times you had a typo, a syntax error, or other mistake… how many times you had to stop and look it up on google… etc.
As someone with clinically-diagnosed ADHD, I can say that my meds (not Adderall but still a stimulant) really do enhance my productivity to a level equivalent or greater than someone without. Though, it’s a completely different story for someone with a more typical brain chemistry. 😉
Tell us you’ve never used Adderall to code without telling us you’ve never used Adderall to code.
My experience is very much the opposite from what you suggest. But as with everything, YMMV.
Adderall is far, far different than “tweaking”. I know, because I’ve done both. I doubt you have.
Wow! This is my shocked face.
Is it really a surprise ? A lot of the hype about being an augmented dev involves switching from one miracle tool to another : windsurf, copilot, cursor, you name it. But how one can master its use when FOMO about the next best thing is more tna ever around ?
Not to mention it’s a “miracle” that has only been in existence for so little time that is impossible to actually evaluate for genuine gains in productivity.
Not to mention that most companies don’t have apposite metrics for productivity in the first place. They don’t know what their people are really doing, and neither do the workers themselves.
https://www.upwork.com/research/ai-enhanced-work-models
“Nearly half (47%) of workers using AI say they have no idea how to achieve the productivity gains their employers expect. Over three in four (77%) say AI tools have decreased their productivity and added to their workload in at least one way. For example, survey respondents reported that they’re spending more time reviewing or moderating AI-generated content (39%), invest more time learning to use these tools (23%), and are now being asked to do more work (21%). Forty percent of employees feel their company is asking too much of them when it comes to AI.”
Remember, hundreds of billions of dollars have been sunk into AI. We’re FAR beyond the point where “promising results” would be good enough, and in fact the results aren’t even promising.
I get that people want to be optimistic, but this gigafraud is literally endangering the global economy. And even if it were real, the best-case scenario is that it destroys everyone’s job. I would say, find a different future to hope for.
And literally damaging the global climate with it’s ever increasing energy requirements and constant churn of tech.
The sooner this bubble bursts and people see it for the scam it is the better.
I normally keep these types of opinions to myself but, it’s a complicated situation worth exploding the nuance.
AI in the form of LLMs has a few use cases too tantalizing to for the economy not to freak out about. They make great weapons(most use cases aren’t talked about yet), world class propaganda at tremendous scale, wonderful for surveillance, excellent for social media “crowd control”, they are okay at search but the idea of a chat interface is still somewhat flawed, and maybe just maybe they devalue the cost of a variety of employees. Keep in mind lowering the value of something does not require actual results, it’s about what people are willing to pay or what they think they should pay.
In the future this may change but the current LLM approach seems more or less like a mistake Regardless those things are great for a few classes/types of people and generally speaking none of us nor the people we interact with daily are those people.
Oh they also create copyright loopholes. Possibly patent theft defenses as well.
I’d like to slam LLMs for copyright, but then I don’t exactly believe in the justifications of modern copyright in the first place.
In fact, LLMs and diffusion models etc. are a perfect example of why copyrights and the IP ownership model and royalties/licenses are flawed. It’s not just LLMs that copy – people can copy, and do.
The fundamental reason we pay authors is for their creative labor and ideas, not for the creations themselves. We pay to make something which does not yet exist, which can only come about by human invention. Yes – even the use of an LLM to create something new requires a human in the loop to define and guide the outcome. Otherwise the chances of AI to come up with something actually novel would be on the same order as a million monkeys typing out Shakespeare.
That which does exist is trivially copied and paying people royalties for it is just an artificial restriction on information that allows copyright holders to extract unearned income. There is the argument of copyrights to shield authors from instantly being replaced by their copies, but that barely holds when the actual authors do not hold the copyrights in the first place (e.g. “work for hire”).
Mind: “unearned income” refers to the way you make money, not whether you deserve that money.
The copyright system is based on the idea that if you can’t earn income from your work, you’re permitted to extract the income otherwise – by monopoly and artificial scarcity.
The premise is flawed in the sense that you can earn your income from work. It’s just that artificial scarcity can earn you a lot more money because it’s not limited by the work you actually do, or any notion of “fair compensation”. In fact, when copyright first came about, it was not the authors and artists who argued for it, but the book printers who wanted monopolies on the titles they were printing, because they knew that if authors were granted copyrights then those copyrights could be written away by contract to them.
I’m amazed. If you make an experienced developer mentor an idiot, of course productivity increases (2x the manpower). Why wouldn’t the same be true of ai?
You’ve never mentored anyone have you,
Spit out my drink at that reply…
Not to mention that LLMs don’t exactly learn from their mistakes. You can only bias them towards the correct answers (akin to teaching the new recruit), but the fundamental process is still random and will produce bugs and errors from time to time.
https://en.wikipedia.org/wiki/The_Mythical_Man-Month
What are you talking about? LLMs don’t learn, you have to be the one that learns how to shape it’s output to what you need, if you even can. If there an update you may have to start over. A human junior that is capable of doing the job might start out utterly incompetent, but will learn how to do the job.
Interesting caveats in section 4.1 Especially the third one, that implies that are working on another paper with improved and autonomous AI agents, and that the field is making rapid progress.
In other words, this is not the end of the discussion and development. We’re still in the baby years of AI.
I’m really curious about where this goes when the developers do meta-development, setting outside AI models on improving the coding agent models, perhaps circularly. Are the agents able to bootstrap themselves, or are there inherent limitations to the AI models that we aren’t seeing. Maybe something like Table 1, C 1.3, where it sounds like scaling issues.
Just keep in mind none of this is AI yet. And these systems that are being worked on are little better than statistical search engines. These will always have problems providing autonomous functions, in many cases more than far simpler approaches.
“doing very poorly on using tactic”.
LLM translation/generation, maybe ? or general deterioration of language skills in humans exposed to the Big Bad Internet, even before LLMs took hold ?
I myself prefer tictac. MMMMmmm, sweets.
Read again. It’s tacit.
yes, after the edit is now makes sense.
Improving productivity is an old quest, 4GL languages, UML modeling… tried to do so for decades. None of them succeeded. Now LLM comes with the promise of doing better without any underlying model nor process (LLM models are not true models, just a bunch of prediction parameters)
That study shows is clearly, IA/LLM is just another flavor of marketing bullshit on a very difficult problem no one was ever able to resolve. The end result is a new solution worse than previous ones in most cases
I think an explanation might be that it was on large, complex tasks. This is what LLMs are worst at. I have found them useful for writing small functions, and for translating English into regular expressions. When you have it write something large and complex, you will spend a lot of time figuring out the various semi-arbitrary structural choices it made, which I suspect absorbs a lot of time but might seem subjectively easier than making the choices. Add in one or two bugs you have to fix, and it could easily eliminate any improvement in efficiency you’d have seen.
So what you’re saying is that LLMs can be used by breaking the task into smaller parts with the human programmer deciding the overall layout, much like older ideas of using program design methods such as SA/SD using test cases and other methods to ensure it works.
That’s old hat stuff. The issue is that defining the work to be done takes about as long as doing the work itself if not more. When the problem is suitably constrained, writing the actual code is rather trivial.
The developers were free to use AI as they would/saw fit. If it works best at small functions — they could do that, just use it for the small bits/bits it does well, and do the rest without AI.
Where is the experimental evidence which shows what bits AI does well at, actually provides speedup?
Where is the guidance/tools that tell you, based on evidence, when to use AI and when not?
Only if we can hold everything else (amount of bug reports, amount of fixes, quality of code, financial conditions outside of programming, customer/user satisfaction, bonuses for board/shareholders, etc.) constant.
The layoffs could indicate productivity losses (need to offset AI costs, increasing tech debt in code base). Have to show cost reduction to board/stockholders; one way to reduce costs is fire workers.
Love that they did this study.
That said, what about the non-experts working on non-complex programming items? I’ve produced several standalone work artifacts that if I had to learn the underlying skills, would have taken hours, or weeks (example: chrome add-in to reformat a vendor website in my view)
just because LLMs don’t increase productivity at one end of the bell curve, doesn’t mean it can’t/isn’t helping move the folks at the bottom of the curve!
From an educational standpoint, there’s also studies that show using LLMs results in worse learning outcomes. People were put to write papers about a subject and couldn’t remember what they wrote or explain the concepts they were talking about in the paper, while those who did it the old fashioned way had near perfect retention on both cases.
So yes, it helps if you just need to get something that is above your skill level done, but it doesn’t help you develop professionally.
Offloading thought is a serious problem as it is in education, critical thinking and how to do research and complete results are non-trivial tasks that require training and effort to develop.
The danger here is that management is always trying to squeeze blood from a stone.
They’ll give you tasks that are above your competence and pay grade, and a deadline that doesn’t permit adequate research, and they won’t take no for an answer. If you cave in and use some LLM tool to “solve” the issue, the management only sees that the task was completed and makes even harder demands next time.
So your problem as a software developer then is, can you live up to the expectations you’ve set? Did you actually gain any competence from the last task, so you’re ready for what’s coming up next?
Fyi, if you are a non-expert, you should been even more wary. You don’t know what you don’t know. An experienced programmer can fix entire classes of problems by telling the system not to use certain types of functions, a layperson won’t be able to, nor will they be able to tell what’s wrong if it compiles but still fails.
TLDR; have it demonstrate, then error the code yourself, you need the practice.
I believe the list of factors is very accurate because I myself got trapped by most of them over the past three weeks while developing a personal app to access an AI engine API.
However, I don’t believe the problem lies with the LLM itself, but with our expectations and assumptions about it. Once I better understood what I was doing wrong, I was able to use the tool’s capabilities to do a much better job.
After my “self-training” on how to use the tool more efficiently, my productivity spiked, and I was able to finish my project quickly and effectively.
In short, I would say: just because you’re a software developer doesn’t mean you know how to use an LLM tool efficiently.
So you don’t write software for a living yet you are making conclusions like you do.
I am a software developer and it take far longer to figure out what an LLM is trying and failing to do, fix the crap structure, and everything else than to just write the code myself the first time.
It doesn’t matter what the LLM “tool” is.
That’s weird. Because I am a software developer and have been for 35 years.
LLMs are very useful when use effectively.
lt seems that a couple of decades of experience can make some difference, right?
Which is a truism.
“Under appropriate conditions, the sun rises.”
And they are such a poor tool when used without experience that calling them a hazard isn’t unwarranted.
Is there any tool in the hands of the inexperienced that isn’t a hazard?
Just FYI: I have 35 years of experience in software development and I’ve been using AI tools for a while. Btw, your argument is one more proof about how many software developers have a hard time to learn anything as they think they know everything “by default”.
Did you fed to Ai a code sample to prevent hallucinations? AI JUST work on a IDE which haven’t showing for people. To make Ai work correct you must RAG or fine turning before using in specific task .
It s extremely productive.
It called a prompt architecture, it clearly a pattern design at sophisticated level .but it require bottom up approach that mean a user must understand the software design before it to tell Ai do something
And these means a junior should not be using it Detroit oversight.
But then you won’t be, because you’re having to do all this work instead of working on the actual problem, and the project is waiting for you to finish tuning the LLM to get it to work on the actual code.
See Amdahl’s law: “the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used.”
Additional rule: “If the work of optimizing the single part of a system is included in the performance evaluation, the overall performance improvement may turn out negative.”
Yes but most of task in engineer already solved in most scenario. I mean to scale up a website or a sever or engine is not as hard as like do it before Ai released.
In further , profit by scale will apply Ai as new feature. It cost less than hiring a engineer team to maintain or update.
I did it on C and java- a high level language it work well , except when I step into language dev . AI can’t do that part .which mean it require engineer skill more than Ai skill . But I think In application and consumption topic the picture will be different.
And micro language surgeon not a common thing to emphasize something represent for general picture.
I would not let an LLM replace an engineering team in mass deployment or feature updates. That’s a recipe for disaster.
I mean, given a well defined problem and suitable priming for the task, an LLM will probably be able to count 1 + 1 = 2 correctly, but sometimes it just won’t.
More precisely, the LLM is not deterministic in its output and it cannot check itself for error, so you can’t guarantee that it does the job correctly.
https://blog.promptlayer.com/temperature-setting-in-llms/
“While a temperature of 0 aims for deterministic outputs, where the LLM consistently selects the word with the highest probability, there might still be slight variations in the generated text. This is because LLMs are not run in a vacuum, and factors like race conditions in the model’s execution environment can introduce subtle randomness, even at a temperature of 0. “
Also forgot to mention that the output of an LLM is chaotic, because it uses its own output to predict the next line, so the effects of small differences accumulate.
A small error leads to a big error, which is why the LLM response length is usually limited. If left to continue indefinitely, it would break down into incoherent babble every time.
I have a mix opinion about AI assistant(s) for coding. On one hand, it helped me a lot in automatically looking through a big (and somehow evolved thru several years) codebase and update the abandoned swagger definition file to make our application compliant with some of the company’s policies. On the other hand I spent almost a day tweaking the output of the AI agent when I asked to add unit tests/improve code coverage for some new features added to the current application.
So in the first action I was really impressed by all the (tedious) work it saved me; however the second action impressed me as well by how much effort it took me to finish my assignment, even with the AI buddy “helping”
People who don’t have any clue about how Ai coding will release a slow effort code while other can make a website with Ai’s code on X .
The engine which help Ai can generate a code belong to a IDE which have been seen in a lot of normal IDE like visual code .that mean Ai just simply tokenize our prompt to numerical,then it must fed the token to a natural network, with the network must be train on a specific platform API/SDK/Text/similar text or binary.
So to increase productivity in coding, a user must understand how tokenization work and how mapping behavior which means ridiculously,it s not open source or not document well . The document provide a design of a service/module that you are work with, and without it, a programmer are swimming in code pool was made of to handle flexible format .
The core of algorithm is quite simple, like in 3D shape . however information processing (under the hood) and UI/Ux creating a ton a code that make no sense in logic . And drowning into that without a map(document) is not a great idea.
Here is my POV when using Ai for coding.first I must pick a libs needed for a project,then system pattern,then algorithm, then IDE.
My prompt will force Ai must think using the information that I provided. And to make Ai generate a correct code , I fed to It 200k lines code base from the library :)) . It called RAG
Actually I believe a fine turning or deep learning could do the same results but I don’t have time . In market money is everything
Lay-off in great coorps that switched to AI is a better indication of productivity gains than this study.
People wanting to keep their jobs show they are less productive with technology that would take their jobs. Who would have thought.
I’ll sum up my experience with AI:
“A broken clock is right twice a day”
AI tells me the wrong “time” so often that I have to keep looking at my “watch” no matter what “time” it tells me, when I could have just looked at my “watch”.
“I have 8 bosses, Bob. 8 bosses??? Yes 8 bosses” What this whole research project seemed to conclude is that adding more heads to the Hydra makes things harder. Golf clap. The more things with a fake brain that try to help are just two more people turning a solo project into a group project and more things you end up arguing with and having to coax. OMG two drunk babies are harder to deal with instead of one drunk baby??! Unless you are a psychopath or bipolar, these things dont actually help. Hope it was a grant that ran out lol.
Thanks for this. I’m a recently retired SWE who has taken on a “give back” project: reengineering a 25-year old education app in a web framework. Thought it would be a perfect setting to get hands-on with AI. Well I’m maybe 50 kloc in, working mainly with Copilot but also some others. I’m sure I spend more time checking (and usually finding problems to fix in) the AI’s work than I would doing it myself. Thought it was me.