07 Cleaning Your Dirty Data
0 likes173 views

<강의안> Web Scraping with Python (Chapter 07. Cleaning Your Dirty Data) 내용을 참고하여, n-gram이 무엇이고, 크롤링한 글을 어떻게 깔끔하게 처리하고, 정규화하는지를 예제로 설명합니다.



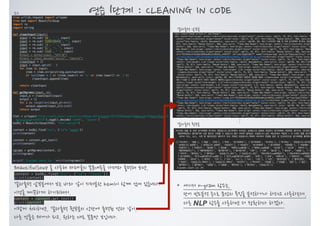
![연습 1단계 : CLEANING IN CODE
cleanInput 함수를 보면,
re.sub의 parameter로,
'[[0-9]*]'
나
' +'
을 볼 수 있는데,
이를 정규표현식이라고 합니다.
간단히 반복 패턴을 처리하는 * 와 + 만 살펴보겠습니다.
*는 0번 이상 반복되면 매칭 되었다고 판단!
+는 1번 이상 반복되면 매칭 되었다고 판단!
예를들어, 정규식 ‘ta*b’와 ‘ta+b’의 다른 점
정규식이 ‘ta*b’ 이라면,
문자열에 tb 가 있으면 매칭되었다고 판단합니다. t와 b
사이에 a가 0번 반복되었기 때문입니다.
그러나 ‘ta+b’ 라면, tb는 매칭이 되지 않았다고 판단
합니다. a가 1번이상 반복되지 않았기 때문입니다.
나머지 tab, taab, taaaab등은 모두 매칭된 것으로 판단
하겠지요.
이 정규표현에 대해서는 아래 링크에 들어가 보시면,
더 많은 정보를 상세하게 확인 할 수 있습니다.
https://docs.python.org/3.6/library/re.html?highlight=regular](https://image.slidesharecdn.com/webscrapingwithpythonchap07-170601045703/85/07-Cleaning-Your-Dirty-Data-5-320.jpg)
![연습 1단계 : CLEANING IN CODE
cleanInput 함수를 보면,
re.sub의 parameter로,
'[[0-9]*]'
나
' +'
을 볼 수 있는데,
이를 정규표현식이라고 합니다.
이 예제 소스에서는 이와 같은 함수를 써서,
input = re.sub('[[0-9]*]', "", input)
[와] 사이에 숫자가 0번이상 반복되면, 지워버려라 하는 것이고,
input = re.sub(' +', " ", input)
공백(스페이스)가 1번이상 반복되면, 공백 한번으로만 바꿔라 하는 것이다.
‘[‘와 ‘]’사이에 숫자가 0번 이상 반복되면 매칭 판단
공백(스페이스)이 1번 이상 반복되면 매칭 판단](https://image.slidesharecdn.com/webscrapingwithpythonchap07-170601045703/85/07-Cleaning-Your-Dirty-Data-6-320.jpg)
![연습 2단계 : DATA NORMALIZATION
단어 빈도수 분석을 하려면 ....
결과출력소스
이번 소스는 다른 부분은 모두 같고,
getNgram 함수만 수정하여 출력해 본 것이다.
우리는 bi-gram 을 사용하므로, 이렇게 수정한다면,
2개로 조합된 문구의 빈도가 얼마나 많은지를 체크하는 것이다.
결과출력이 모두 1로 나와서 실망하지는 마시라.
NLP 함수를 쓰거나, 좀 더 긴 글을 사용하면, 확연히 차이나는 결과를 볼 것이다.
지금은 이런 방식으로 data를 cleaning하는 기법을 연습하는데 만족하자.
from collections import OrderedDict
...
ngrams = getNgrams(content, 2)
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
print(ngrams)
...
그리고, 이런 식으로 OrderedDict 를 사용하여 소스를 수정하면,
단어의 빈도가 높은 순서로 출력되도록 할 수 있다.](https://image.slidesharecdn.com/webscrapingwithpythonchap07-170601045703/85/07-Cleaning-Your-Dirty-Data-7-320.jpg)





















More Related Content
More from Young Oh Jeong (12)
07 Cleaning Your Dirty Data
- 1. Web Scraping with Python Chapter 07. CleaningYour Dirty Data SweetK Ryan Jeong
- 2. WHAT IS N-GRAM Field Unit Sample sequence 1-gram sequence 2-gram sequence 3-gram sequence Vernacular name - - unigram bigram trigram Order of resulting Markov model - - 0 1 2 Protein sequencing amino acid … Cys-Gly-Leu-Ser-Trp … …, Cys, Gly, Leu, Ser, Trp, … …, Cys-Gly, Gly-Leu, Leu-Ser, Ser- Trp, … …, Cys-Gly-Leu, Gly-Leu-Ser, Leu-Ser-Trp, … DNA sequencing base pair …AGCTTCGA… …, A, G, C, T, T, C, G, A, … …, AG, GC, CT, TT, TC, CG, GA, … …, AGC, GCT, CTT, TTC, TCG, CGA, … Computational linguistics character …to_be_or_not_to_be… …, t, o, _, b, e, _, o, r, _, n, o, t, _, t, o, _, b, e, … …, to, o_, _b, be, e_, _o, or, r_, _n, no, ot, t_, _t, to, o_, _b, be, … …, to_, o_b, _be, be_, e_o, _or, or_, r_n, _no, not, ot_, t_t, _to, to_, o_b, _be, … Computational linguistics word … to be or not to be … …, to, be, or, not, to, be, … …, to be, be or, or not, not to, to be, … …, to be or, be or not, or not to, not to be, … 어떤 글에서 출현빈도 계산 및 공통점 추출 ↓ 자연어 처리, 언어인식, 색인방법론, 검색 등에 사용됨.
- 4. 연습 1단계 : CLEANING IN CODE 결과출력 앞부분 소스 BeautifulSoup 을 사용해 카페글의 본문내용을 가져와 출력해 보면, content = bsObj.find("div", {"id": "tbody"}) print(content) 결과출력 앞부분에서 보는 바와 같이 지저분한 html이 함께 섞여 있습니다. 이것을 깨끗하게 하기위해서, content = content.get_text() print(content) 이렇게 처리하면, 결과출력 뒷부분의 상단에 출력된 것과 같이, 다른 것들은 제거가 되고, 원하는 대로 본문만 보입니다. … 결과출력 뒷부분 * 여기서 n-gram 함수는, 단어 빈도분석 등으로 문장의 특징을 분석하거나 하려고 사용하는데, 다른 NLP 함수를 사용하면 더 정확하다 하겠다.
- 5. 연습 1단계 : CLEANING IN CODE cleanInput 함수를 보면, re.sub의 parameter로, '[[0-9]*]' 나 ' +' 을 볼 수 있는데, 이를 정규표현식이라고 합니다. 간단히 반복 패턴을 처리하는 * 와 + 만 살펴보겠습니다. *는 0번 이상 반복되면 매칭 되었다고 판단! +는 1번 이상 반복되면 매칭 되었다고 판단! 예를들어, 정규식 ‘ta*b’와 ‘ta+b’의 다른 점 정규식이 ‘ta*b’ 이라면, 문자열에 tb 가 있으면 매칭되었다고 판단합니다. t와 b 사이에 a가 0번 반복되었기 때문입니다. 그러나 ‘ta+b’ 라면, tb는 매칭이 되지 않았다고 판단 합니다. a가 1번이상 반복되지 않았기 때문입니다. 나머지 tab, taab, taaaab등은 모두 매칭된 것으로 판단 하겠지요. 이 정규표현에 대해서는 아래 링크에 들어가 보시면, 더 많은 정보를 상세하게 확인 할 수 있습니다. https://docs.python.org/3.6/library/re.html?highlight=regular
- 6. 연습 1단계 : CLEANING IN CODE cleanInput 함수를 보면, re.sub의 parameter로, '[[0-9]*]' 나 ' +' 을 볼 수 있는데, 이를 정규표현식이라고 합니다. 이 예제 소스에서는 이와 같은 함수를 써서, input = re.sub('[[0-9]*]', "", input) [와] 사이에 숫자가 0번이상 반복되면, 지워버려라 하는 것이고, input = re.sub(' +', " ", input) 공백(스페이스)가 1번이상 반복되면, 공백 한번으로만 바꿔라 하는 것이다. ‘[‘와 ‘]’사이에 숫자가 0번 이상 반복되면 매칭 판단 공백(스페이스)이 1번 이상 반복되면 매칭 판단
- 7. 연습 2단계 : DATA NORMALIZATION 단어 빈도수 분석을 하려면 .... 결과출력소스 이번 소스는 다른 부분은 모두 같고, getNgram 함수만 수정하여 출력해 본 것이다. 우리는 bi-gram 을 사용하므로, 이렇게 수정한다면, 2개로 조합된 문구의 빈도가 얼마나 많은지를 체크하는 것이다. 결과출력이 모두 1로 나와서 실망하지는 마시라. NLP 함수를 쓰거나, 좀 더 긴 글을 사용하면, 확연히 차이나는 결과를 볼 것이다. 지금은 이런 방식으로 data를 cleaning하는 기법을 연습하는데 만족하자. from collections import OrderedDict ... ngrams = getNgrams(content, 2) ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True)) print(ngrams) ... 그리고, 이런 식으로 OrderedDict 를 사용하여 소스를 수정하면, 단어의 빈도가 높은 순서로 출력되도록 할 수 있다.