Download as PDF, PPTX




















![WordCount – Cascading app in Java
String docPath = args[ 0 ];
String wcPath = args[ 1 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );
// specify a regex to split "document" text lines into token stream
Fields token = new Fields( "token" );
Fields text = new Fields( "text" );
RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ [](),.]" );
// only returns "token"
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );
// determine the word counts
Pipe wcPipe = new Pipe( "wc", docPipe );
wcPipe = new GroupBy( wcPipe, token );
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
.addSource( docPipe, docTap )
.addTailSink( wcPipe, wcTap );
// write a DOT file and run the flow
Flow wcFlow = flowConnector.connect( flowDef );
wcFlow.writeDOT( "dot/wc.dot" );
wcFlow.complete();
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-21-2048.jpg)
![mapreduce
Every('wc')[Count[decl:'count']]
Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']']
GroupBy('wc')[by:['token']]
Each('token')[RegexSplitGenerator[decl:'token'][args:1]]
Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']']
[head]
[tail]
[{2}:'token', 'count']
[{1}:'token']
[{2}:'doc_id', 'text']
[{2}:'doc_id', 'text']
wc[{1}:'token']
[{1}:'token']
[{2}:'token', 'count']
[{2}:'token', 'count']
[{1}:'token']
[{1}:'token']
WordCount – generated flow diagram
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-22-2048.jpg)
![(ns impatient.core
(:use [cascalog.api]
[cascalog.more-taps :only (hfs-delimited)])
(:require [clojure.string :as s]
[cascalog.ops :as c])
(:gen-class))
(defmapcatop split [line]
"reads in a line of string and splits it by regex"
(s/split line #"[[](),.)s]+"))
(defn -main [in out & args]
(?<- (hfs-delimited out)
[?word ?count]
((hfs-delimited in :skip-header? true) _ ?line)
(split ?line :> ?word)
(c/count ?count)))
; Paul Lam
; github.com/Quantisan/Impatient
WordCount – Cascalog / Clojure
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-23-2048.jpg)

![import com.twitter.scalding._
class WordCount(args : Args) extends Job(args) {
Tsv(args("doc"),
('doc_id, 'text),
skipHeader = true)
.read
.flatMap('text -> 'token) {
text : String => text.split("[ [](),.]")
}
.groupBy('token) { _.size('count) }
.write(Tsv(args("wc"), writeHeader = true))
}
WordCount – Scalding / Scala
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-25-2048.jpg)















![## train a RandomForest model
f <- as.formula("as.factor(label) ~ .")
fit <- randomForest(f, data_train, ntree=50)
## test the model on the holdout test set
print(fit$importance)
print(fit)
predicted <- predict(fit, data)
data$predicted <- predicted
confuse <- table(pred = predicted, true = data[,1])
print(confuse)
## export predicted labels to TSV
write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"),
quote=FALSE, sep="t", row.names=FALSE)
## export RF model to PMML
saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Pattern – create a model in R](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-41-2048.jpg)
![public static void main( String[] args ) throws RuntimeException {
String inputPath = args[ 0 ];
String classifyPath = args[ 1 ];
// set up the config properties
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap inputTap = new Hfs( new TextDelimited( true, "t" ), inputPath );
Tap classifyTap = new Hfs( new TextDelimited( true, "t" ), classifyPath );
// handle command line options
OptionParser optParser = new OptionParser();
optParser.accepts( "pmml" ).withRequiredArg();
OptionSet options = optParser.parse( args );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "classify" )
.addSource( "input", inputTap )
.addSink( "classify", classifyTap );
if( options.hasArgument( "pmml" ) ) {
String pmmlPath = (String) options.valuesOf( "pmml" ).get( 0 );
PMMLPlanner pmmlPlanner = new PMMLPlanner()
.setPMMLInput( new File( pmmlPath ) )
.retainOnlyActiveIncomingFields()
.setDefaultPredictedField( new Fields( "predict", Double.class ) ); // default value if missing from the model
flowDef.addAssemblyPlanner( pmmlPlanner );
}
// write a DOT file and run the flow
Flow classifyFlow = flowConnector.connect( flowDef );
classifyFlow.writeDOT( "dot/classify.dot" );
classifyFlow.complete();
}
Pattern – score a model, within an app](https://image.slidesharecdn.com/boulderbigdata-130925233202-phpapp01/75/Boulder-Denver-BigData-Cluster-Computing-with-Apache-Mesos-and-Cascading-42-2048.jpg)





























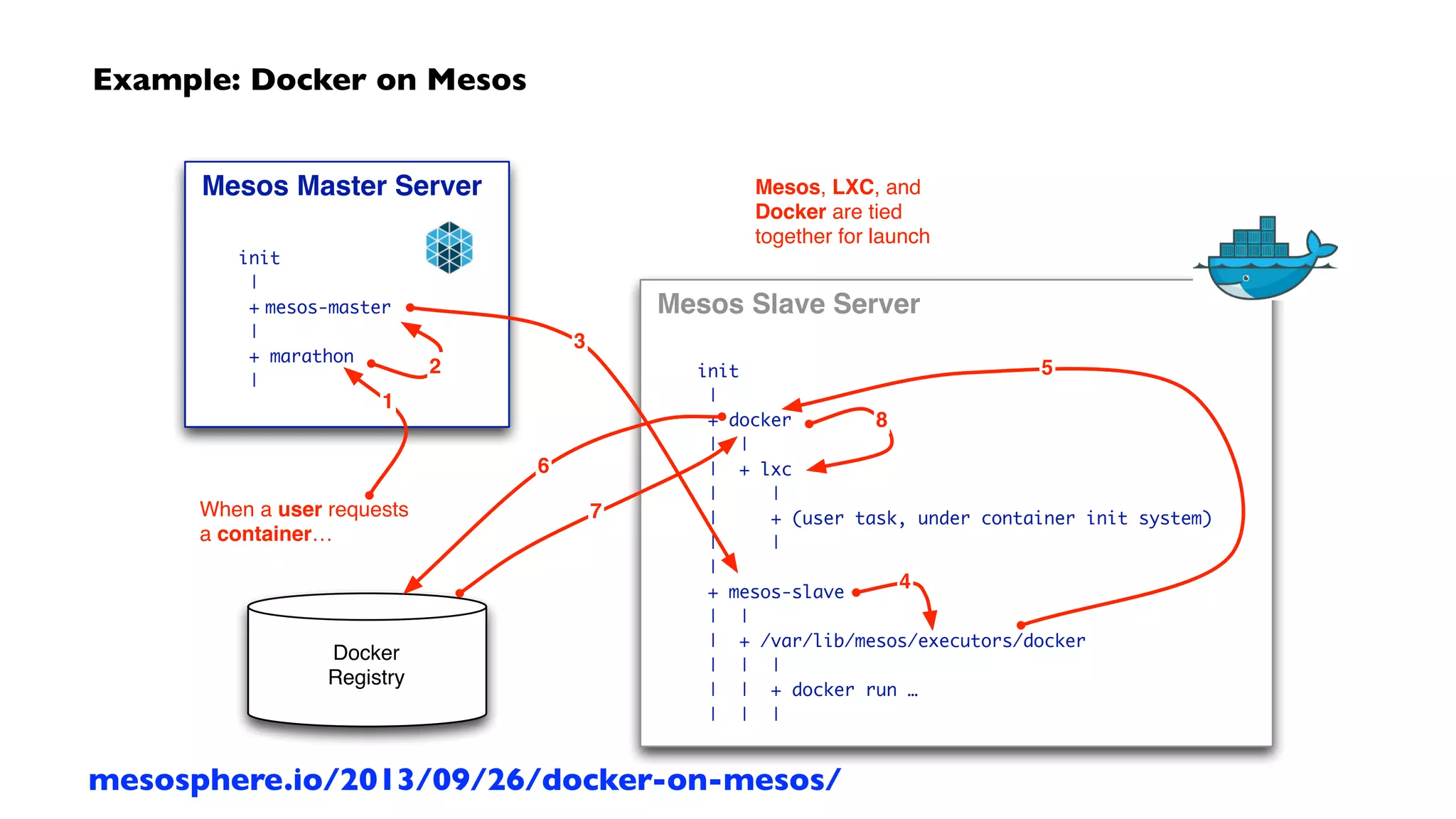
















The document discusses cluster computing with Apache Mesos and Cascading, focusing on the evolution of enterprise data workflows. It examines middleware for big data applications, including examples such as Cascading and Lingual, and highlights how functional programming principles have been integrated into data workflows for efficiency. Additionally, it outlines various use cases and deployments of Cascading in large-scale production environments, emphasizing the importance of declarative programming practices.










































































































