






![Documents
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-8-320.jpg)

![Text
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-10-320.jpg)
![Searching data
GET /library/book/_search?q=elasticsearch
{
"took": 75,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.067124054,
"hits": [
[...]
]
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-11-320.jpg)












![Searching data
GET /library/book/_search?q=elasticsearch
{
"took": 75,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.067124054,
"hits": [
[...]
]
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-24-320.jpg)






![Index Settings for N-Grams
PUT /library-ngram
{
"settings": {
"analysis": {
"analyzer": {
"prefix_analyzer": {
"type": "custom",
"tokenizer": "prefix_tokenizer",
"filter": ["lowercase"]
}
},
"tokenizer": {
"prefix_tokenizer": {
"type": "edgeNGram",
"min_gram" : "4",
"max_gram" : "8",
"token_chars": [ "letter", "digit" ]
}
}
}}}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-31-320.jpg)



![Querying additional Field
GET /library-ngram/book/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "elastic"
}
},
{
"match": {
"title.prefix": "elastic"
}
}
]
}
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-35-320.jpg)


![Storing data
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-38-320.jpg)






![Storing data
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-45-320.jpg)


![Date
POST /library-date/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "30.06.2015",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-48-320.jpg)






![Embedded Documents
POST /library/book
{
"title": "Elasticsearch in Action",
"author": [ "Radu Gheorghe",
"Matthew Lee Hinman",
"Roy Russo" ],
"pages": 400,
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-55-320.jpg)

![Embedded documents
●
1:N relations are problematic
{
"title": "Elasticsearch in Action",
"ratings": [
{
"source": "Amazon",
"stars": 5
},
{
"source": "Goodreads",
"stars": 4
}
]
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-57-320.jpg)
![Embedded documents
●
1:N relations are problematic
"query": {
"bool": {
"must": [
{ "match": { "ratings.source": "Goodreads" }},
{ "match": { "ratings.stars": 5 }}
]
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-58-320.jpg)


![Nested
●
Nested-Query
"query": {
"nested": {
"path": "ratings",
"query": {
"bool": {
"must": [
{ "match": { "ratings.source": "Goodreads" }},
{ "match": { "ratings.stars": 5 }}
]
}
}
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-61-320.jpg)





![Parent-Child
●
has_child/has_parent
POST /library-parent-child/book/_search
{
"query": {
"has_child": {
"type": "rating",
"query": {
"bool": {
"must": [
{ "match": {"source": "Goodreads" }},
{ "match": {"stars": 5 }}
]
}
}
}
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-67-320.jpg)





![Disable dynamic mapping
POST /library/book
{
"titel": "Falsch"
}
{
"error" : "StrictDynamicMappingException[mapping set to
strict! dynamic introduction of [titel] within [book]
is not allowed]",
"status" : 400
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-73-320.jpg)









![Updating data
●
Full update: Replaces a document
PUT /library/book/AVBDusjh0tduyhTzZqTC
{
"title": "Elasticsearch in Action",
"author": [
"Radu Gheorghe",
"Matthew L. Hinman",
"Roy Russo"
],
"published": "2015-06-30T00:00:00.000Z",
"publisher": {
"name": "Manning",
"country": "USA"
}
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-84-320.jpg)







![Index Design
●
Combining indices with Index-Aliases
POST /_aliases
{
"actions" : [
{ "add" : {
"index" : "library-2015*",
"alias" : "thisyear"
}},
{ "add" : {
"index" : "library-2015-10*",
"alias" : "thismonth"
}}
]
}](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-92-320.jpg)

![Index Design
●
Filtered Alias
"actions" : [{
"add" : {
"index" : "library",
"alias" : "buecher",
"filter" : {
"term" : { "publisher.country" : "de" }
}
}
}]](https://image.slidesharecdn.com/datamodeling-for-elasticsearch-151026062212-lva1-app6892/85/Data-modeling-for-Elasticsearch-94-320.jpg)


























![[112]rest에서 graph ql과 relay로 갈아타기 이정우](https://cdn.slidesharecdn.com/ss_thumbnails/112restgraphqlrelay-161023161032-thumbnail.jpg?width=560&fit=bounds)








More Related Content
What's hot (20)
Viewers also liked (9)







Similar to Data modeling for Elasticsearch (20)




















More from Florian Hopf (13)













Recently uploaded (20)




















Data modeling for Elasticsearch
- 1. Data modeling for Florian Hopf - @fhopf GOTO nights Berlin 22.10.2015
- 2. What are we talking about? ● Storing and querying data ● String ● Numeric ● Date ● Embedding documents ● Types and Mapping ● Updating data ● Time stamped data
- 3. Documents
- 5. A relational view ● Different aspects are stored in different tables ● Traversal of tables via join-Operations ● High degree of normalization
- 7. Documents ● Often more natural ● Flexible schema ● Fields can be queried ● Duplicate storage of document parts
- 8. Documents POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 9. Text
- 10. Text POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 11. Searching data GET /library/book/_search?q=elasticsearch { "took": 75, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": 1, "max_score": 0.067124054, "hits": [ [...] ] } }
- 12. Searching data GET /library/book/_search { "query": { "match": { "title": "elasticsearch" } } }
- 13. Understand index storage ● Data is stored in the inverted index ● Analyzing process determines storage and query characteristics ● Important for designing data storage
- 14. Analyzing Term Document Id Action 1 ein 2 Einstieg 2 Elasticsearch 1,2 in 1 praktischer 2 1. Tokenization Elasticsearch in Action Elasticsearch: Ein praktischer Einstieg
- 15. Analyzing Term Document Id action 1 ein 2 einstieg 2 elasticsearch 1,2 in 1 praktischer 2 1. Tokenization Elasticsearch in Action Elasticsearch: Ein praktischer Einstieg 2. Lowercasing
- 16. Search Term Document Id action 1 ein 2 einstieg 2 elasticsearch 1,2 in 1 praktischer 2 1. Tokenization 2. LowercasingElasticsearch elasticsearch
- 17. Inverted Index ● Terms are deduplicated ● Original content is lost ● Elasticsearch stores the original content in a special field source
- 18. Inverted Index ● New requirement: search for German content ● praktischer praktisch→
- 19. Search Term Document Id action 1 ein 2 einstieg 2 elasticsearch 1,2 in 1 praktischer 2 1. Tokenization 2. Lowercasingpraktisch praktisch
- 20. Analyzing Term Document Id action 1 ein 2 einstieg 2 elasticsearch 1,2 in 1 praktisch 2 1. Tokenization Elasticsearch in Action Elasticsearch: Ein praktischer Einstieg 2. Lowercasing 3. Stemming
- 21. Search Term Document Id action 1 ein 2 einstieg 2 elasticsearch 1,2 in 1 praktisch 2 1. Tokenization 2. Lowercasingpraktisch praktisch 3. Stemming
- 22. Mapping curl -XPUT "http://localhost:9200/library/book/_mapping" -d' { "book": { "properties": { "title": { "type": "string", "analyzer": "german" } } } }'
- 23. Understand index storage ● For every indexed document Elasticsearch builds a mapping from the fields in the documents ● Sane defaults for lots of use cases ● But: understand and control it and your data
- 24. Searching data GET /library/book/_search?q=elasticsearch { "took": 75, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": 1, "max_score": 0.067124054, "hits": [ [...] ] } }
- 25. _all ● Default search field _all "book": { "_all": { "enabled": false } }
- 26. Partial Word Matches ● New requirement: Search for parts of words ● elastic elasticsearch→
- 27. Partial Word Matches ● Common option: Using wildcards POST /library/book/_search { "query": { "wildcard": { "title": { "value": "elastic*" } } } }
- 28. Partial Word Matches ● Wildcards ● Query time option ● Scalability?
- 29. Partial Word Matches ● Alternative: Index Time preprocessing ● Terms are stored in the index in a special way ● Search is then a normal lookup ● For partial words: N-Grams
- 30. N-Grams ● Configuring an N-Gram analyzer ● Builds N-Grams ● elas ● elast ● elasti ● elastic ● elastics ● ...
- 31. Index Settings for N-Grams PUT /library-ngram { "settings": { "analysis": { "analyzer": { "prefix_analyzer": { "type": "custom", "tokenizer": "prefix_tokenizer", "filter": ["lowercase"] } }, "tokenizer": { "prefix_tokenizer": { "type": "edgeNGram", "min_gram" : "4", "max_gram" : "8", "token_chars": [ "letter", "digit" ] } } }}}
- 32. Mapping for N-Grams PUT /library-ngram/book/_mapping { "book": { "properties": { "title": { "type": "string", "analyzer": "german", "fields": { "prefix": { "type": "string", "index_analyzer": "prefix_analyzer", "query_analyzer": "lowercase" } } } } } }
- 33. Additional Field ● Indexed Document stays the same ● Additional index field title.prefix ● Can be queried like any field
- 34. Querying additional Field GET /library-ngram/book/_search { "query": { "match": { "title.prefix": "elastic" } } }
- 35. Querying additional Field GET /library-ngram/book/_search { "query": { "bool": { "should": [ { "match": { "title": "elastic" } }, { "match": { "title.prefix": "elastic" } } ] } } }
- 36. Additional Field ● Increased storage requirements ● Increased scalability (and performance) during search ● Trade storage against search performance
- 37. Numbers
- 38. Storing data POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 39. Querying POST /library/book/_search { "query": { "term": { "pages": "400" } } } ● Numeric term is in index
- 40. Querying POST /library/book/_search { "query": { "range": { "pages": { "gte": 300 } } } } ● Ranges
- 41. Numeric values ● Numeric values are stored in a Trie structure ● Makes range queries very efficient
- 42. Numeric values ● Simplified view: 250, 290 and 400
- 43. Numeric values ● Precision influences depth of tree ● Lower precision_step higher number of→ terms ● Most of the time defaults are fine
- 44. Date
- 45. Storing data POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 46. Date ● Default: ISO8601 format ● Joda Time patterns ● Internally stored as long
- 47. Date PUT /library-date/book/_mapping { "book": { "properties": { "published": { "type": "date", "format": "dd.MM.yyyy" } } } }
- 48. Date POST /library-date/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "30.06.2015", "publisher": { "name": "Manning", "country": "USA" } }
- 49. Date ● Common: Filtering on date range ● from and/or to
- 50. Date "query": { "filtered": { "filter": { "range": { "published": { "to": "30.06.2015" } } } } }
- 51. Date "query": { "filtered": { "filter": { "range": { "published": { "to": "now-3M" } } } } }
- 52. Date ● Filter is not cached with 'now' ● Only cached with rounded value "range": { "published": { "to": "now-3M/d" } }
- 53. Date ● Exact values needed Combine filters→
- 55. Embedded Documents POST /library/book { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew Lee Hinman", "Roy Russo" ], "pages": 400, "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 56. Embedded Documents ● Default: Flat structure ● Good for 1:1 relation "publisher": { "name": "Manning", "country": "USA" } "publisher.name": "Manning", "publisher.country": "USA"
- 57. Embedded documents ● 1:N relations are problematic { "title": "Elasticsearch in Action", "ratings": [ { "source": "Amazon", "stars": 5 }, { "source": "Goodreads", "stars": 4 } ] }
- 58. Embedded documents ● 1:N relations are problematic "query": { "bool": { "must": [ { "match": { "ratings.source": "Goodreads" }}, { "match": { "ratings.stars": 5 }} ] } }
- 59. Nested ● Solution: Nested documents ● Lucene internal: Seperate document, connected via Block-Join ● Accessing documents via specialized query
- 60. Nested ● Explicit mapping "book": { "properties": { "ratings": { "type": "nested", "properties": { "source": { "type": "string" }, "stars": { "type": "integer" } } } } }
- 61. Nested ● Nested-Query "query": { "nested": { "path": "ratings", "query": { "bool": { "must": [ { "match": { "ratings.source": "Goodreads" }}, { "match": { "ratings.stars": 5 }} ] } } } }
- 63. Parent-Child ● Alternative storage ● Indexing seperate types ● Connection via parent parameter
- 64. Parent-Child ● Book is stored without ratings POST /library-parent-child/book/ { "title": "Elasticsearch in Action", "publisher": { "name": "Manning" } }
- 65. Parent-Child ● Ratings reference books PUT /library-parent-child/rating/_mapping { "rating": { "_parent": { "type": "book" } } }
- 66. Parent-Child ● Ratings reference book POST /library-parent-child/rating? parent=AU_smK5FYK634dNiekGr { "source": "Amazon", "stars": 5 } POST /library-parent-child/rating? parent=AU_smK5FYK634dNiekGr { "source": "Goodreads", "stars": 4 }
- 67. Parent-Child ● has_child/has_parent POST /library-parent-child/book/_search { "query": { "has_child": { "type": "rating", "query": { "bool": { "must": [ { "match": {"source": "Goodreads" }}, { "match": {"stars": 5 }} ] } } } } }
- 68. Parent-Child ● Stored on same shard ● Only suitable for smaller amounts of docs ● Requires different types
- 70. Querying Elasticsearch ● Ad-hoc queries ● But better characteristics when designing storage for query ● Flexible Schema ● But mapping better defined upfront
- 71. Mapping ● Mapping for field can't be changed ● Think about how you will be querying your data ● Think about defining a static mapping upfront
- 72. Disable dynamic mapping PUT /library/book/_mapping { "book": { "dynamic": "strict" } }
- 73. Disable dynamic mapping POST /library/book { "titel": "Falsch" } { "error" : "StrictDynamicMappingException[mapping set to strict! dynamic introduction of [titel] within [book] is not allowed]", "status" : 400 }
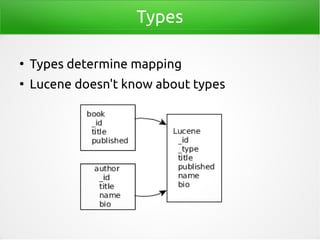
- 74. Types ● Types determine mapping ● Lucene doesn't know about types
- 75. Types ● Fields with same names need to be mapped the same way ● Relevance can be influenced ● Index settings: shards, replicas per type?
- 76. Key-Value-Store ● Careful when using ES as key-value-store ● Mapping is part of cluster state
- 77. Updating Data
- 78. Updating Data ● Primary Datastore ● Full indexing ● Incremental indexing
- 79. Updating Data ● Elasticsearch stores data in segment files ● Immutable files ● Segment is a mini inverted index
- 80. Segments
- 81. Segments ● Building inverted index is expensive ● Add documents add new segments→
- 82. Segments ● Doc deletion is only a marker ● Deleted documents are automatically filtered
- 83. Updating Data ● Documents can be updated ● Full Update ● Partial Update
- 84. Updating data ● Full update: Replaces a document PUT /library/book/AVBDusjh0tduyhTzZqTC { "title": "Elasticsearch in Action", "author": [ "Radu Gheorghe", "Matthew L. Hinman", "Roy Russo" ], "published": "2015-06-30T00:00:00.000Z", "publisher": { "name": "Manning", "country": "USA" } }
- 85. Updating data ● Partial update: Uses source of document POST /library/book/AVBDusjh0tduyhTzZqTC/_update { "doc": { "title": "Elasticsearch In Action" } }
- 86. Updating data ● Update = Delete + Add ● Expensive operation ● Design documents as events if possible
- 87. Timestamps
- 88. Working with timestamps ● Timestamped data ● Write events ● Common: Log events
- 89. Index Design ● Use date aware index name ● library-221015 ● Create a new index every day
- 90. Index Design ● Index templates for custom settings PUT /_template/library-template { "template": "library-*", "mappings": { "book": { "properties": { "title": { "type": "string", "analyzer": "german" } } } } }
- 91. Index Design ● Search multiple indices GET /library-221015,library-211015/_search GET /library-*/_search
- 92. Index Design ● Combining indices with Index-Aliases POST /_aliases { "actions" : [ { "add" : { "index" : "library-2015*", "alias" : "thisyear" }}, { "add" : { "index" : "library-2015-10*", "alias" : "thismonth" }} ] }
- 93. Index Design ● Implicit date selection GET /thisyear/_search GET /thismonth/_search
- 94. Index Design ● Filtered Alias "actions" : [{ "add" : { "index" : "library", "alias" : "buecher", "filter" : { "term" : { "publisher.country" : "de" } } } }]
- 95. What is missing? ● Distributed data and Routing ● Field Data and Doc Values ● Index-Options ● Geo-Data
- 96. More Info
- 97. More Info ● http://elastic.co ● Elasticsearch – The definitive Guide ● https://www.elastic.co/guide/en/elasticsearch/gui de/master/index.html ● Elasticsearch in Action ● https://www.manning.com/books/elasticsearch-in- action ● http://blog.florian-hopf.de