機械学習 / Deep Learning 大全 (1) 機械学習基礎編
Download as pptx, pdf13 likes4,032 views

機械学習の技術的基礎部分を中心にまとめています。実装をする際の各種ハイパーパラメータの概要は理解できる程度に。























































![karugamoが写っているの
に、
モデルは推定できなかっ
た
▶モデルの見逃し
あり[予
測]
なし[予
測]
あり[正
解]
XX XX
なし[正
解]
XX XX](https://image.slidesharecdn.com/izl6nhuaqzy3bktdbq2t-signature-d85b71c945cf62a6f9fce7b23a81a9e19ade9b18a1f3a8b8765911893c827dcd-poli-180918212319/85/Deep-Learning-1-58-320.jpg)
![Karugamo でないもの
に、
Karugamo と推定
▶モデルの過検知?
あり[予
測]
なし[予
測]
あり[正
解]
XX XX
なし[正
解]
XX XX](https://image.slidesharecdn.com/izl6nhuaqzy3bktdbq2t-signature-d85b71c945cf62a6f9fce7b23a81a9e19ade9b18a1f3a8b8765911893c827dcd-poli-180918212319/85/Deep-Learning-1-59-320.jpg)






















































![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=560&fit=bounds)












![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=560&fit=bounds)








More Related Content
What's hot (20)
Similar to 機械学習 / Deep Learning 大全 (1) 機械学習基礎編 (20)

















![[Developers Summit 2017] MicrosoftのAI開発機能/サービス](https://cdn.slidesharecdn.com/ss_thumbnails/20170216devsumiai-170302021003-thumbnail.jpg?width=560&fit=bounds)
More from Daiyu Hatakeyama (20)




















Recently uploaded (6)






機械学習 / Deep Learning 大全 (1) 機械学習基礎編
- 3. #azurejp ドアの後ろに人がいます 入ってくる人は、男性 / 女性 のどちらで しょうか? 既知の情報は以下のみ 年齢: 35歳 年収: 600万円 有給残数: 12日 F (性別) = (0.03 * 年齢) + (0.07 * 年収) – (0.04 * 有給残数) + 0.05 = (0.03 * 3.5) + (0.07 * 6.0) – (0.04 * 1.2) + 0.05 = 0.41 0.5 よりも小さいから = 女性
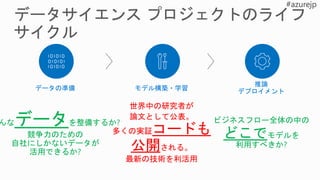
- 5. 機械学習 深層学習 深層強化学習 画像解析 音声解析 データ分類 異常検知, 顧客グルーピング 数値予測 売上予測, 需要予測, 品質管理 ラベル分類 不良品分析, 故障予測, チャーン分析 機械学習より強力な分析 自律学習型ロボット 自動運転車 テキストや画像等の自動生成 活用例 主に多層のニューラルネットワーク を用いた手法での分析 分析のためには、莫大なデータ量、 計算量、知識・スキルを要する 統計に基づいた手法での分析 そのため、比較的少ないデータ量と 計算量で分析を行うことができる 定義したあるべき姿に従い試行錯誤 をして自ら学習を行うための分析手 法である 強化学習と、深層学習を組み合わせ た 分析 Azure Machine Learning Cognitive Toolkit / GPU Instance (N-Series) マイクロソフトが提供する技術
- 6. #azurejp 機械 学習 教師あり 学習 教師なし 学習 強化学習 決定木 線形回帰 SVM ロジスティック回帰 ニューラルネットワー ク クラスタリン グ 次元削減 K-mean法 主成分分析 正準相関分析 ディープ ニュー ラル ネットワーク 畳みこみニュー ラルネットワー ク 再帰的ニューラ ルネットワーク 回帰結合ニュー ラルネットワー ク Q学習 深層学習 画像解析, 音声認識, 自動生成 深層強化学習 自立学習型ロボット 自動運転車
- 7. #azurejp
- 8. Model を理解する
- 9. 天気 気温 風 試合をしたか? 晴れ 低い ある Yes 晴れ 高い ある No 晴れ 高い なし No 曇り 低い ある Yes 曇り 高い なし Yes 曇り 低い なし Yes 雨 低い ある No 雨 低い なし Yes 晴れ 低い なし ?
- 10. 天気 気温 風 試合をしたか? 晴れ 低い ある Yes 晴れ 高い ある No 晴れ 高い なし No 曇り 低い ある Yes 曇り 高い なし Yes 曇り 低い なし Yes 雨 低い ある No 雨 低い なし Yes 晴れ 低い なし ? 晴れ 曇り 雨 低い 高い なし ある
- 11. 天気 気温 風 試合をしたか? 晴れ 低い ある Yes 晴れ 高い ある No 晴れ 高い なし No 曇り 低い ある Yes 曇り 高い なし Yes 曇り 低い なし Yes 雨 低い ある No 雨 低い なし Yes 晴れ 低い なし ?
- 12. Input data Data Transformation Train Model Algorithm Split Data Score Model Evaluate Model
- 15. 天気 気温 風 場所 試合をしたか? 晴れ 25 ある さいたま Yes 晴れ 27 ある さいたま Yes 晴れ 高い 10 東京 No 曇り 5 ある 千葉 No 雨 低い なし 神奈川 No
- 16. データセット Features Target Value データ処理(s) データ処理のためのモジュール 1) RawData ロード 2) トレーニン グ用のデータ 作成 Data 2 Data 1 Data N . . . 100011010011 110111110110
- 17. トレーニング用データセット アルゴリズム の選択 2) トレーニング用の データを入力 (選択した1,3,6の列と、 全体の80%の件数) 候補モデル 3) 候補モデル の作成 1) features の選択 Target ValueFeature 1 Feature 3 Feature 6
- 18. 2) テストデータ から、ターゲッ トの値を 生成 3) テストデータの実際の値と、 ターゲットの値を比較する トレーニング用データセット Target ValueFeature 1 Feature 3 Feature 6 1) 検証用データの 入力 (残った25%のデー タ の、features 1, 3, 6 だけを使う) 候補モデル
- 19. 候補 モデル 3) アルゴリズムのパラメータの 変更。もしくは、別のアルゴリ ズムの選択 Feature 1 Feature 2 Feature 5 1) 別の features を選択す る アルゴリズム の選択 2) サンプルデータを追加する 学習用アルゴリズム
- 20. Raw Data Prepared Data 事前準備処理 Model の選択 データに アルゴリズム を 適用して Model を 作成 選ばれた Model候補 Model
- 25. Class 1 Class 2 2つ以上でも良い
- 31. Is there a deer in the image? Where is the deer in the image? Where exactly is the deer? What pixels? Which images are similar to the query image? Image Classification Object detection Image segmentation Image Similarity Similar image Query imageYes
- 34. <Python> Modelの保存 出力された Model <C#>Model の読み込み <C#>Model の利用 (実行)
- 35. Services Schema モデ ル スキーマ ファ イル (Option) 推論実行 コード Machine Learning モデルを Web サービスとしてデプロイする Azure Kubernetes Services Azure Machine Learning Services まずは ここ Container 使い Hack しま せぅ Secure Data
- 36. 従来の システム開発と の 違い
- 39. 2 + 3 = 5
- 40. 2 + 3 = 5 簡単 大変…
- 41. 2 + 3 = 5 簡単 大変…
- 43. Program = Algorithm 人が書く タスクの仕様の定義 アルゴリズムは固定 アルゴリズムは容易に説明できる ソフトウェアが書く 目的: 汎化 アルゴリズムはデータに依存 アルゴリズムは時間とともに変わる
- 44. Program = Algorithm 人が書く タスクの仕様の定義 アルゴリズムは固定 アルゴリズムは容易に説明できる ソフトウェアが書く 目的: 汎化 アルゴリズムはデータに依存 アルゴリズムは時間とともに変わる 実世界の全てを想定して、 プログラミングするのは、難しい…
- 45. 万能なものは無い
- 49. Alpha Go Zero
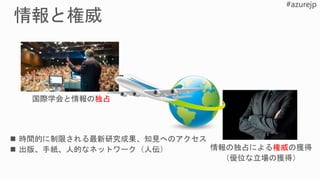
- 50. 独占 権威
- 51. 変革の速度 競争領域
- 52. アルゴリズムとして実装
- 53. 機械学習によるモデル化 機械学習の最大限の可能性は、 データソース (IoT) との紐づけ と デプロイの自動化 (AutoML)
- 54. • 強い因果関係と説明責任が必要 • 想定外の事態での危機管理 な ど • 因果関係が必要な予測 • 人間の予測と機械学習の予 測の両方を使う • 相関関係が分かればいいことの 予測 • 誰が正しいのか議論しても あまり意味がないもの
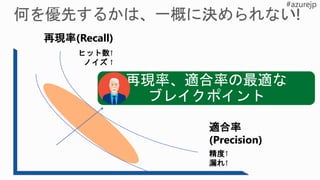
- 57. ①True Positive(真陽性) : 100%に近いほど良好 ⇒A/(A+C) ②False Positive(偽陽性) : 0%に近いほど良好 ⇒B/(B+D) ③True Negative : 100%に近いほど良好 ⇒D/(B+D) ④False Negative : 0%に近いほど良好 ⇒C/(C+D) ⑤Accuracy(正解率) : 100%に近いほど良好 ⇒「○」「×」を正しく予測できた割合 ⇒(A+D)/(A+B+C+D) : 100%に近いほど良好 ⑥Precision(適合率) : 100%に近いほど良好 ⇒A/(A+B) ⑦Recall(再現率) : 100%に近いほど良好 ⇒①に同じ ⑧F1 Score :1.0に近いほど良好 ⇒⑥、⑦の複合指標 ⇒2×(⑥×⑦)/(⑥+⑦) 検証用データ 予測で得たクラス ○ × 正解の クラス ○ A件 C件 × B件 D件 正解が「○」 のデータ 推測で「○」と されたデータ A件C件 B件 D件 予測結果例 主な評価指標
- 59. Karugamo でないもの に、 Karugamo と推定 ▶モデルの過検知? あり[予 測] なし[予 測] あり[正 解] XX XX なし[正 解] XX XX
- 61. プログラミング 機械学習 アプローチ 演繹的 帰納的。つまりブラックボック スは残る 機能保証 (≒ 精度): Function Test 可能 訓練データ次第。ただ、統計の 域を出ない 性能保証: Performance Test 可能 可能 妥当性確認試験: Validation Test 可能 やってみないと、わかならい
- 69. Permutation Feature Importance (PFI) それぞれの説明変数の重要度をスコアリングするア ルゴリズム。重要度は説明変数の値を変化させたと きに、どの程度目的変数に影響したかを持って計算 される
- 70. Filter Based Feature Selection 多くの場合、無関係な特徴、重複した特徴、関連性の高い特徴を排除すること で、 分類の精度を向上させる スコアリングメソッド • ピアソンの相関関係 • 相互情報量 • ケンドールの相関関係 • スピアマンの相関関係 • カイ二乗 • フィッシャー スコア • カウント ベース
- 72. 次数 種類 代表値 内 容 1 次 位置 最大値 もっとも大きな値 最小値 もっとも小さな値 最頻値(モード) 出現する回数が最も多い値 中央値(メジアン) 値を大小の順に並べた場合に中央にくる値 (個数が偶数の場合は中心の 2 値の平均) 平 均 相加平均 データをならして得られる値でならし方に よって様々な種類がある 値を合計して個数で割った数 相乗平均 値の積の n 乗根 (n:値の個数) 調和平均 値の逆数の平均の逆数 中間項平均 特異値を除いた値の平均 加重平均 重みをかけて合計した値を重みの合計で割ったも の バラツ キ 偏 差 平均偏差 データが平均値の周りにどれくらい集まっ ているか、あるいはばらついているかを表 す値 値と平均の差の絶対値の平均 2 次 標準偏差 値と平均の差の平方の平均の平方根 分 散 値と平均の差の平方の平均 3 次 偏り 歪 度 値が正負どちらの方向に外れているかを表す値 4 次 集中度 尖 度 データの平均値への集中の程度を表す値
- 73. 相関の 3 つのパターン ① ある変量が増大すると、もう一方の変数も増大 ⇒ 正の相関 ② ある変量が増大しても、もう一方の変数には無関係 ⇒ 相関なし ③ ある変量が増大すると、もう一方の変数は減少 ⇒ 負の相関 正の相関負の相関 相関なし ビールの売 上 気温気温 雑誌の売上 気温 おでんの売上
- 74. 正の相関関係 強 負の相関関係 強 正の相関 解釈 0~0.1 無相関 0.1~0.3 弱い正の相関関係 0.3~0.7 中程度の正の相関関係 0.7~1 強い正の相関関係 負の相関 解釈 -0.1 ~ 0 無相関 -0.3~-0.1 弱い負の相関関係 -0.7~-0.3 中程度の負の相関関係 -1~-0.7 強い負の相関関係
- 75. 5 月 1 日 (26 度、30 個) 3 月 1 日 (12 度、150 個)
- 76. 回帰直線 (Y =a X +b) 残差 xi yi Yi
- 77. 回帰直線 (Y =a X +b) から 気温が 15 ℃ のとき、 おでんは 100 個売れることが予測で きる
- 78. 回帰分析 線形回帰 ベイズ線形回帰 ポワソン回帰 順序回帰 ニューラルネットワーク 決定木 ランダムフォレスト Decision Jungle 分位点回帰 統計分類 ロジスティクス回帰 サポートベクタマシン 決定木 ランダムフォレスト ニューラルネットワーク Locally-Deep サポートベクタマシン ベイズポイントマシン 平均化パーセプトロン Decision Jungle 異常検知 サポートベクタマシン PCAベース異常検知 その他 テキスト分析 (n-gram) リコメンドエンジン クラスタリング k平均法 (k-means) Open CV
- 79. 名称 日本名 説明 例 Linear Regression 線形回帰 線形モデルによる解析をしたい。ある データが増減すると、それに伴って結 果も増減する Bayesian Linear Regression ベイズ線形回 帰 Linear Regressionと同様だが、確率分 布を用いる Ordinal Regression 順序回帰 順序尺度のつけたい場合 「1=良い」「2=普通」 「3=悪い」 Position Regression ポアソン回帰 特定の事情に関する回数 「1時間に通過する人数」 「1日に受信するメール 数」 Fast Forest Quantile Regression 高速フォレス ト分位点回帰 データがどのように分布しているのか Decision Forest Regression 決定フォレス ト回帰 分布予測するのに用いる。精度は高い が学習に時間がかかる Boosted Decision Tree Regression ブースト決定 木回帰 分布予測するのに用いる。精度が高く、 高速だが、高メモリが必要。
- 81. “境界” を見つけること 最近接値による境界 決定木 線形関数 非線形関数
- 82. 長さ = d データ A (a1, a2) データ B (b1, b2) 変数 1 の値 変数 2 の値 長さ d の値が短いほど類似性が高い データ A (a1, a2) データ B (b1, b2) 変数 1 の値 変数 2 の値 Θ 2 つのベクトルのなす角度 Θ の値が小さいほど類似度が高
- 83. 𝑦 = 𝑤1 𝑥1 + 𝑤2 𝑥2+・・・ 𝑤 𝑚 𝑥 𝑚+𝑐 パラメータの求め方 概要 最小二乗法 (Ordinary least squares) 学習用データにおける予測値と正解値の誤差の2乗を足した値が最小にな るようにパラメータを調整 オンライン勾配降下法 (Online gradient descent) モデルのトレーニング プロセスの各ステップでの誤差量を最小限に抑え る手法
- 87. age>30 age≤30 ビジター 会員 Predict y=1 Predict y=-1 Predict y=-1 Predict y=1 Predict y=-1 Predict y=1 Predict y=-1 Predict y=1 男性女性 購入実績あり なし 金額 >= 20000 <20000
- 88. Decision Forest(ランダムフォレスト)とは? Decision Treeが進化したもので、マシンパワーの飛躍的な向上で実現できるようになった最新モデル化技術。 Decision Treeモデルはわかりやすく、汎用的である一方で、モデルによっては偏りが高く、人間によるモデル修正 が必要とされていた。Decision Forestは多サンプルによる合議制(Ensemble方式)を取り、モデル構築データ依存度 の低い(低バリアンス)なメソッドである。
- 90. 分析の種類 説明 学習方法 クラス分類 母集団に属する要素が、ある基準で分類された集合のどこに属するかを予測 する • どのメールがスパムか?(メールの属性データを使用し、「スパムである」 「スパムでない」 に分類) 「教師あり」 学習 クラスタリ ング 特定の分類基準を与えず、属性データから類似性から、母集団をグルーピン グする • どの顧客グループにどのような製品を提案するべきか? 「教師なし」 学習
- 91. X2 < 2 万円? X1 < 25? 識別境界面 A X1 < 40? YES NO B YES C YES NO D NO
- 94. 増加トレンド 外れ値 外れ値
- 96. Matchbox Recommender – Microsoft Research が開発したラージ・スケール・ベイジアン・ リコメンダー システム – 例えば映画やコンテンツ、その他の商品などのアイテムの評価を 利用し、 学習することができる – リクエストごとにユーザーに対して新しいアイテムをリコメンド することができる – Matchbox のアルゴリズムは協調フィルタリングおよびコンテンツ ベースの リコメンド方式がベース • ※ Matchbox の詳細については以下のサイトからご確認頂けま す Matchbox Recommender System http://research.microsoft.com/en-us/projects/matchbox/ Matchbox: Large Scale Online Bayesian Recommendations (アルゴリズムの詳細) http://msr-waypoint.com/pubs/79460/www09.pdf – 考慮点 • 類似度の計算を選択する事ができず、類似度の値を確認するには工夫が 必要 • 評価の際に、混同行列から各種評価値を作る場合には工夫が必要
- 98. A さん B さん C さん D さん 5 4 7 4 5 6 7 ? 1 7 - 7 2 8 6 -
- 99. A さん B さん C さん D さん 5 4 7 4 5 4 7 ? 3 8 - 8 2 5 6 - 5 4 7 4 5 4 7 ? 3 8 - 8 2 5 6 -
- 100. トレーニングの種 類 説明 Sweep parameters 最適なパラメーター設定を決定するために、モデルのパラメーターの 絞り込みを行う Train Anomaly Detection Model 外れ値検知モデルのトレーニング Train Clustering Model クラスター モデルのトレーニングとクラスターへのデータ割り当て Train Matchbox Recommender マッチ ボックス レコメンダー (Matchbox Recommender) モデルのト レーニング Train Model 回帰 (Regression) と分類 (Classification) モデルのトレーニング
- 101. スコア付けの種類 説明 Apply Transformation データセットへの事前定義されたデータ変換の適用 Assign to Clusters トレーニング済みのクラスター モデルを使用したデータの割り当て Score Matchbox Recommender マッチ ボックス レコメンダー (Matchbox Recommender) モデルのス コア付け Score Model 回帰 (Regression) と分類 (Classification) モデルのスコア付け
- 102. 評価の種類 説明 Cross Validate Model 回帰 (Regression) モデルと分類 (Classification) モデルのクロス評 価 Evaluate Model スコア付けされた回帰 (Regression) または、分類 (Classification) モデルの評価 Evaluate Matchbox Recommender スコア付けされたマッチ ボックス レコメンダー (Matchbox Recommender) モデルの評価
- 104. 評価方法 概要 平均絶対誤差 (Mean Absolute Error: MAE) 絶対誤差の平均値 平均二乗誤差 (Root Mean Squared Error: RMSE) 誤差の二乗の平方根値 相対絶対誤差 (Relative Absolute Error: RAE) 絶対誤差の合計を正規化して 合計相対誤差で除算した値 相対二乗誤差 (Relative Squared Error: RSE) 二乗誤差の合計を正規化して 合計二乗誤差で除算した値 決定係数 (R2 ) (Coefficient of Determination) 特徴量がラベルを決定す る度合 (悪:0 ~ 良:1)
- 105. ①True Positive(真陽性):100%に近いほど良好 ⇒A/(A+C) ②False Positive(偽陽性): 0%に近いほど良好 ⇒B/(B+D) ③True Negative : 100%に近いほど良好 ⇒D/(B+D) ④False Negative : 0%に近いほど良好 ⇒C/(C+D) ⑤Accuracy(正解率) : 100%に近いほど良好 ⇒「○」「×」を正しく予測できた割合 ⇒(A+D)/(A+B+C+D) : 100%に近いほど良好 ⑥Precision(適合率) : 100%に近いほど良好 ⇒A/(A+B) ⑦Recall(再現率) : 100%に近いほど良好 ⇒①に同じ ⑧F1 Score : 1.0に近いほど良好 ⇒⑥、⑦の複合指標 ⇒2×(⑥×⑦)/(⑥+⑦) 検証用データ 予測で得たクラス ○ × 正解の クラス ○ A件 C件 × B件 D件 正解が「○」 のデータ 推測で「○」と されたデータ A件C件 B件 D件 予測結果例 主な評価指標
Editor's Notes
- #49: 48