Dynamic Partition Pruning in Apache Spark

In data analytics frameworks such as Spark it is important to detect and avoid scanning data that is irrelevant to the executed query, an optimization which is known as partition pruning. Dynamic partition pruning occurs when the optimizer is unable to identify at parse time the partitions it has to eliminate. In particular, we consider a star schema which consists of one or multiple fact tables referencing any number of dimension tables. In such join operations, we can prune the partitions the join reads from a fact table by identifying those partitions that result from filtering the dimension tables. In this talk we present a mechanism for performing dynamic partition pruning at runtime by reusing the dimension table broadcast results in hash joins and we show significant improvements for most TPCDS queries.



















Recommended






























More Related Content
What's hot (20)
Similar to Dynamic Partition Pruning in Apache Spark (20)


















More from Databricks (20)




















Recently uploaded (20)




















Dynamic Partition Pruning in Apache Spark
- 1. Dynamic Partition Pruning in Apache Spark Spark + AI Summit, Amsterdam 1 Bogdan Ghit and Juliusz Sompolski
- 2. 2 About Us BI Experience team in the Databricks Amsterdam European Development Centre ● Working on improving the experience and performance of Business Intelligence / SQL analytics workloads using Databricks ○ JDBC / ODBC connectivity to Databricks clusters ○ Integrations with BI tools such as Tableau ○ But also: core performance improvements in Apache Spark for common SQL analytics query patterns Bogdan Ghit Juliusz Sompolski
- 3. TPCDS Q98 on 10 TB How to Make a Query 100x Faster?
- 4. Static Partition Pruning SELECT * FROM Sales WHERE day_of_week = ‘Mon’ Filter Scan Basic data-flow Filter Scan Filter Push-down Filter Scan Partition files with multi-columnar data
- 5. Table Denormalization SELECT * FROM Sales JOIN Date WHERE Date.day_of_week = ‘Mon’ Static pruning not possible Scan Sales Filter day_of_week = ‘mon’ Join Simple workaround Scan Sales Join Scan Date Filter day_of_week = ‘mon’ Scan Scan Date
- 6. This Talk Dynamic pruning Scan Sales Filter day_of_week = ‘mon’ Join SELECT * FROM Sales JOIN Date WHERE Date.day_of_week = ‘Mon’ Scan Countries
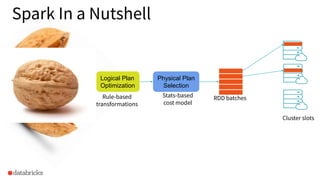
- 7. Spark In a Nutshell Query Logical Plan Optimization Physical Plan Selection RDD batches Cluster slots Stats-based cost model Rule-based transformations APIs
- 8. Optimization Opportunities Data Layout Partition files with multi-columnar data Scan FACT TABLE Scan DIM TABLE Non-partitioned dataset Filter DIM Join on partition id Query Shape
- 9. A Simple Approach Partition files with multi-columnar data Scan FACT TABLE Scan DIM TABLE Non-partitioned dataset Filter DIM Join on partition id Scan DIM TABLE Filter DIM Work duplication may be expensive Heuristics based on inaccurate stats
- 10. Broadcast Hash Join FileScan FileScan with Dim Filter Non-partitioned dataset BroadcastExchange Broadcast Hash Join Execute the build side of the join Place the result in a broadcast variableBroadcast the build side results Execute the join locally without a shuffle
- 11. Reusing Broadcast Results Partition files with multi-columnar data FileScan FileScan with Dim Filter Non-partitioned dataset BroadcastExchange Broadcast Hash Join Dynamic Filter
- 12. Experimental Setup Workload Selection - TPC-DS scale factors 1-10 TB Cluster Configuration - 10 i3.xlarge machines Data-Processing Framework - Apache Spark 3.0
- 13. TPCDS 1 TB 60 / 102 queries speedup between 2 and 18
- 14. Top Queries Very good speedups for top 10% of the queries
- 15. Data Skipped Very effective in skipping data
- 16. TPCDS 10 TB Even better speedups at 10x the scale
- 17. Query 98 SELECT i_item_desc, i_category, i_class, i_current_price, sum(ss_ext_sales_price) as itemrevenue, sum(ss_ext_sales_price)*100/sum(sum(ss_ext_sales_price)) over (partition by i_class) as revenueratio FROM store_sales, item, date_dim WHERE ss_item_sk = i_item_sk and i_category in ('Sports', 'Books', 'Home') and ss_sold_date_sk = d_date_sk and cast(d_date as date) between cast('1999-02-22' as date) and (cast('1999-02-22' as date) + interval '30' day) GROUP BY i_item_id, i_item_desc, i_category, i_class, i_current_price ORDER BY i_category, i_class, i_item_id, i_item_desc, revenueratio
- 18. TPCDS 10 TB Highly selective dimension filter that retains only one month out of 5 years of data
- 19. Conclusion Apache Spark 3.0 introduces Dynamic Partition Pruning - Strawman approach at logical planning time - Optimized approach during execution time Significant speedup, exhibited in many TPC-DS queries With this optimization Spark may now work good with star-schema queries, making it unnecessary to ETL denormalized tables.
- 20. 20 Thanks! Bogdan Ghit - linkedin.com/in/bogdanghit Juliusz Sompolski - linkedin.com/in/juliuszsompolski