












































































































![Optimizing compilation time
float3 fanBlades[10];
for (uint i = 0; i < 10; ++i)
{
Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]);
fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position;
}
float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]);
for (uint j = 0; j < 8; ++j)
{
float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]);
uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j);
if (isTriangleFilled) normalAccumulator += triangleNormal;
}
115 / 122](https://image.slidesharecdn.com/828884alexisvaisse-240613133913-c3dfe2d2/85/Efficient-Usage-of-Compute-Shaders-on-Xbox-One-and-PS4-115-320.jpg)
![Optimizing compilation time
float3 fanBlades[10];
for (uint i = 0; i < 10; ++i)
{
Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]);
fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position;
}
float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]);
for (uint j = 0; j < 8; ++j)
{
float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]);
uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j);
if (isTriangleFilled) normalAccumulator += triangleNormal;
}
116 / 122](https://image.slidesharecdn.com/828884alexisvaisse-240613133913-c3dfe2d2/85/Efficient-Usage-of-Compute-Shaders-on-Xbox-One-and-PS4-116-320.jpg)
![Optimizing compilation time
float3 fanBlades[10];
for (uint i = 0; i < 10; ++i)
{
Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]);
fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position;
}
float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]);
for (uint j = 0; j < 8; ++j)
{
float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]);
uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j);
if (isTriangleFilled) normalAccumulator += triangleNormal;
}
Shader compilation time
Loop 19”
Manually unrolled 6”
117 / 122](https://image.slidesharecdn.com/828884alexisvaisse-240613133913-c3dfe2d2/85/Efficient-Usage-of-Compute-Shaders-on-Xbox-One-and-PS4-117-320.jpg)


































More Related Content
Similar to Efficient Usage of Compute Shaders on Xbox One and PS4 (20)
More from Slide_N (20)


















Recently uploaded (20)




















Efficient Usage of Compute Shaders on Xbox One and PS4
- 1. Efficient usage of compute shaders on Xbox One and PS4 Alexis Vaisse Lead Programmer – Ubisoft Montpellier
- 3. Motion Cloth • Cloth simulation developed by Ubisoft • Used in: 3 / 122
- 4. Agenda • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts – A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 4 / 122
- 5. What is this talk about? • Cloth simulation ported to the GPU • For PC DirectX 11, Xbox One and PS4 5 / 122
- 6. What is this talk about? • Cloth simulation ported to the GPU • For PC DirectX 11, Xbox One and PS4 • This talk is about all that we have learned during this adventure 6 / 122
- 7. 7 / 122
- 8. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 8 / 122
- 9. 9 / 122
- 10. # of dancers Xbox360 34 5 ms of CPU time Why porting a cloth simulation to the GPU? 10 / 122
- 11. # of dancers Xbox360 34 PS3 105 SPUs rock! # of dancers Xbox360 34 5 ms of CPU time Why porting a cloth simulation to the GPU? 11 / 122
- 12. # of dancers Xbox360 34 PS3 105 5 ms of CPU time Why porting a cloth simulation to the GPU? 12 / 122 Now let’s switch to next gen!
- 13. # of dancers Xbox360 34 PS3 105 PS4 98 # of dancers Xbox360 34 PS3 105 5 ms of CPU time WTF? Why porting a cloth simulation to the GPU? 13 / 122
- 14. # of dancers Xbox360 34 PS3 105 PS4 98 # of dancers Xbox360 34 PS3 105 5 ms of CPU time Why porting a cloth simulation to the GPU? 14 / 122 5 SPUs @ 3.2 GHz 6 cores @ 1.6 GHz
- 15. # of dancers Xbox360 34 PS3 105 PS4 98 Xbox One 113 # of dancers Xbox360 34 PS3 105 PS4 98 5 ms of CPU time Why porting a cloth simulation to the GPU? 15 / 122
- 16. 0 20 40 60 80 100 120 Xbox360 PS3 PS4 CPU Xbox One CPU Next gen doesn’t look sexy! Why porting a cloth simulation to the GPU? 16 / 122
- 17. What is the solution? 17 / 122
- 18. 0 200 400 600 800 1000 1200 1400 1600 1800 CPU GPU 0 200 400 600 800 1000 1200 1400 1600 1800 CPU GPU Xbox One PS4 Gflops Gflops Peak power: Why porting a cloth simulation to the GPU? 18 / 122
- 19. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 19 / 122
- 20. Easy to use Not available on all platforms The first attempts 20 / 122
- 21. Easy to use Close to C++ DirectCompute Not available on all platforms Black box: no possibility to know what’s going on The first attempts 21 / 122
- 22. The first attempts Resolve some constraints Integrate velocity Resolve collisions Resolve some more constraints Do some other funny stuffs … 22 / 122
- 23. The first attempts Resolve some constraints Integrate velocity Resolve collisions Resolve some more constraints Do some other funny stuffs … Compute Shader Compute Shader Compute Shader Compute Shader Compute Shader Compute Shader 23 / 122
- 24. The first attempts 0% 20% 40% 60% 80% 100% 120% 140% CPU GPU 5% Too many “Dispatch” 24 / 122
- 25. The first attempts 0% 20% 40% 60% 80% 100% 120% 140% CPU GPU 5% Too many “Dispatch” Bottleneck = CPU 25 / 122
- 26. The first attempts Merge several cloth items to get better performance 0% 20% 40% 60% 80% 100% 120% 140% CPU GPU 27% All cloth items must have the same properties 26 / 122
- 27. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 27 / 122
- 28. A new approach • A single huge compute shader to simulate the entire cloth • Synchronization points inside the shader • A single “Dispatch” instead of 50+ 28 / 122
- 29. A new approach • A single huge compute shader to simulate the entire cloth • Synchronization points inside the shader • A single “Dispatch” instead of 50+ • Simulate several cloth items (up to 32) using a single “Dispatch” 0% 50% 100% 150% 200% CPU GPU 160% 29 / 122
- 30. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 30 / 122
- 31. The shader • 41 .hlsl files • 3,100 lines of code (+ 800 lines for unit tests & benchmarks) • Compiled shader code size = 69 KB 31 / 122
- 32. The shader – Easy parts 0 1 2 3 4 5 63 … • Thread group: • We do the same operation on 64 vertices at a time 32 / 122 There must be no dependency between the threads
- 33. The shader – Easy parts Read some global properties to apply (ex: gravity, wind) Read position of vertex 0 Read position of vertex 1 Read position of vertex 63 … 33 / 122
- 34. The shader – Easy parts Read some global properties to apply (ex: gravity, wind) Read position of vertex 0 Read position of vertex 1 Read position of vertex 63 … Compute Compute Compute … Write position of vertex 0 Write position of vertex 1 Write position of vertex 63 … 34 / 122
- 35. The shader – Easy parts Read some global properties to apply (ex: gravity, wind) Read position of vertex 64 Read position of vertex 65 Read position of vertex 127 … Compute Compute Compute … Write position of vertex 64 Write position of vertex 65 Write position of vertex 127 … 35 / 122
- 36. The shader – Easy parts Read property for vertex 0 Read position of vertex 0 Read position of vertex 1 Read position of vertex 63 … Read property for vertex 1 … Read property for vertex 63 36 / 122
- 37. The shader – Easy parts Read property for vertex 0 Read position of vertex 0 Read position of vertex 1 Read position of vertex 63 … Compute Compute Compute … Write position of vertex 0 Write position of vertex 1 Write position of vertex 63 … Read property for vertex 1 … Read property for vertex 63 37 / 122
- 38. The shader – Easy parts Read property for vertex 0 Read property for vertex 1 … Read property for vertex 63 Ensure contiguous reads to get good performance 38 / 122
- 39. The shader – Easy parts Read property for vertex 0 Read property for vertex 1 … Read property for vertex 63 Ensure contiguous reads to get good performance Coalescing = 1 read instead of 16 i.e. use Structure of Arrays (SoA) instead of Array of Structures (AoS) 39 / 122
- 40. The shader – Complex parts • Binary constraints: Constraint Vertex A Vertex B 40 / 122
- 41. The shader – Complex parts • Binary constraints: 41 / 122
- 42. The shader – Complex parts • Binary constraints: 42 / 122
- 43. The shader – Complex parts • Binary constraints: ? ? ? 43 / 122
- 44. The shader – Complex parts • Binary constraints: 44 / 122
- 45. The shader – Complex parts • Binary constraints: Group 1 45 / 122
- 46. The shader – Complex parts • Binary constraints: Group 1 Group 2 46 / 122
- 47. The shader – Complex parts • Binary constraints: Group 1 Group 2 Group 3 47 / 122
- 48. The shader – Complex parts • Binary constraints: Group 1 Group 2 Group 3 Group 4 GroupMemoryBarrierWithGroupSync() GroupMemoryBarrierWithGroupSync() GroupMemoryBarrierWithGroupSync() 48 / 122
- 49. The shader – Complex parts • Collisions: Easy or not? • Collisions with vertices Easy 49 / 122
- 50. The shader – Complex parts • Collisions: Easy or not? • Collisions with vertices Easy • Collisions with triangles Each thread will modify the position of 3 vertices You have to create groups and add synchronization 50 / 122
- 51. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 51 / 122
- 52. Optimizing the shader • General rule: CPU Vertex 128 bits (4 floats) Bottleneck = memory bandwidth • Data compression: 52 / 122
- 53. Optimizing the shader • General rule: CPU Vertex 128 bits (4 floats) Normal 128 bits (4 floats) Bottleneck = memory bandwidth • Data compression: 53 / 122
- 54. Optimizing the shader • General rule: CPU GPU Vertex 128 bits (4 floats) 64 bits (21:21:21:1) Normal 128 bits (4 floats) Bottleneck = memory bandwidth • Data compression: 54 / 122
- 55. Optimizing the shader • General rule: CPU GPU Vertex 128 bits (4 floats) 64 bits (21:21:21:1) Normal 128 bits (4 floats) 32 bits (10:10:10) 0% 100% 200% 300% GPU - No compression GPU - Compression x2.3 Bottleneck = memory bandwidth • Data compression: 55 / 122
- 56. Optimizing the shader • Use Local Data Storage (aka Local Shared Memory) CU CU CU CU VRAM CU CU CU CU 64 KB LDS Compute Unit (12 on Xbox One, 18 on PS4) 56 / 122
- 57. Optimizing the shader • Store vertices in Local Data Storage 57 / 122 Copy vertices from VRAM to LDS
- 58. Optimizing the shader • Store vertices in Local Data Storage Copy vertices from VRAM to LDS Step 1 – Update vertices Step 2 – Update vertices Step n – Update vertices Copy vertices from LDS to VRAM … 0% 50% 100% 150% 200% VRAM LDS x1.9 58 / 122
- 59. Optimizing the shader • Use bigger thread groups 0 1 2 3 4 5 63 … Load Wait Compute 59 / 122
- 60. Optimizing the shader • Use bigger thread groups 0 1 2 3 4 5 63 … Load Wait Compute Load Wait Compute 60 / 122
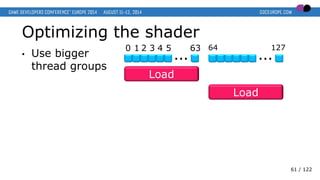
- 61. Optimizing the shader • Use bigger thread groups 0 1 2 3 4 5 63 … 64 127 … Load Load 61 / 122
- 62. Optimizing the shader • Use bigger thread groups 0 1 2 3 4 5 63 … 64 127 … Load Load With 256 or 512 threads, we hide most of the latency! Compute Compute 62 / 122
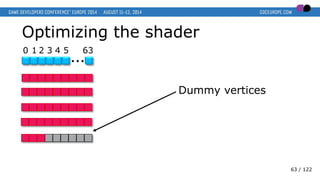
- 63. Optimizing the shader 0 1 2 3 4 5 63 … Dummy vertices 63 / 122
- 64. Optimizing the shader 0 1 2 3 4 5 63 … Dummy vertices = Useless work! 64 / 122
- 65. Optimizing the shader 0 1 2 3 4 5 63 … 64 127 … 65 / 122
- 66. Optimizing the shader 0 1 2 3 4 5 63 … 64 127 … 128 191 … 192 255 … 66 / 122
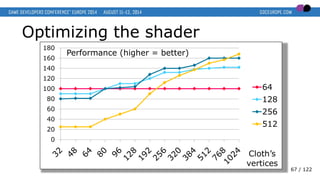
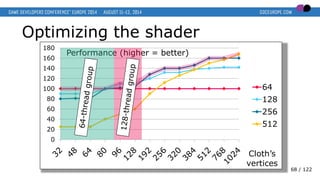
- 67. Optimizing the shader 0 20 40 60 80 100 120 140 160 180 64 128 256 512 Performance (higher = better) Cloth’s vertices 67 / 122
- 68. Optimizing the shader 0 20 40 60 80 100 120 140 160 180 64 128 256 512 Performance (higher = better) Cloth’s vertices 68 / 122
- 69. Optimizing the shader 0 20 40 60 80 100 120 140 160 180 64 128 256 512 Performance (higher = better) Cloth’s vertices 69 / 122
- 70. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 70 / 122
- 71. The PS4 version • Port from HLSL to PSSL #ifdef __PSSL__ #define numthreads NUM_THREADS #define SV_GroupIndex S_GROUP_INDEX #define SV_GroupID S_GROUP_ID #define StructuredBuffer RegularBuffer #define RWStructuredBuffer RW_RegularBuffer #define ByteAddressBuffer ByteBuffer #define RWByteAddressBuffer RW_ByteBuffer #define GroupMemoryBarrierWithGroupSync ThreadGroupMemoryBarrierSync #define groupshared thread_group_memory #endif 71 / 122
- 72. The PS4 version • On DirectX 11: Compute shader Buffer Compute shader Synchronization Buffer CopyResource Synchronization 72 / 122 1 2 3
- 73. Buffer The PS4 version • On DirectX 11: Compute shader Buffer Compute shader Synchronization Buffer CopyResource Synchronization Copy 73 / 122 1 2 3
- 74. The PS4 version • On PS4: No implicit synchronization, no implicit buffer duplication You have to manage everything by yourself Potentially better performance because you know when you have to sync or not 74 / 122
- 75. The PS4 version • We use labels to know if a buffer is still in use by the GPU • Still used Automatically allocate a new buffer • “Used” means used by a compute shader or a copy • We also use labels to know when a compute shader has finished, to copy the results 75 / 122
- 76. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 76 / 122
- 77. What you can do in compute shader 0 200 400 600 800 1000 1200 1400 1600 1800 CPU GPU 0 200 400 600 800 1000 1200 1400 1600 1800 CPU GPU Xbox One PS4 Gflops Gflops Peak power: 77 / 122
- 78. • Using DirectCompute, you can do almost everything in compute shader • The difficulty is to get good performance What you can do in compute shader 78 / 122
- 79. • Efficient code = you work on 64+ data at a time What you can do in compute shader if (threadIndex < 32) { … }; if (threadIndex == 0) { … }; 79 / 122
- 80. • Efficient code = you work on 64+ data at a time What you can do in compute shader if (threadIndex < 32) { … }; if (threadIndex == 0) { … }; // Read the same data on all threads … This is likely to be the bottleneck 80 / 122
- 81. • Example: collisions • On the CPU: What you can do in compute shader Compute a bounding volume (ex: Axis-Aligned Bounding Box) Use it for an early rejection test 81 / 122
- 82. • Example: collisions • On the CPU: What you can do in compute shader Compute a bounding volume (ex: Axis-Aligned Bounding Box) Use it for an early rejection test Use an acceleration structure (ex: AABB Tree) to improve performance 82 / 122
- 83. • Example: collisions • On the GPU: What you can do in compute shader Compute a bounding volume (ex: Axis-Aligned Bounding Box) Just doing this can be more costly than computing the collision with all vertices!!! 83 / 122
- 84. What you can do in compute shader • Compute 64 sub-AABoxes 0 1 2 3 4 5 63 … 84 / 122
- 85. What you can do in compute shader • Compute 64 sub-AABoxes 0 1 2 3 4 5 63 … 85 / 122
- 86. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes 0 1 2 3 4 5 63 … We use only 32 threads for that 86 / 122
- 87. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes 0 1 2 3 4 5 63 … We use only 16 threads for that 87 / 122
- 88. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes • Reduce down to 8 sub-AABoxes 0 1 2 3 4 5 63 … We use only 8 threads for that 88 / 122
- 89. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes • Reduce down to 8 sub-AABoxes • Reduce down to 4 sub-AABoxes 0 1 2 3 4 5 63 … We use only 4 threads for that 89 / 122
- 90. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes • Reduce down to 8 sub-AABoxes • Reduce down to 4 sub-AABoxes • Reduce down to 2 sub-AABoxes 0 1 2 3 4 5 63 … We use only 2 threads for that 90 / 122
- 91. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes • Reduce down to 8 sub-AABoxes • Reduce down to 4 sub-AABoxes • Reduce down to 2 sub-AABoxes • Reduce down to 1 AABox 0 1 2 3 4 5 63 … We use a single thread for that 91 / 122
- 92. What you can do in compute shader • Compute 64 sub-AABoxes • Reduce down to 32 sub-AABoxes • Reduce down to 16 sub-AABoxes • Reduce down to 8 sub-AABoxes • Reduce down to 4 sub-AABoxes • Reduce down to 2 sub-AABoxes • Reduce down to 1 AABox This is ~ as costly as computing the collision with 7 x 64 = 448 vertices!! 92 / 122
- 93. • Atomic functions are available • You can write lock-free thread-safe containers • Too costly in practice What you can do in compute shader 93 / 122
- 94. • Atomic functions are available • You can write lock-free thread-safe containers • Too costly in practice What you can do in compute shader The brute-force approach is almost always the fastest one 94 / 122
- 95. • Atomic functions are available • You can write lock-free thread-safe containers • Too costly in practice What you can do in compute shader The brute-force approach is almost always the fastest one • Bandwidth usage • Data compression • Memory coalescing • LDS usage 95 / 122
- 96. What you can do in compute shader Port an algorithm to the GPU only if you find a way to handle 64+ data at a time 95+% of the time 96 / 122
- 97. • What is this talk about? • Why porting a cloth simulation to the GPU? • The first attempts • A new approach • The shader – Easy parts – Complex parts • Optimizing the shader • The PS4 version • What you can do & cannot do in compute shader • Tips & tricks 97 / 122
- 98. Sharing code between C++ & hlsl #if defined( _WIN32) || defined(_WIN64) || defined(_DURANGO) || defined(__ORBIS__) typedef unsigned long uint; struct float2 { float x, y; }; struct float3 { float x, y, z; }; struct float4 { float x, y, z, w; }; struct uint2 { uint x, y; }; struct uint3 { uint x, y, w; }; struct uint4 { uint x, y, z, w; }; #endif 98 / 122
- 100. Debug buffer struct DebugBuffer { … }; // Uncomment the following line // to use the debug buffer #define USE_DEBUG_BUFFER #ifdef USE_DEBUG_BUFFER RWStructuredBuffer<DebugBuffer> g_DebugBuffer : register(u1); #endif float3 m_Velocity; float m_Weight; 100 / 122
- 101. Debug buffer struct DebugBuffer { … }; // Uncomment the following line // to use the debug buffer #define USE_DEBUG_BUFFER #ifdef USE_DEBUG_BUFFER RWStructuredBuffer<DebugBuffer> g_DebugBuffer : register(u1); #endif float3 m_Velocity; float m_Weight; WRITE_IN_DEBUG_BUFFER(m_Velocity, threadIndex, value); DebugBuffer *debugBuffer = GetDebugBuffer(); 101 / 122
- 102. What to put in LDS? LDS No Random access? Yes 102 / 122
- 103. What to put in LDS? LDS Yes No Yes VRAM Contiguous access No Random access? Accessed several times? 103 / 122
- 104. Memory consumption in LDS 104 / 122 • LDS = 64 KB per compute unit • 1 thread group can access 32 KB
- 105. Memory consumption in LDS 105 / 122 • LDS = 64 KB per compute unit • 1 thread group can access 32 KB 2 thread groups can run simultaneously on the same compute unit 32 32
- 106. Memory consumption in LDS 106 / 122 • LDS = 64 KB per compute unit • 1 thread group can access 32 KB 2 thread groups can run simultaneously on the same compute unit • Less memory used in LDS More thread groups can run in parallel 32 32
- 107. Memory consumption in LDS 107 / 122 • LDS = 64 KB per compute unit • 1 thread group can access 32 KB 2 thread groups can run simultaneously on the same compute unit • Less memory used in LDS More thread groups can run in parallel 32 32 21 21 21 16 16 16 16
- 108. Memory consumption in LDS 108 / 122 • LDS = 64 KB per compute unit • 1 thread group can access 32 KB 2 thread groups can run simultaneously on the same compute unit • Less memory used in LDS More thread groups can run in parallel 32 32 21 21 21 16 16 16 16
- 109. Optimizing bank access in LDS? 109 / 122 • LDS is divided into several banks (16 or 32) • 2 threads accessing the same bank Conflict
- 110. Optimizing bank access in LDS? 110 / 122 • LDS is divided into several banks (16 or 32) • 2 threads accessing the same bank Conflict Visible impact on performance on older PC hardware Negligible on Xbox One, PS4 and newer PC hardware
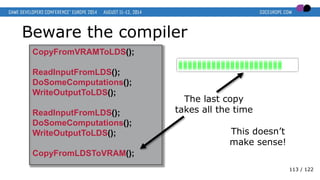
- 113. Beware the compiler CopyFromVRAMToLDS(); ReadInputFromLDS(); DoSomeComputations(); WriteOutputToLDS(); ReadInputFromLDS(); DoSomeComputations(); WriteOutputToLDS(); CopyFromLDSToVRAM(); The last copy takes all the time This doesn’t make sense! 113 / 122
- 115. Optimizing compilation time float3 fanBlades[10]; for (uint i = 0; i < 10; ++i) { Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]); fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position; } float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]); for (uint j = 0; j < 8; ++j) { float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]); uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j); if (isTriangleFilled) normalAccumulator += triangleNormal; } 115 / 122
- 116. Optimizing compilation time float3 fanBlades[10]; for (uint i = 0; i < 10; ++i) { Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]); fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position; } float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]); for (uint j = 0; j < 8; ++j) { float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]); uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j); if (isTriangleFilled) normalAccumulator += triangleNormal; } 116 / 122
- 117. Optimizing compilation time float3 fanBlades[10]; for (uint i = 0; i < 10; ++i) { Vertex fanVertex = GetVertexInLDS(neighborFan.m_VertexIndex[i]); fanBlades[i] = fanVertex.m_Position - fanCenter.m_Position; } float3 normalAccumulator = cross(fanBlades[0], fanBlades[1]); for (uint j = 0; j < 8; ++j) { float3 triangleNormal = cross(fanBlades[j+1], fanBlades[j+2]); uint isTriangleFilled = neighborFan.m_FilledFlags & (1 << j); if (isTriangleFilled) normalAccumulator += triangleNormal; } Shader compilation time Loop 19” Manually unrolled 6” 117 / 122
- 118. Iteration time • It’s really hard to know which code will run the fastest. • The “best” method: • Write 10 versions of your feature. • Test them. • Keep the fastest one. 118 / 122
- 119. Iteration time • It’s really hard to know which code will run the fastest. • The “best” method: • Write 10 versions of your feature. • Test them. • Keep the fastest one. • A fast iteration time really helps 119 / 122
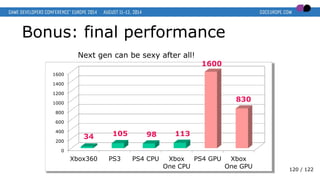
- 120. Bonus: final performance 0 200 400 600 800 1000 1200 1400 1600 Xbox360 PS3 PS4 CPU Xbox One CPU PS4 GPU Xbox One GPU 34 105 98 113 1600 830 Next gen can be sexy after all! 120 / 122
- 121. 121 / 122 PS4 – 2 ms of GPU time – 640 dancers
- 122. Thank you! Questions? 122 / 122