












![ Discovery:
ElasticSearch supports different types of discovery, which in plain words makes multiple ElasticSearch instances talk to each other.
The default type of discovery is multicast where you do not need to configure anything.
multicast doesn’t seem to work on Azure (yet).
Unicast discovery allows to explicitly control which nodes will be used to discover the cluster. It can be used when multicast is not present, or to
restrict the cluster communication-wise.
To work ElasticSearch on azure you need to set below configuration.
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: [“10.0.0.4", “10.0.0.5:9200"]](https://image.slidesharecdn.com/elasticsearchpresentation-141002042626-phpapp01/85/ElasticSearch-Basic-Introduction-15-320.jpg)





![Full Text Search (query string)
In this case you will be searching in bits of natural language for (partially) matching query strings. The Query DSL alternative for
searching for “Boston” in all documents, would look like:
Request :
$ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{
“query": { “query_string": { “query": “boston" }}}’
Response :
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0 },
"hits" : {
"total" : 1,
"max_score" : 6.1357985,
"hits" : [ {
"_index" : "test-data",
"_type" : "cities",
"_id" : "21",
"_score" : 6.1357985, "_source" : {"rank":"21","city":"Boston",...}
} ]
}
}](https://image.slidesharecdn.com/elasticsearchpresentation-141002042626-phpapp01/85/ElasticSearch-Basic-Introduction-21-320.jpg)
![Structured Search (filter)
Structured search is about interrogating data that has inherent structure. Dates, times and numbers are all structured — they have a
precise format that you can perform logical operations on. Common operations include comparing ranges of numbers or dates, or
determining which of two values is larger.
With structured search, the answer to your question is always a yes or no; something either belongs in the set or it does not.
Structured search does not worry about document relevance or scoring — it simply includes or excludes documents.
Request :
$ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{
“query": { “filtered": { “filter ”: { “term": { “city” : “boston“ }}}}}’
$ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty" -d '{
"query": {
"range": {
"population2012": {
"from": 500000,
"to": 1000000
}}}}‘
$ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty" -d '{
"query": { "bool": { "should": [{ "match": { "state": "Texas"} }, {"match": { "state": "California"} }],
"must": { "range": { "population2012": { "from": 500000, "to": 1000000 } } },
"minimum_should_match": 1}}}'](https://image.slidesharecdn.com/elasticsearchpresentation-141002042626-phpapp01/85/ElasticSearch-Basic-Introduction-22-320.jpg)
![Analytics (facets)
Requests of this type will not return a list of matching documents, but a statistical breakdown of the documents.
Elasticsearch has functionality called aggregations, which allows you to generate sophisticated analytics over your data. It is similar to
GROUP BY in SQL.
Request :
$ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{
“aggs": { “all_states": { “terms“: { “field” : “state“ }}}}’
Response :
{
...
"hits": { ... },
"aggregations": {
"all_states": {
"buckets": [
{"key": “massachusetts ", "doc_count": 2},
{ "key": “danbury", "doc_count": 1}
]
}}}](https://image.slidesharecdn.com/elasticsearchpresentation-141002042626-phpapp01/85/ElasticSearch-Basic-Introduction-23-320.jpg)









































More Related Content
What's hot (20)
Similar to ElasticSearch Basic Introduction (20)


















Recently uploaded (20)




















ElasticSearch Basic Introduction
- 2. Easy to scale (Distributed) Everything is one JSON call away (RESTful API) Unleashed power of Lucene under the hood Excellent Query DSL Multi-tenancy Support for advanced search features (Full Text) Configurable and Extensible Document Oriented Schema free Conflict management Active community
- 3. What is elasticsearch? ElasticSearch is a free and open source distributed inverted index created by shay banon. Build on top of Apache Lucene Lucene is a most popular java-based full text search index implementation. First public release version v0.4 in February 2010. Developed in Java, so inherently cross-plateform.
- 4. Easy to Scale (Distributed) Elasticsearch allows you to start small, but will grow with your business. It is built to scale horizontally out of the box. As you need more capacity, just add more nodes, and let the cluster reorganize itself to take advantage of the extra hardware. One server can hold one or more parts of one or more indexes, and whenever new nodes are introduced to the cluster they are just being added to the party. Every such index, or part of it, is called a shard, and Elasticsearch shards can be moved around the cluster very easily. RESTful API Elasticsearch is API driven. Almost any action can be performed using a simple RESTful API using JSON over HTTP. An API already exists in the language of your choice. Responses are always in JSON, which is both machine and human readable.
- 5. Build on top of Apache Lucene Apache Lucene is a high performance, full-featured Information Retrieval library, written in Java. Elasticsearch uses Lucene internally to build its state of the art distributed search and analytics capabilities. Since Lucene is a stable, proven technology, and continuously being added with more features and best practices, having Lucene as the underlying engine that powers Elasticsearch. Excellent Query DSL The REST API exposes a very complex and capable query DSL, that is very easy to use. Every query is just a JSON object that can practically contain any type of query, or even several of them combined. Using filtered queries, with some queries expressed as Lucene filters, helps leverage caching and thus speed up common queries, or complex queries with parts that can be reused. Faceting, another very common search feature, is just something that upon-request is accompanied to search results, and then is ready for you to use.
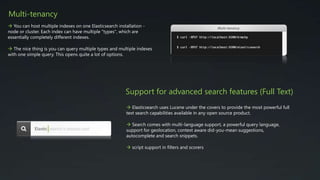
- 6. Multi-tenancy You can host multiple indexes on one Elasticsearch installation - node or cluster. Each index can have multiple "types", which are essentially completely different indexes. The nice thing is you can query multiple types and multiple indexes with one simple query. This opens quite a lot of options. Support for advanced search features (Full Text) Elasticsearch uses Lucene under the covers to provide the most powerful full text search capabilities available in any open source product. Search comes with multi-language support, a powerful query language, support for geolocation, context aware did-you-mean suggestions, autocomplete and search snippets. script support in filters and scorers
- 7. Configurable and Extensible Many of Elasticsearch configurations can be changed while Elasticsearch is running, but some will require a restart (and in some cases reindexing). Most configurations can be changed using the REST API too. Elasticsearch has several extension points - namely site plugins (let you serve static content from ES - like monitoring javascript apps), rivers (for feeding data into Elasticsearch), and plugins that let you add modules or components within Elasticsearch itself. This allows you to switch almost every part of Elasticsearch if so you choose, fairly easily. If you need to create additional REST endpoints to your Elasticsearch cluster, that is easily done as well. Document Oriented Store complex real world entities in Elasticsearch as structured JSON documents. All fields are indexed by default, and all the indices can be used in a single query, to return results at breath taking speed. Per-operation Persistence Elasticsearch puts your data safety first. Document changes are recorded in transaction logs on multiple nodes in the cluster to minimize the chance of any data loss.
- 8. Schema free Elasticsearch allows you to get started easily. Toss it a JSON document and it will try to detect the data structure, index the data and make it searchable. Later, apply your domain specific knowledge of your data to customize how your data is indexed. Conflict management Optimistic version control can be used where needed to ensure that data is never lost due to conflicting changes from multiple processes. Active community The community, other than creating nice tools and plugins, is very helpful and supporting. The overall vibe is really great, and this is an important metric of any OSS project. There are also some books currently being written by community members, and many blog posts around the net sharing experiences and knowledge
- 9. Basic Concepts Cluster : A cluster consists of one or more nodes which share the same cluster name. Each cluster has a single master node which is chosen automatically by the cluster and which can be replaced if the current master node fails. Node : A node is a running instance of elasticsearchwhich belongs to a cluster. Multiple nodes can be started on a single server for testing purposes, but usually you should have one node per server. At startup, a node will use unicast (or multicast, if specified) to discover an existing cluster with the same cluster name and will try to join that cluster. Index : An index is like a ‘database’ in a relational database. It has a mapping which defines multiple types. An index is a logical namespace which maps to one or more primary shards and can have zero or more replica shards. Type : A type is like a ‘table’ in a relational database. Each type has a list of fields that can be specified for documents of that type. The mapping defines how each field in the document is analyzed.
- 10. Basic Concepts Document : A document is a JSON document which is stored in elasticsearch. It is like a row in a table in a relational database. Each document is stored in an index and has a type and an id. A document is a JSON object (also known in other languages as a hash / hashmap / associative array) which contains zero or more fields, or key-value pairs. The original JSON document that is indexed will be stored in the _source field, which is returned by default when getting or searching for a document. Field : A document contains a list of fields, or key-value pairs. The value can be a simple (scalar) value (eg a string, integer, date), or a nested structure like an array or an object. A field is similar to a column in a table in a relational database. The mapping for each field has a field ‘type’ (not to be confused with document type) which indicates the type of data that can be stored in that field, eg integer, string, object. The mapping also allows you to define (amongst other things) how the value for a field should be analyzed. Mapping : A mapping is like a ‘schema definition’ in a relational database. Each index has a mapping, which defines each type within the index, plus a number of index-wide settings. A mapping can either be defined explicitly, or it will be generated automatically when a document is indexed
- 11. Basic Concepts Shard : A shard is a single Lucene instance. It is a low-level “worker” unit which is managed automatically by elasticsearch. An index is a logical namespace which points to primary and replica shards. Elasticsearch distributes shards amongst all nodes in the cluster, and can move shards automatically from one node to another in the case of node failure, or the addition of new nodes. Primary Shard : Each document is stored in a single primary shard. When you index a document, it is indexed first on the primary shard, then on all replicas of the primary shard. By default, an index has 5 primary shards. You can specify fewer or more primary shards to scale the number of documents that your index can handle. Replica Shard : Each primary shard can have zero or more replicas. A replica is a copy of the primary shard, and has two purposes: 1) increase failover: a replica shard can be promoted to a primary shard if the primary fails. 2) increase performance: get and search requests can be handled by primary or replica shards. Identified by index/type/id
- 13. What in a distribution?
- 14. Configuration cluster.name : Cluster name identifies your cluster for auto-discovery. If you're running# multiple clusters on the same network, make sure you're using unique names. node.name : Node names are generated dynamically on startup, so you're relieved# from configuring them manually. You can tie this node to a specific name. node.master & node.data : Every node can be configured to allow or deny being eligible as the master, and to allow or deny to store the data. Master allow this node to be eligible as a master node (enabled by default) and Data allow this node to store data (enabled by default). You can exploit these settings to design advanced cluster topologies. 1. You want this node to never become a master node, only to hold data. This will be the "workhorse" of your cluster. node.master: false, node.data: true 2. You want this node to only serve as a master: to not store any data and to have free resources. This will be the "coordinator" of your cluster. node.master: true, node.data: false 3. You want this node to be neither master nor data node, but to act as a "search load balancer" (fetching data from nodes, aggregating results, etc.) node.master: false, node.data: false Index: You can set a number of options (such as shard/replica options, mapping# or analyzer definitions, translog settings, ...) for indices globally, in this file. Note, that it makes more sense to configure index settings specifically for a certain index, either when creating it or by using the index templates API. example. index.number_of_shards: 5, index.number_of_replicas : 1
- 15. Discovery: ElasticSearch supports different types of discovery, which in plain words makes multiple ElasticSearch instances talk to each other. The default type of discovery is multicast where you do not need to configure anything. multicast doesn’t seem to work on Azure (yet). Unicast discovery allows to explicitly control which nodes will be used to discover the cluster. It can be used when multicast is not present, or to restrict the cluster communication-wise. To work ElasticSearch on azure you need to set below configuration. discovery.zen.ping.multicast.enabled: false discovery.zen.ping.unicast.hosts: [“10.0.0.4", “10.0.0.5:9200"]
- 16. Is it running? http://localhost:9200/?pretty Response : { "status" : 200, "name" : “elasticsearch", "version" : { "number" : "1.1.1", "build_hash" : "f1585f096d3f3985e73456debdc1a0745f512bbc", "build_timestamp" : "2014-04-16T14:27:12Z", "build_snapshot" : false, "lucene_version" : "4.7" }, "tagline" : "You Know, for Search" }
- 17. Indexing a document Request : $ curl -XPUT "http://localhost:9200/test-data/cities/21" -d '{ "rank": 21, "city": "Boston", "state": "Massachusetts", "population2010": 617594, "land_area": 48.277, "location": { "lat": 42.332, "lon": 71.0202 }, "abbreviation": "MA" }‘ Response : {"ok":true,"_index":"test-data","_type":"cities","_id":"21","_version":1}
- 18. Getting a document Request : $ curl -XGET "http://localhost:9200/test-data/cities/21?pretty" Response : { "_index" : "test-data", "_type" : "cities", "_id" : "21", "_version" : 1, "exists" : true, "_source" : { "rank": 21, "city": "Boston", "state": "Massachusetts", "population2010": 617594, "land_area": 48.277, "location": { "lat": 42.332, "lon": 71.0202 }, "abbreviation": "MA" } }
- 19. Updating a document Request : $ curl -XPUT "http://localhost:9200/test-data/cities/21" -d '{ "rank": 21, "city": "Boston", "state": "Massachusetts", "population2010": 617594, "population2012": 636479, "land_area": 48.277, "location": { "lat": 42.332, "lon": 71.0202 }, "abbreviation": "MA" }‘ Response : {"ok":true,"_index":"test-data","_type":"cities","_id":"21","_version":2}
- 20. Searching Search across all indexes and all types http://localhost:9200/_search Search across all types in the test-data index. http://localhost:9200/test-data/_search Search explicitly for documents of type cities within the test-data index. http://localhost:9200/test-data/cities/_search Search explicitly for documents of type cities within the test-data index using paging. http://localhost:9200/test-data/cities/_search?size=5&from=10 There’s 3 different types of search queries Full Text Search (query string) Structured Search (filter) Analytics (facets)
- 21. Full Text Search (query string) In this case you will be searching in bits of natural language for (partially) matching query strings. The Query DSL alternative for searching for “Boston” in all documents, would look like: Request : $ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{ “query": { “query_string": { “query": “boston" }}}’ Response : { "took" : 5, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 6.1357985, "hits" : [ { "_index" : "test-data", "_type" : "cities", "_id" : "21", "_score" : 6.1357985, "_source" : {"rank":"21","city":"Boston",...} } ] } }
- 22. Structured Search (filter) Structured search is about interrogating data that has inherent structure. Dates, times and numbers are all structured — they have a precise format that you can perform logical operations on. Common operations include comparing ranges of numbers or dates, or determining which of two values is larger. With structured search, the answer to your question is always a yes or no; something either belongs in the set or it does not. Structured search does not worry about document relevance or scoring — it simply includes or excludes documents. Request : $ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{ “query": { “filtered": { “filter ”: { “term": { “city” : “boston“ }}}}}’ $ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty" -d '{ "query": { "range": { "population2012": { "from": 500000, "to": 1000000 }}}}‘ $ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty" -d '{ "query": { "bool": { "should": [{ "match": { "state": "Texas"} }, {"match": { "state": "California"} }], "must": { "range": { "population2012": { "from": 500000, "to": 1000000 } } }, "minimum_should_match": 1}}}'
- 23. Analytics (facets) Requests of this type will not return a list of matching documents, but a statistical breakdown of the documents. Elasticsearch has functionality called aggregations, which allows you to generate sophisticated analytics over your data. It is similar to GROUP BY in SQL. Request : $ curl -XGET "http://localhost:9200/test-data/cities/_search?pretty=true" -d '{ “aggs": { “all_states": { “terms“: { “field” : “state“ }}}}’ Response : { ... "hits": { ... }, "aggregations": { "all_states": { "buckets": [ {"key": “massachusetts ", "doc_count": 2}, { "key": “danbury", "doc_count": 1} ] }}}
- 24. ElasticSearch Routing All of your data lives in a primary shard, somewhere in the cluster. You may have five shards or five hundred, but any particular document is only located in one of them. Routing is the process of determining which shard that document will reside in. Elasticsearch has no idea where to look for your document. All the docs were randomly distributed around your cluster. so Elasticsearch has no choice but to broadcasts the request to all shards. This is a non-negligible overhead and can easily impact performance. Wouldn’t it be nice if we could tell Elasticsearch which shard the document lived in? Then you would only have to search one shard to find the document(s) that you need. Routing ensures that all documents with the same routing value will locate to the same shard, eliminating the need to broadcast searches.
- 25. Data Synchronization Elastic search is typically not the primary data store. Implement a queue or use rivers or window service. A river is a pluggable service running within elasticsearch cluster pulling data (or being pushed with data) that is then indexed into the cluster.(https://github.com/jprante/elasticsearch-river-jdbc) Rivers are available for mongodb, couchdb, rabitmq, twitter, wikipedia, mysql, and etc The relational data is internally transformed into structured JSON objects for the schema-less indexing model of Elasticsearch documents. The plugin can fetch data from different RDBMS source in parallel, and multithreaded bulk mode ensures high throughput when indexing to Elasticsearch. Typically we implement worker role as a layer within the application to push data/entities to Elastic search.
- 27. Index Request
- 28. Search Request
- 29. ElasticSearch Monitoring ElasticSearch-Head- https://github.com/mobz/elasticsearch-head Marvel - http://www.elasticsearch.org/guide/en/marvel/current/#_marvel_8217_s_dashboards Paramedic - https://github.com/karmi/elasticsearch-paramedic Bigdesk - https://github.com/lukas-vlcek/bigdesk/
- 30. ElasticSearch vs Solr Feature Parity between ElasticSearch & Solr http://solr-vs-elasticsearch.com/ The Solr and ElasticSearch offerings sound strikingly similar at first sight, and both use the same backend search engine, namely Apache Lucene. While Solr is older, quite versatile and mature and widely used accordingly, ElasticSearch has been developed specifically to address Solr shortcomings with scalability requirements in modern cloud environments, which are hard(er) to address with Solr. ElasticSearch is easier to use and maintain. Solr - not all features are available in Solr Cloud For all practical purposes, there is no real reason to choose Solr over ElasticSearch or vice versa. Both have mature codebases, widespread deployment and are battle-proven. There are of course small variations in the two, such as ElasticSearch's percolation feature, and Solr's Pivot Facets.
- 31. ElasticSearch Limitations Security : ElasticSearch does not provide any authentication or access control functionality. Transactions : There is no much more support for transactions or processing on data manipulation. Durability : ES is distributed and fairly stable but backups and durability are not as high priority as in other data stores Large Computations: Commands for searching data are not suited to "large" scans of data and advanced computation on the db side. Data Availability : ES makes data available in "near real-time" which may require additional considerations in your application (ie: comments page where a user adds new comment, refreshing the page might not actually show the new post because the index is still updating).
- 32. open Source libraries https://github.com/elasticsearch
- 34. Get started. http:// www.elasticsearch.org