JavaScript regular expression
2 likes4,562 views

Presentation used to give an introduction to Regular Expression in JavaScript at MercadoLibre Inc. Spanish: https://www.youtube.com/watch?v=skG03rdOhpo
1 of 33
Downloaded 35 times












![METACHARACTERS
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-13-320.jpg)
![START LINE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-14-320.jpg)
![END LINE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-15-320.jpg)
![ANY CHARACTER EXCEPT END LINE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-16-320.jpg)


![CHOICE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-19-320.jpg)
![ESCAPE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-21-320.jpg)

![GROUP
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-23-320.jpg)

![CLASS
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-25-320.jpg)

![QUANTIFIERS
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-27-320.jpg)
![QUANTIFIER - OPTIONAL
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-28-320.jpg)
![QUANTIFIER - ZERO OR MORE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-29-320.jpg)
![QUANTIFIER - ONE OR MORE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-30-320.jpg)
![QUANTIFIER - RANGE
/ [] - {} () | . * + ? ^ $](https://image.slidesharecdn.com/javascriptregularexpression-141207074309-conversion-gate01/85/JavaScript-regular-expression-31-320.jpg)


Ad
Recommended
Python Programming | JNTUA | UNIT 3 | Lists | 
Python Programming | JNTUA | UNIT 3 | Lists | FabMinds This document contains summaries of several lectures about Python lists. It discusses how lists are sequences that can be indexed and traversed, are mutable unlike strings, and how list operations like slicing, methods, filtering and mapping can be used. It also covers deleting list elements, converting strings to lists, aliasing, passing lists as arguments and checking object references.
How To Use Higher Order Functions in Scala
How To Use Higher Order Functions in ScalaBoldRadius Solutions BoldRadius' Senior Software Developer Alejandro Lujan explains how to use higher order functions in Scala and illustrates them with some examples.
See the accompanying video at www.boldradius.com/blog
Arrayspl
ArraysplJahanzaibRashid1 The document discusses arrays in C programming. It defines an array as a fixed-size collection of elements of the same data type. Arrays allow grouping of like-type data, such as lists of numbers, names, temperatures. Arrays consist of contiguous memory locations. The document describes declaring one-dimensional arrays using syntax like type arrayName[arraySize], and accessing elements using indexes like arrayName[0]. Arrays can be initialized during compilation by specifying values between curly brackets, or initialized at runtime.
Sas array statement
Sas array statementRavi Mandal, MBA The SAS ARRAY statement allows you to group variables together under a single name for processing within a DATA step. The ARRAY statement defines the array name, dimensions, variable names, and optionally initial values. Arrays make it convenient to process multiple variables together using DO loops and array references.
Enumerables
EnumerablesSarah Allen A series of exercises that can be done in irb to understand Ruby's Enumberable methods. Designed to be used in class.
Preparing images for the Web
Preparing images for the Websdireland This document discusses optimizing images for use on the web. It covers choosing the appropriate file type based on the image content, reducing file size through compression and trimming unnecessary pixels, and using tools like Photoshop's "Save for Web" feature to balance image quality and download speed. The key considerations are file type (GIF, JPEG, PNG), size, compression level, and ensuring accessibility.
Regular expressions
Regular expressionsssuser8779cd Regular expressions are patterns used to match character combinations in strings. They are used for search engines, validation, scraping, parsing, and more. Regular expressions use special characters like [], {}, (), | for matching sets, quantities, groups, and alternations. They also have flags like i for case-insensitive matching and g for finding all matches. Common regex tokens include \d, \s, \w for digit, space, word character classes and ., ^, $ for any character, start, end anchors.
Regular expressions
Regular expressionsThomas Langston This document provides an overview of using regular expressions (regex) in Java. It explains that regex allow you to describe and search for patterns in strings. The java.util.regex package includes the Pattern, Matcher, and PatternSyntaxException classes for working with regex in Java. The document then demonstrates various regex syntax like character classes, quantifiers, capturing groups, boundaries and more through code examples.
Regular Expressions: JavaScript And Beyond
Regular Expressions: JavaScript And BeyondMax Shirshin Regular Expressions is a powerful tool for text and data processing. What kind of support do browsers provide for that? What are those little misconceptions that prevent people from using RE effectively?
The talk gives an overview of the regular expression syntax and typical usage examples.
FUNDAMENTALS OF REGULAR EXPRESSION (RegEX).pdf
FUNDAMENTALS OF REGULAR EXPRESSION (RegEX).pdfBryan Alejos Regular expressions (RegEx) are patterns used to match character combinations in strings. They are useful for tasks like validation, parsing, and finding/replacing text. Common RegEx syntax includes special characters for matching characters, word boundaries, repetition, groups, alternation, lookahead/behind. Examples show using RegEx in JavaScript to validate emails, URLs, passwords and extract matches from strings. Most programming languages support RegEx via built-in or library functions.
Chapter Two(1)
Chapter Two(1)bolovv The document discusses scanning (lexical analysis) in compiler construction. It covers the scanning process, regular expressions, and finite automata. The scanning process identifies tokens from source code by categorizing characters as reserved words, special symbols, or other tokens. Regular expressions are used to represent patterns of character strings and define the language of tokens. Finite automata are mathematical models for describing scanning algorithms using states, transitions, and acceptance.
2_2Specification of Tokens.ppt
2_2Specification of Tokens.pptRatnakar Mikkili This document discusses strings, languages, and regular expressions. It defines key terms like alphabet, string, language, and operations on strings and languages. It then introduces regular expressions as a notation for specifying patterns of strings. Regular expressions are defined over an alphabet and can combine symbols, concatenation, union, and Kleene closure to describe languages. Examples are provided to illustrate regular expression notation and properties. Limitations of regular expressions in describing certain languages are also noted.
Java: Regular Expression
Java: Regular ExpressionMasudul Haque This document provides an overview of regular expressions and how they work with patterns and matchers in Java. It defines what a regular expression is, lists common uses of regex, and describes how to create patterns, use matchers to interpret patterns and perform matches, and handle exceptions. It also covers regex syntax like metacharacters, character classes, quantifiers, boundaries, and flags. Finally, it discusses capturing groups, backreferences, index methods, study methods, and replacement methods in the Matcher class.
Ch3
Ch3kinnarshah8888 The document discusses lexical analysis and lexical analyzer generators. It provides background on why lexical analysis is a separate phase in compiler design and how it simplifies parsing. It also describes how a lexical analyzer interacts with a parser and some key attributes of tokens like lexemes and patterns. Finally, it explains how regular expressions are used to specify patterns for tokens and how tools like Lex and Flex can be used to generate lexical analyzers from regular expression definitions.
Chapter2CDpdf__2021_11_26_09_19_08.pdf
Chapter2CDpdf__2021_11_26_09_19_08.pdfDrIsikoIsaac This document discusses lexical analysis and regular expressions. It begins by outlining topics related to lexical analysis including tokens, lexemes, patterns, regular expressions, transition diagrams, and generating lexical analyzers. It then discusses topics like finite automata, regular expressions to NFA conversion using Thompson's construction, NFA to DFA conversion using subset construction, and DFA optimization. The role of the lexical analyzer and its interaction with the parser is also covered. Examples of token specification and regular expressions are provided.
compiler Design course material chapter 2
compiler Design course material chapter 2gadisaAdamu The document provides an overview of lexical analysis in compiler design. It discusses the role of the lexical analyzer in reading characters from a source program and grouping them into lexemes and tokens. Regular expressions are used to specify patterns for tokens. Non-deterministic finite automata (NFA) and deterministic finite automata (DFA) are used to recognize patterns and languages. Thompson's construction is used to translate regular expressions to NFAs, and subset construction is used to translate NFAs to equivalent DFAs. This process is used in lexical analyzer generators to automate the recognition of language tokens from regular expressions.
Regular expressions
Regular expressionsRavinder Singla This document discusses regular expressions and their use in defining the syntax and tokens of a programming language. It provides examples of regular expressions for numeric literals and identifiers. Regular expressions allow the formal definition of the valid strings that make up the tokens in a language by using operators like concatenation, union, closure and more. They are used by scanners in compilers to extract tokens from source code.
Lexical analysis, syntax analysis, semantic analysis. Ppt
Lexical analysis, syntax analysis, semantic analysis. Pptovidlivi91 Lexical analysis is the first phase of compilation where the character stream is converted to tokens. It must be fast. It separates concerns by having a scanner handle tokenization and a parser handle syntax trees. Regular expressions are used to specify patterns for tokens. A regular expression specification can be converted to a finite state automaton and then to a deterministic finite automaton to build a scanner that efficiently recognizes tokens.
Regular Expressions
Regular ExpressionsAkhil Kaushik Regular expressions are a powerful tool for searching, parsing, and modifying text patterns. They allow complex patterns to be matched with simple syntax. Some key uses of regular expressions include validating formats, extracting data from strings, and finding and replacing substrings. Regular expressions use special characters to match literal, quantified, grouped, and alternative character patterns across the start, end, or anywhere within a string.
Facebook Graph Search by Ole martin mørk for jdays2013 Gothenburg www.jdays.se
Facebook Graph Search by Ole martin mørk for jdays2013 Gothenburg www.jdays.sehamidsamadi This document summarizes a presentation about creating graph searches using Neo4j. It includes an agenda that covers introduction to search, Neo4j, parsing, and graph search. It provides examples of using Cypher to query a graph database and define patterns and relationships. It also discusses using parsing expression grammars and the Parboiled library to parse text into a graph structure that can enable graph search capabilities.
Graph search with Neo4j
Graph search with Neo4jOle-Martin Mørk This document provides an overview and agenda for a presentation on creating graph searches using Neo4j. The presentation introduces graph databases and Neo4j, as well as parsing and graph search techniques. It discusses using the Cypher query language to define graph patterns and queries in Neo4j. Examples are provided to illustrate how to model data as nodes and relationships and write Cypher queries to search the graph. The document also briefly covers parsing with PEG grammars and the Parboiled library.
02. chapter 3 lexical analysis
02. chapter 3 lexical analysisraosir123 The document discusses lexical analysis in compiler design. It covers the role of the lexical analyzer, tokenization, and representation of tokens using finite automata. Regular expressions are used to formally specify patterns for tokens. A lexical analyzer generator converts these specifications into a finite state machine (FSM) implementation to recognize tokens in the input stream. The FSM is typically a deterministic finite automaton (DFA) for efficiency, even though a nondeterministic finite automaton (NFA) may require fewer states.
WINSEM2022-23_CSI2005_TH_VL2022230504110_Reference_Material_II_22-12-2022_1.2...
WINSEM2022-23_CSI2005_TH_VL2022230504110_Reference_Material_II_22-12-2022_1.2...Reddyjanardhan221 The document discusses topics related to lexical analysis including:
1. The interaction between the scanner and parser where the scanner identifies tokens and strips whitespace and comments from the source code.
2. Input buffering techniques like buffer pairs and sentinels that allow the scanner to efficiently read character streams from the source code.
3. How regular expressions are used to specify patterns for token definitions in lexical analysis.
Compiler Design in Engineering for Designing
Compiler Design in Engineering for DesigningAdityaverma750841 The compiler is software that converts a program written in a high-level language (Source Language) to a low-level language (Object/Target/Machine Language/0, 1’s).
A translator or language processor is a program that translates an input program written in a programming language into an equivalent program in another language. The compiler is a type of translator, which takes a program written in a high-level programming language as input and translates it into an equivalent program in low-level languages such as machine language or assembly language.
Maxbox starter20
Maxbox starter20Max Kleiner This document provides an introduction to regular expressions (RegEx). It explains that RegEx allows you to find, match, compare or replace text patterns. It then discusses the basic building blocks of RegEx, including characters, character classes, quantifiers, and assertions. It provides several examples of RegEx patterns to match names, words, ports numbers, and other patterns. It concludes with an overview of common RegEx match types like beginning/end of line, word boundaries, grouping, alternatives, and repetition.
Regular Expressions
Regular ExpressionsSatya Narayana Regular expressions allow matching and manipulation of textual data. They were first discovered by mathematician Stephen Kleene and their search algorithm was developed by Ken Thompson in 1968 for use in tools like ed, grep, and sed. Regular expressions follow certain grammars and use meta characters to match patterns in text. They are used for tasks like validation, parsing, and data conversion.
Complier Design - Operations on Languages, RE, Finite Automata
Complier Design - Operations on Languages, RE, Finite AutomataFaculty of Computers and Informatics, Suez Canal University, Ismailia, Egypt Exploring the basics of Operations on Languages (Sets), Regular Expressions (REs), and Finite Automata for Compiler Design subject.
Regular Expressions Cheat Sheet
Regular Expressions Cheat SheetAkash Bisariya This summarizes a regex (regular expression) cheat sheet. It provides definitions and examples of common regex syntax elements including character classes, predefined character classes, boundary matches, logical operations, greedy/reluctant/possessive quantifiers, groups and backreferences, and pattern flags. It also summarizes the key Pattern and Matcher classes and methods in Java for working with regexes.
The prototype property
The prototype propertyHernan Mammana functions, constructor functions, this keyword, instances, prototype, own properties, prototype properties
Spanish video: https://www.youtube.com/watch?v=oq-6rGZkogY
Vender Ropa en MercadoLibre - Mobile First, Progressive Enhancement & RESS
Vender Ropa en MercadoLibre - Mobile First, Progressive Enhancement & RESSHernan Mammana Cuando rediseñamos la experiencia de vender ropa en MercadoLibre se usaron 3 técnicas: Mobile First, Progressive Enhancement y RESS.
More Related Content
Similar to JavaScript regular expression (20)
Regular Expressions: JavaScript And Beyond
Regular Expressions: JavaScript And BeyondMax Shirshin Regular Expressions is a powerful tool for text and data processing. What kind of support do browsers provide for that? What are those little misconceptions that prevent people from using RE effectively?
The talk gives an overview of the regular expression syntax and typical usage examples.
FUNDAMENTALS OF REGULAR EXPRESSION (RegEX).pdf
FUNDAMENTALS OF REGULAR EXPRESSION (RegEX).pdfBryan Alejos Regular expressions (RegEx) are patterns used to match character combinations in strings. They are useful for tasks like validation, parsing, and finding/replacing text. Common RegEx syntax includes special characters for matching characters, word boundaries, repetition, groups, alternation, lookahead/behind. Examples show using RegEx in JavaScript to validate emails, URLs, passwords and extract matches from strings. Most programming languages support RegEx via built-in or library functions.
Chapter Two(1)
Chapter Two(1)bolovv The document discusses scanning (lexical analysis) in compiler construction. It covers the scanning process, regular expressions, and finite automata. The scanning process identifies tokens from source code by categorizing characters as reserved words, special symbols, or other tokens. Regular expressions are used to represent patterns of character strings and define the language of tokens. Finite automata are mathematical models for describing scanning algorithms using states, transitions, and acceptance.
2_2Specification of Tokens.ppt
2_2Specification of Tokens.pptRatnakar Mikkili This document discusses strings, languages, and regular expressions. It defines key terms like alphabet, string, language, and operations on strings and languages. It then introduces regular expressions as a notation for specifying patterns of strings. Regular expressions are defined over an alphabet and can combine symbols, concatenation, union, and Kleene closure to describe languages. Examples are provided to illustrate regular expression notation and properties. Limitations of regular expressions in describing certain languages are also noted.
Java: Regular Expression
Java: Regular ExpressionMasudul Haque This document provides an overview of regular expressions and how they work with patterns and matchers in Java. It defines what a regular expression is, lists common uses of regex, and describes how to create patterns, use matchers to interpret patterns and perform matches, and handle exceptions. It also covers regex syntax like metacharacters, character classes, quantifiers, boundaries, and flags. Finally, it discusses capturing groups, backreferences, index methods, study methods, and replacement methods in the Matcher class.
Ch3
Ch3kinnarshah8888 The document discusses lexical analysis and lexical analyzer generators. It provides background on why lexical analysis is a separate phase in compiler design and how it simplifies parsing. It also describes how a lexical analyzer interacts with a parser and some key attributes of tokens like lexemes and patterns. Finally, it explains how regular expressions are used to specify patterns for tokens and how tools like Lex and Flex can be used to generate lexical analyzers from regular expression definitions.
Chapter2CDpdf__2021_11_26_09_19_08.pdf
Chapter2CDpdf__2021_11_26_09_19_08.pdfDrIsikoIsaac This document discusses lexical analysis and regular expressions. It begins by outlining topics related to lexical analysis including tokens, lexemes, patterns, regular expressions, transition diagrams, and generating lexical analyzers. It then discusses topics like finite automata, regular expressions to NFA conversion using Thompson's construction, NFA to DFA conversion using subset construction, and DFA optimization. The role of the lexical analyzer and its interaction with the parser is also covered. Examples of token specification and regular expressions are provided.
compiler Design course material chapter 2
compiler Design course material chapter 2gadisaAdamu The document provides an overview of lexical analysis in compiler design. It discusses the role of the lexical analyzer in reading characters from a source program and grouping them into lexemes and tokens. Regular expressions are used to specify patterns for tokens. Non-deterministic finite automata (NFA) and deterministic finite automata (DFA) are used to recognize patterns and languages. Thompson's construction is used to translate regular expressions to NFAs, and subset construction is used to translate NFAs to equivalent DFAs. This process is used in lexical analyzer generators to automate the recognition of language tokens from regular expressions.
Regular expressions
Regular expressionsRavinder Singla This document discusses regular expressions and their use in defining the syntax and tokens of a programming language. It provides examples of regular expressions for numeric literals and identifiers. Regular expressions allow the formal definition of the valid strings that make up the tokens in a language by using operators like concatenation, union, closure and more. They are used by scanners in compilers to extract tokens from source code.
Lexical analysis, syntax analysis, semantic analysis. Ppt
Lexical analysis, syntax analysis, semantic analysis. Pptovidlivi91 Lexical analysis is the first phase of compilation where the character stream is converted to tokens. It must be fast. It separates concerns by having a scanner handle tokenization and a parser handle syntax trees. Regular expressions are used to specify patterns for tokens. A regular expression specification can be converted to a finite state automaton and then to a deterministic finite automaton to build a scanner that efficiently recognizes tokens.
Regular Expressions
Regular ExpressionsAkhil Kaushik Regular expressions are a powerful tool for searching, parsing, and modifying text patterns. They allow complex patterns to be matched with simple syntax. Some key uses of regular expressions include validating formats, extracting data from strings, and finding and replacing substrings. Regular expressions use special characters to match literal, quantified, grouped, and alternative character patterns across the start, end, or anywhere within a string.
Facebook Graph Search by Ole martin mørk for jdays2013 Gothenburg www.jdays.se
Facebook Graph Search by Ole martin mørk for jdays2013 Gothenburg www.jdays.sehamidsamadi This document summarizes a presentation about creating graph searches using Neo4j. It includes an agenda that covers introduction to search, Neo4j, parsing, and graph search. It provides examples of using Cypher to query a graph database and define patterns and relationships. It also discusses using parsing expression grammars and the Parboiled library to parse text into a graph structure that can enable graph search capabilities.
Graph search with Neo4j
Graph search with Neo4jOle-Martin Mørk This document provides an overview and agenda for a presentation on creating graph searches using Neo4j. The presentation introduces graph databases and Neo4j, as well as parsing and graph search techniques. It discusses using the Cypher query language to define graph patterns and queries in Neo4j. Examples are provided to illustrate how to model data as nodes and relationships and write Cypher queries to search the graph. The document also briefly covers parsing with PEG grammars and the Parboiled library.
02. chapter 3 lexical analysis
02. chapter 3 lexical analysisraosir123 The document discusses lexical analysis in compiler design. It covers the role of the lexical analyzer, tokenization, and representation of tokens using finite automata. Regular expressions are used to formally specify patterns for tokens. A lexical analyzer generator converts these specifications into a finite state machine (FSM) implementation to recognize tokens in the input stream. The FSM is typically a deterministic finite automaton (DFA) for efficiency, even though a nondeterministic finite automaton (NFA) may require fewer states.
WINSEM2022-23_CSI2005_TH_VL2022230504110_Reference_Material_II_22-12-2022_1.2...
WINSEM2022-23_CSI2005_TH_VL2022230504110_Reference_Material_II_22-12-2022_1.2...Reddyjanardhan221 The document discusses topics related to lexical analysis including:
1. The interaction between the scanner and parser where the scanner identifies tokens and strips whitespace and comments from the source code.
2. Input buffering techniques like buffer pairs and sentinels that allow the scanner to efficiently read character streams from the source code.
3. How regular expressions are used to specify patterns for token definitions in lexical analysis.
Compiler Design in Engineering for Designing
Compiler Design in Engineering for DesigningAdityaverma750841 The compiler is software that converts a program written in a high-level language (Source Language) to a low-level language (Object/Target/Machine Language/0, 1’s).
A translator or language processor is a program that translates an input program written in a programming language into an equivalent program in another language. The compiler is a type of translator, which takes a program written in a high-level programming language as input and translates it into an equivalent program in low-level languages such as machine language or assembly language.
Maxbox starter20
Maxbox starter20Max Kleiner This document provides an introduction to regular expressions (RegEx). It explains that RegEx allows you to find, match, compare or replace text patterns. It then discusses the basic building blocks of RegEx, including characters, character classes, quantifiers, and assertions. It provides several examples of RegEx patterns to match names, words, ports numbers, and other patterns. It concludes with an overview of common RegEx match types like beginning/end of line, word boundaries, grouping, alternatives, and repetition.
Regular Expressions
Regular ExpressionsSatya Narayana Regular expressions allow matching and manipulation of textual data. They were first discovered by mathematician Stephen Kleene and their search algorithm was developed by Ken Thompson in 1968 for use in tools like ed, grep, and sed. Regular expressions follow certain grammars and use meta characters to match patterns in text. They are used for tasks like validation, parsing, and data conversion.
Complier Design - Operations on Languages, RE, Finite Automata
Complier Design - Operations on Languages, RE, Finite AutomataFaculty of Computers and Informatics, Suez Canal University, Ismailia, Egypt Exploring the basics of Operations on Languages (Sets), Regular Expressions (REs), and Finite Automata for Compiler Design subject.
Regular Expressions Cheat Sheet
Regular Expressions Cheat SheetAkash Bisariya This summarizes a regex (regular expression) cheat sheet. It provides definitions and examples of common regex syntax elements including character classes, predefined character classes, boundary matches, logical operations, greedy/reluctant/possessive quantifiers, groups and backreferences, and pattern flags. It also summarizes the key Pattern and Matcher classes and methods in Java for working with regexes.
Complier Design - Operations on Languages, RE, Finite Automata
Complier Design - Operations on Languages, RE, Finite AutomataFaculty of Computers and Informatics, Suez Canal University, Ismailia, Egypt
More from Hernan Mammana (11)
The prototype property
The prototype propertyHernan Mammana functions, constructor functions, this keyword, instances, prototype, own properties, prototype properties
Spanish video: https://www.youtube.com/watch?v=oq-6rGZkogY
Vender Ropa en MercadoLibre - Mobile First, Progressive Enhancement & RESS
Vender Ropa en MercadoLibre - Mobile First, Progressive Enhancement & RESSHernan Mammana Cuando rediseñamos la experiencia de vender ropa en MercadoLibre se usaron 3 técnicas: Mobile First, Progressive Enhancement y RESS.
Javascript coding-and-design-patterns
Javascript coding-and-design-patternsHernan Mammana JavaScript Coding & Design Patterns discusses JavaScript style guides, namespaces, dependencies, dealing with browsers, separation of concerns, DOM scripting, events, functions, and design patterns like the Singleton, Module, and Prototypal Inheritance patterns. It covers topics like hoisting, scope, configuration objects, IIFEs, and using the new keyword and Object.create method for prototypal inheritance. The document provides examples and explanations of these JavaScript concepts and design patterns.
Getting Started with DOM
Getting Started with DOMHernan Mammana The document discusses the Document Object Model (DOM) and its core concepts. It covers how the DOM represents an HTML document as nodes organized in a tree structure, with different node types like elements, text, and attributes. It also describes common DOM manipulation methods for selecting, inserting, and removing nodes to modify the document. Key interfaces and inheritance are explained, along with how to work with different node types, events, and document fragments.
The html5 outline
The html5 outlineHernan Mammana MercadoLibre is every day less requested with the IE7 browser. So in a few months we are going to leave giving support for that specific browser. Now, with a little previous analysis we are able to use the html5shiv tool. I used this slides to explain, share and reflect about how is and works the new HTML5 outline.
This was based on http://www.slideshare.net/hmammana/semantic-markup-creating-outline.
Front End Good Practices
Front End Good PracticesHernan Mammana This document provides a summary of best practices for front-end development. It discusses semantic HTML, CSS organization and specificity, responsive images, JavaScript performance, and other optimization techniques. Key recommendations include writing semantic HTML first before styling, avoiding inline styles, properly structuring CSS with comments and organization, reducing requests by combining files and using sprites, and placing JavaScript before the closing body tag.
Layout
LayoutHernan Mammana This presentation given for developers at Truelogic Software Solutions is about CSS and layouting. It is explained all the ways to re-position an element in the screen.
Tipowebgrafía
TipowebgrafíaHernan Mammana El documento habla sobre la tipografía en la web. Explica que aunque la web comenzó siendo solo texto, el 95% de su contenido aún es texto. Describe las familias tipográficas y cómo se ven afectadas en pantallas como las computadoras, celulares y tabletas. También cubre temas como la estructura semántica del HTML y la jerarquía visual del CSS para diseñar tipografías en la web. Finalmente, anticipa las posibilidades futuras del HTML5 y CSS3 para mejorar el diseño tipográfico en la web.
Semantic markup - Creating Outline
Semantic markup - Creating OutlineHernan Mammana This document discusses semantic markup and outlines. It defines markup languages as systems for annotating documents in a way that is distinguishable from text. Semantic markup uses elements, attributes, and values that have specific predefined meanings. An outline is a list of potentially nested sections. Key HTML elements for outlines include headings (h1-h6) and sectioning elements (article, aside, nav, section). WAI-ARIA adds semantics for accessibility, while Microdata embeds semantics within existing content. Designers must consider accessibility and provide all needed context when labeling elements. Tools like HTML5 Outliner can help with outlines.
Chico JS - Q4 Challenges
Chico JS - Q4 ChallengesHernan Mammana This presentation has been given to the MercadoLibre UX area to update the team the project state. It speaks about the most important challenges in the Q4.
Frontend for developers
Frontend for developersHernan Mammana The document provides information on HTML elements and best practices for frontend development. It discusses the basic structure of HTML with the <html>, <head>, and <body> elements. It also covers common text elements like <p>, <h1>-<h6>, and lists. The document explains how to semantically structure tables and provides examples of the <table>, <tr>, <td>, and <th> elements. It emphasizes writing accessible, valid HTML and separating structure, presentation, and behavior.
Ad
Recently uploaded (20)
Measuring Microsoft 365 Copilot and Gen AI Success
Measuring Microsoft 365 Copilot and Gen AI SuccessNikki Chapple Session | Measuring Microsoft 365 Copilot and Gen AI Success with Viva Insights and Purview
Presenter | Nikki Chapple 2 x MVP and Principal Cloud Architect at CloudWay
Event | European Collaboration Conference 2025
Format | In person Germany
Date | 28 May 2025
📊 Measuring Copilot and Gen AI Success with Viva Insights and Purview
Presented by Nikki Chapple – Microsoft 365 MVP & Principal Cloud Architect, CloudWay
How do you measure the success—and manage the risks—of Microsoft 365 Copilot and Generative AI (Gen AI)? In this ECS 2025 session, Microsoft MVP and Principal Cloud Architect Nikki Chapple explores how to go beyond basic usage metrics to gain full-spectrum visibility into AI adoption, business impact, user sentiment, and data security.
🎯 Key Topics Covered:
Microsoft 365 Copilot usage and adoption metrics
Viva Insights Copilot Analytics and Dashboard
Microsoft Purview Data Security Posture Management (DSPM) for AI
Measuring AI readiness, impact, and sentiment
Identifying and mitigating risks from third-party Gen AI tools
Shadow IT, oversharing, and compliance risks
Microsoft 365 Admin Center reports and Copilot Readiness
Power BI-based Copilot Business Impact Report (Preview)
📊 Why AI Measurement Matters: Without meaningful measurement, organizations risk operating in the dark—unable to prove ROI, identify friction points, or detect compliance violations. Nikki presents a unified framework combining quantitative metrics, qualitative insights, and risk monitoring to help organizations:
Prove ROI on AI investments
Drive responsible adoption
Protect sensitive data
Ensure compliance and governance
🔍 Tools and Reports Highlighted:
Microsoft 365 Admin Center: Copilot Overview, Usage, Readiness, Agents, Chat, and Adoption Score
Viva Insights Copilot Dashboard: Readiness, Adoption, Impact, Sentiment
Copilot Business Impact Report: Power BI integration for business outcome mapping
Microsoft Purview DSPM for AI: Discover and govern Copilot and third-party Gen AI usage
🔐 Security and Compliance Insights: Learn how to detect unsanctioned Gen AI tools like ChatGPT, Gemini, and Claude, track oversharing, and apply eDLP and Insider Risk Management (IRM) policies. Understand how to use Microsoft Purview—even without E5 Compliance—to monitor Copilot usage and protect sensitive data.
📈 Who Should Watch: This session is ideal for IT leaders, security professionals, compliance officers, and Microsoft 365 admins looking to:
Maximize the value of Microsoft Copilot
Build a secure, measurable AI strategy
Align AI usage with business goals and compliance requirements
🔗 Read the blog https://nikkichapple.com/measuring-copilot-gen-ai/
Evaluation Challenges in Using Generative AI for Science & Technical Content
Evaluation Challenges in Using Generative AI for Science & Technical ContentPaul Groth Evaluation Challenges in Using Generative AI for Science & Technical Content.
Foundation Models show impressive results in a wide-range of tasks on scientific and legal content from information extraction to question answering and even literature synthesis. However, standard evaluation approaches (e.g. comparing to ground truth) often don't seem to work. Qualitatively the results look great but quantitive scores do not align with these observations. In this talk, I discuss the challenges we've face in our lab in evaluation. I then outline potential routes forward.
Cognitive Chasms - A Typology of GenAI Failure Failure Modes
Cognitive Chasms - A Typology of GenAI Failure Failure ModesDr. Tathagat Varma My talk on Cognitive Chasms at the brownbag session inside Walmart
Securiport - A Border Security Company
Securiport - A Border Security CompanySecuriport Securiport is a border security systems provider with a progressive team approach to its task. The company acknowledges the importance of specialized skills in creating the latest in innovative security tech. The company has offices throughout the world to serve clients, and its employees speak more than twenty languages at the Washington D.C. headquarters alone.
ELNL2025 - Unlocking the Power of Sensitivity Labels - A Comprehensive Guide....
ELNL2025 - Unlocking the Power of Sensitivity Labels - A Comprehensive Guide....Jasper Oosterveld Sensitivity labels, powered by Microsoft Purview Information Protection, serve as the foundation for classifying and protecting your sensitive data within Microsoft 365. Their importance extends beyond classification and play a crucial role in enforcing governance policies across your Microsoft 365 environment. Join me, a Data Security Consultant and Microsoft MVP, as I share practical tips and tricks to get the full potential of sensitivity labels. I discuss sensitive information types, automatic labeling, and seamless integration with Data Loss Prevention, Teams Premium, and Microsoft 365 Copilot.
Dr Jimmy Schwarzkopf presentation on the SUMMIT 2025 A
Dr Jimmy Schwarzkopf presentation on the SUMMIT 2025 ADr. Jimmy Schwarzkopf Introduction and Background:
Study Overview and Methodology: The study analyzes the IT market in Israel, covering over 160 markets and 760 companies/products/services. It includes vendor rankings, IT budgets, and trends from 2025-2029. Vendors participate in detailed briefings and surveys.
Vendor Listings: The presentation lists numerous vendors across various pages, detailing their names and services. These vendors are ranked based on their participation and market presence.
Market Insights and Trends: Key insights include IT market forecasts, economic factors affecting IT budgets, and the impact of AI on enterprise IT. The study highlights the importance of AI integration and the concept of creative destruction.
Agentic AI and Future Predictions: Agentic AI is expected to transform human-agent collaboration, with AI systems understanding context and orchestrating complex processes. Future predictions include AI's role in shopping and enterprise IT.
6th Power Grid Model Meetup - 21 May 2025
6th Power Grid Model Meetup - 21 May 2025DanBrown980551 6th Power Grid Model Meetup
Join the Power Grid Model community for an exciting day of sharing experiences, learning from each other, planning, and collaborating.
This hybrid in-person/online event will include a full day agenda, with the opportunity to socialize afterwards for in-person attendees.
If you have a hackathon proposal, tell us when you register!
About Power Grid Model
The global energy transition is placing new and unprecedented demands on Distribution System Operators (DSOs). Alongside upgrades to grid capacity, processes such as digitization, capacity optimization, and congestion management are becoming vital for delivering reliable services.
Power Grid Model is an open source project from Linux Foundation Energy and provides a calculation engine that is increasingly essential for DSOs. It offers a standards-based foundation enabling real-time power systems analysis, simulations of electrical power grids, and sophisticated what-if analysis. In addition, it enables in-depth studies and analysis of the electrical power grid’s behavior and performance. This comprehensive model incorporates essential factors such as power generation capacity, electrical losses, voltage levels, power flows, and system stability.
Power Grid Model is currently being applied in a wide variety of use cases, including grid planning, expansion, reliability, and congestion studies. It can also help in analyzing the impact of renewable energy integration, assessing the effects of disturbances or faults, and developing strategies for grid control and optimization.
ECS25 - The adventures of a Microsoft 365 Platform Owner - Website.pptx
ECS25 - The adventures of a Microsoft 365 Platform Owner - Website.pptxJasper Oosterveld My slides for ECS 2025.
Jira Administration Training – Day 1 : Introduction
Jira Administration Training – Day 1 : IntroductionRavi Teja This presentation covers the basics of Jira for beginners. Learn how Jira works, its key features, project types, issue types, and user roles. Perfect for anyone new to Jira or preparing for Jira Admin roles.
Data Virtualization: Bringing the Power of FME to Any Application
Data Virtualization: Bringing the Power of FME to Any ApplicationSafe Software Imagine building web applications or dashboards on top of all your systems. With FME’s new Data Virtualization feature, you can deliver the full CRUD (create, read, update, and delete) capabilities on top of all your data that exploit the full power of FME’s all data, any AI capabilities. Data Virtualization enables you to build OpenAPI compliant API endpoints using FME Form’s no-code development platform.
In this webinar, you’ll see how easy it is to turn complex data into real-time, usable REST API based services. We’ll walk through a real example of building a map-based app using FME’s Data Virtualization, and show you how to get started in your own environment – no dev team required.
What you’ll take away:
-How to build live applications and dashboards with federated data
-Ways to control what’s exposed: filter, transform, and secure responses
-How to scale access with caching, asynchronous web call support, with API endpoint level security.
-Where this fits in your stack: from web apps, to AI, to automation
Whether you’re building internal tools, public portals, or powering automation – this webinar is your starting point to real-time data delivery.
Microsoft Build 2025 takeaways in one presentation
Microsoft Build 2025 takeaways in one presentationDigitalmara Microsoft Build 2025 introduced significant updates. Everything revolves around AI. DigitalMara analyzed these announcements:
• AI enhancements for Windows 11
By embedding AI capabilities directly into the OS, Microsoft is lowering the barrier for users to benefit from intelligent automation without requiring third-party tools. It's a practical step toward improving user experience, such as streamlining workflows and enhancing productivity. However, attention should be paid to data privacy, user control, and transparency of AI behavior. The implementation policy should be clear and ethical.
• GitHub Copilot coding agent
The introduction of coding agents is a meaningful step in everyday AI assistance. However, it still brings challenges. Some people compare agents with junior developers. They noted that while the agent can handle certain tasks, it often requires supervision and can introduce new issues. This innovation holds both potential and limitations. Balancing automation with human oversight is crucial to ensure quality and reliability.
• Introduction of Natural Language Web
NLWeb is a significant step toward a more natural and intuitive web experience. It can help users access content more easily and reduce reliance on traditional navigation. The open-source foundation provides developers with the flexibility to implement AI-driven interactions without rebuilding their existing platforms. NLWeb is a promising level of web interaction that complements, rather than replaces, well-designed UI.
• Introduction of Model Context Protocol
MCP provides a standardized method for connecting AI models with diverse tools and data sources. This approach simplifies the development of AI-driven applications, enhancing efficiency and scalability. Its open-source nature encourages broader adoption and collaboration within the developer community. Nevertheless, MCP can face challenges in compatibility across vendors and security in context sharing. Clear guidelines are crucial.
• Windows Subsystem for Linux is open-sourced
It's a positive step toward greater transparency and collaboration in the developer ecosystem. The community can now contribute to its evolution, helping identify issues and expand functionality faster. However, open-source software in a core system also introduces concerns around security, code quality management, and long-term maintenance. Microsoft’s continued involvement will be key to ensuring WSL remains stable and secure.
• Azure AI Foundry platform hosts Grok 3 AI models
Adding new models is a valuable expansion of AI development resources available at Azure. This provides developers with more flexibility in choosing language models that suit a range of application sizes and needs. Hosting on Azure makes access and integration easier when using Microsoft infrastructure.
Grannie’s Journey to Using Healthcare AI Experiences
Grannie’s Journey to Using Healthcare AI ExperiencesLauren Parr AI offers transformative potential to enhance our long-time persona Grannie’s life, from healthcare to social connection. This session explores how UX designers can address unmet needs through AI-driven solutions, ensuring intuitive interfaces that improve safety, well-being, and meaningful interactions without overwhelming users.
Cybersecurity Fundamentals: Apprentice - Palo Alto Certificate
Cybersecurity Fundamentals: Apprentice - Palo Alto CertificateVICTOR MAESTRE RAMIREZ Cybersecurity Fundamentals: Apprentice - Palo Alto Certificate
Protecting Your Sensitive Data with Microsoft Purview - IRMS 2025
Protecting Your Sensitive Data with Microsoft Purview - IRMS 2025Nikki Chapple Session | Protecting Your Sensitive Data with Microsoft Purview: Practical Information Protection and DLP Strategies
Presenter | Nikki Chapple (MVP| Principal Cloud Architect CloudWay) & Ryan John Murphy (Microsoft)
Event | IRMS Conference 2025
Format | Birmingham UK
Date | 18-20 May 2025
In this closing keynote session from the IRMS Conference 2025, Nikki Chapple and Ryan John Murphy deliver a compelling and practical guide to data protection, compliance, and information governance using Microsoft Purview. As organizations generate over 2 billion pieces of content daily in Microsoft 365, the need for robust data classification, sensitivity labeling, and Data Loss Prevention (DLP) has never been more urgent.
This session addresses the growing challenge of managing unstructured data, with 73% of sensitive content remaining undiscovered and unclassified. Using a mountaineering metaphor, the speakers introduce the “Secure by Default” blueprint—a four-phase maturity model designed to help organizations scale their data security journey with confidence, clarity, and control.
🔐 Key Topics and Microsoft 365 Security Features Covered:
Microsoft Purview Information Protection and DLP
Sensitivity labels, auto-labeling, and adaptive protection
Data discovery, classification, and content labeling
DLP for both labeled and unlabeled content
SharePoint Advanced Management for workspace governance
Microsoft 365 compliance center best practices
Real-world case study: reducing 42 sensitivity labels to 4 parent labels
Empowering users through training, change management, and adoption strategies
🧭 The Secure by Default Path – Microsoft Purview Maturity Model:
Foundational – Apply default sensitivity labels at content creation; train users to manage exceptions; implement DLP for labeled content.
Managed – Focus on crown jewel data; use client-side auto-labeling; apply DLP to unlabeled content; enable adaptive protection.
Optimized – Auto-label historical content; simulate and test policies; use advanced classifiers to identify sensitive data at scale.
Strategic – Conduct operational reviews; identify new labeling scenarios; implement workspace governance using SharePoint Advanced Management.
🎒 Top Takeaways for Information Management Professionals:
Start secure. Stay protected. Expand with purpose.
Simplify your sensitivity label taxonomy for better adoption.
Train your users—they are your first line of defense.
Don’t wait for perfection—start small and iterate fast.
Align your data protection strategy with business goals and regulatory requirements.
💡 Who Should Watch This Presentation?
This session is ideal for compliance officers, IT administrators, records managers, data protection officers (DPOs), security architects, and Microsoft 365 governance leads. Whether you're in the public sector, financial services, healthcare, or education.
🔗 Read the blog: https://nikkichapple.com/irms-conference-2025/
Kubernetes Cloud Native Indonesia Meetup - May 2025
Kubernetes Cloud Native Indonesia Meetup - May 2025Prasta Maha Kubernetes Cloud Native Indonesia Meetup - May 2025
Offshore IT Support: Balancing In-House and Offshore Help Desk Technicians
Offshore IT Support: Balancing In-House and Offshore Help Desk Techniciansjohn823664 In today's always-on digital environment, businesses must deliver seamless IT support across time zones, devices, and departments. This SlideShare explores how companies can strategically combine in-house expertise with offshore talent to build a high-performing, cost-efficient help desk operation.
From the benefits and challenges of offshore support to practical models for integrating global teams, this presentation offers insights, real-world examples, and key metrics for success. Whether you're scaling a startup or optimizing enterprise support, discover how to balance cost, quality, and responsiveness with a hybrid IT support strategy.
Perfect for IT managers, operations leads, and business owners considering global help desk solutions.
End-to-end Assurance for SD-WAN & SASE with ThousandEyes
End-to-end Assurance for SD-WAN & SASE with ThousandEyesThousandEyes End-to-end Assurance for SD-WAN & SASE with ThousandEyes
Improving Developer Productivity With DORA, SPACE, and DevEx
Improving Developer Productivity With DORA, SPACE, and DevExJustin Reock Ready to measure and improve developer productivity in your organization?
Join Justin Reock, Deputy CTO at DX, for an interactive session where you'll learn actionable strategies to measure and increase engineering performance.
Leave this session equipped with a comprehensive understanding of developer productivity and a roadmap to create a high-performing engineering team in your company.
UiPath Community Berlin: Studio Tips & Tricks and UiPath Insights
UiPath Community Berlin: Studio Tips & Tricks and UiPath InsightsUiPathCommunity Join the UiPath Community Berlin (Virtual) meetup on May 27 to discover handy Studio Tips & Tricks and get introduced to UiPath Insights. Learn how to boost your development workflow, improve efficiency, and gain visibility into your automation performance.
📕 Agenda:
- Welcome & Introductions
- UiPath Studio Tips & Tricks for Efficient Development
- Best Practices for Workflow Design
- Introduction to UiPath Insights
- Creating Dashboards & Tracking KPIs (Demo)
- Q&A and Open Discussion
Perfect for developers, analysts, and automation enthusiasts!
This session streamed live on May 27, 18:00 CET.
Check out all our upcoming UiPath Community sessions at:
👉 https://community.uipath.com/events/
Join our UiPath Community Berlin chapter:
👉 https://community.uipath.com/berlin/
Nix(OS) for Python Developers - PyCon 25 (Bologna, Italia)
Nix(OS) for Python Developers - PyCon 25 (Bologna, Italia)Peter Bittner How do you onboard new colleagues in 2025? How long does it take? Would you love a standardized setup under version control that everyone can customize for themselves? A stable desktop setup, reinstalled in just minutes. It can be done.
This talk was given in Italian, 29 May 2025, at PyCon 25, Bologna, Italy. All slides are provided in English.
Original slides at https://slides.com/bittner/pycon25-nixos-for-python-developers
Ad
JavaScript regular expression
- 1. GETTING STARTED JavaScript Regular Expression REFERENCES Douglas Crockford, JavaScript: The Good Parts Jan Goyvaerts and Steven Levithan, Regular Expression Cookbook Stoyan Stefanov, Object-Oriented JavaScript
- 2. INTRODUCTION
- 3. INTRODUCTION • A regular expression is a specific kind of text pattern. • JavaScript’s Regular Expression feature was borrowed from Perl. • You can use it with many methods: • match, replace, search, split in strings • exec, test in regular expresion object
- 4. CONSTRUCTION
- 5. LITERAL var re = //;
- 6. LITERAL var re = /pattern/;
- 7. LITERAL var re = /pattern/flags;
- 8. LITERAL var re = /pattern/flags;
- 9. CONSTRUCTOR var re = new RegExp();
- 10. CONSTRUCTOR var re = new RegExp(pattern);
- 11. CONSTRUCTOR var re = new RegExp(pattern, flags);
- 12. ELEMENTS
- 13. METACHARACTERS / [] - {} () | . * + ? ^ $
- 14. START LINE / [] - {} () | . * + ? ^ $
- 15. END LINE / [] - {} () | . * + ? ^ $
- 16. ANY CHARACTER EXCEPT END LINE / [] - {} () | . * + ? ^ $
- 17. SEQUENCE
- 18. FACTOR
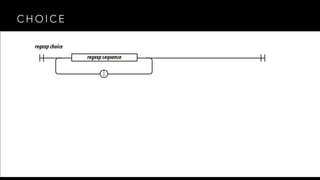
- 19. CHOICE / [] - {} () | . * + ? ^ $
- 20. CHOICE
- 21. ESCAPE / [] - {} () | . * + ? ^ $
- 22. ESCAPE
- 23. GROUP / [] - {} () | . * + ? ^ $
- 24. GROUP
- 25. CLASS / [] - {} () | . * + ? ^ $
- 26. CLASS
- 27. QUANTIFIERS / [] - {} () | . * + ? ^ $
- 28. QUANTIFIER - OPTIONAL / [] - {} () | . * + ? ^ $
- 29. QUANTIFIER - ZERO OR MORE / [] - {} () | . * + ? ^ $
- 30. QUANTIFIER - ONE OR MORE / [] - {} () | . * + ? ^ $
- 31. QUANTIFIER - RANGE / [] - {} () | . * + ? ^ $
- 32. QUANTIFIER
- 33. THANKS