






















![機械学習の世界の分類
l 問題設定に基づく分類
l 教師有学習 / 教師無学習 / 半教師有学習 / 強化学習 など ..
l 戦うドメインの違い
l 特徴設計屋(各ドメイン毎に, NLP, Image, Bio, Music)
l 学習アルゴリズム屋(SVM, xx Bayes, CW, …)
l 理理論論屋(統計的学習理理論論、経験過程、Regret最⼩小化)
l 最適化実装屋
l 好みの違い
l Bayesian / Frequentist / Connectionist
l [Non-|Semi-]Parametric
24
この⼆二つの問題設定だけは
知っておいてほしいので説明](https://image.slidesharecdn.com/20130602jubatusmltutorial-130601232741-phpapp01/85/Jubatus-Casual-Talks-24-320.jpg)






































![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=560&fit=bounds)







More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to 機械学習チュートリアル@Jubatus Casual Talks (20)











![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=560&fit=bounds)








More from Yuya Unno (20)




















機械学習チュートリアル@Jubatus Casual Talks
- 1. 機械学習チュートリアル 株式会社Preferred Infrastructure 海野 裕也 (@unnonouno) 2013/06/02 Jubatus Casual Talks #1
- 2. ⾃自⼰己紹介 l 海野 裕也 (@unnonouno) l プリファードインフラストラクチャー l 情報検索索、レコメンド l 機械学習・データ解析研究開発 l Jubatus l 分散オンライン機械学習フレームワーク l 専⾨門 l ⾃自然⾔言語処理理 l テキストマイニング 2
- 7. 概要 本チュートリアルではデータを解析して判断に活かすため の技術、機械学習を説明します l 機械学習ってどこで使われてるの? l 機械学習が得意・不不得意な条件って? l 機械学習って裏裏で何してるの? 7
- 8. 注意 l 初めて機械学習を聞いた⼈人向けです l 数式を使いません l 分散の話はしません l ガチな⼈人は寝てて下さい 8
- 9. 機械学習って何? 9
- 10. 機械学習とは l 経験(データ)によって賢くなるアルゴリズムの研究 l データから知識識・ルールを⾃自動獲得する l データの適切切な表現⽅方法も獲得する l ⼈人⼯工知能の中で、⼈人が知識識やルールを 明⽰示的に与える⽅方法の限界から⽣生まれてきた 10 学習データ 分類モデル
- 13. 例例3:コンピュータ将棋・囲碁・チェス 13 http://blog.livedoor.jp/yss_fpga/archives/53897129.html 詳細は鶴岡慶雅先生のチュートリアル 「自然言語処理とAI」 l ゲームごとに機械学習の応⽤用⼿手法が次々に進歩 l 機械の性能改善以上に⼿手法の改善が⽬目覚ましい 強い 弱い
- 14. 様々な分野に適⽤用可能 l データから有⽤用な規則、ルール、知識識、判断基準を抽出 l データがあるところならば、どこでも使える l 様々な分野の問題に利利⽤用可能 14 レコメンデー ションクラス タリング 分類、識識別 市場予測 評判分析 情報抽出 ⽂文字認識識 ロボット 画像解析 遺伝⼦子分析 検索索ランキン グ ⾦金金融 医療療診断 適用分野
- 15. ⼈人に⽐比べて機械学習のここがいい! l ⼤大量量 l ⼤大量量に処理理できる l 機械を並べればいくらでもスケールする l ⾼高速 l ⼈人間の反応速度度を超えることができる l ⾼高精度度 l 場合によっては⼈人間を凌凌駕するようになってきた l ⼈人と違って判断がブレない、疲れない 15
- 16. 機械学習を活かすポイント 量量と速度度が圧倒的なポイント l 量量 l ⼤大量量のデータが有って⼈人⼿手で処理理できない l 情報源が多様すぎて⼈人間では⼿手に負えない l 速度度 l ⼈人間よりも圧倒的に⾼高速に反応できる l 反応速度度が重要な領領域で価値が出る 16 いずれも⼀一般的に機械が ⼈人間より優っているポイント
- 17. 機械学習が失敗するパターン l できない精度度を求める l サイコロの次の⽬目を当てることはできない l 同じように、精度度の限界がある l ⼈人にとって簡単なタスクをやろうとする l 少ない情報から推論論するのは⼈人間が得意 l 逆に⼤大量量の情報から判断する必要がある時は機械が得意 l ボトルネックが別にある l アクションを取るのが⼈人だったり、⼈人が途中に介在する l 量量と速度度のメリットをいかに活かすか 17
- 18. 「機械にやらせるなら、ルールを書けばいいんじゃ ないの?」 l 俗にルールベースと呼ばれる⽅方法 l 最初は精度度が悪いが頑張れば意外とどこまでも良良くなる 18 「ゴルフ」 à スポーツ 「インテル」 à コンピュータ 「選挙」 à 政治
- 19. ルールに基づく判断の限界 l ⼈人⼿手で書いたルールはすぐ複雑、膨⼤大になる l 1万⾏行行のperlスクリプト l どこを変えたらいいかわからない l 条件を追加したら何が起こるか・・・ l 複雑化したルールは引き継げなくなる 19 「ゴルフ」and「VW」 à ⾞車車 「インテル」and「⻑⾧長友」 à サッカー 「選挙」and「AKB」 à 芸能
- 20. ルールの管理理よりもデータの管理理を! l ルールは必ず管理理できなくなる l 膨⼤大なルール l 妥当性がわからない l この条件なんだっけ・・・? l ⼤大事なのはデータ! l データの正しさは⼈人間に判断できる l 間違えたら間違えたデータを教えれば良良い l ルールは適⽤用できなくなるが、データは変わらない l 「スイカ」が「⻄西⽠瓜」から「Suica」になる⽇日・・・ 20
- 22. まとめ:機械学習 vs ⼈人間 vs ルール l 機械学習は速度度、量量、精度度、メンテナンス性のバランス がとれている l ⼈人間に⽐比べて・・ l 量量と速度度に優る l 疲れない、ぶれない、スケールする l ルールに⽐比べて l 精度度に優る l メンテナンスできる、引き継げる、データの変化に強い 22
- 23. 機械学習って何してるの? 23
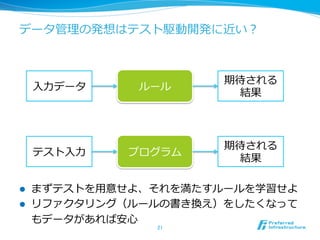
- 24. 機械学習の世界の分類 l 問題設定に基づく分類 l 教師有学習 / 教師無学習 / 半教師有学習 / 強化学習 など .. l 戦うドメインの違い l 特徴設計屋(各ドメイン毎に, NLP, Image, Bio, Music) l 学習アルゴリズム屋(SVM, xx Bayes, CW, …) l 理理論論屋(統計的学習理理論論、経験過程、Regret最⼩小化) l 最適化実装屋 l 好みの違い l Bayesian / Frequentist / Connectionist l [Non-|Semi-]Parametric 24 この⼆二つの問題設定だけは 知っておいてほしいので説明
- 25. 教師有り学習 l ⼊入⼒力力 x に対して期待される出⼒力力 y を教える l 分析時には未知の x に対応する y を予測する l 分類 l y がカテゴリの場合 l スパム判定、記事分類、属性推定、etc. l 回帰 l y が実数値の場合 l 電⼒力力消費予測、年年収予測、株価予測、etc. 25 x y
- 26. 教師無し学習 l ⼊入⼒力力 x をたくさん与えると、⼊入⼒力力情報⾃自体の性質に関し て何かしらの結果を返す l クラスタリング l 与えられたデータをまとめあげる l 異異常検知 l ⼊入⼒力力データが異異常かどうかを判定する 26 x
- 28. 教師有り学習と教師無し学習は⽬目的が違う 教師有り学習 l ⼊入出⼒力力の対応関係を学んで、 未知の⼊入⼒力力に対して判断する l ⼊入⼒力力と出⼒力力を教える必要があ る l ⼀一番シンプルな問題設定で汎 ⽤用性が⾼高い 教師無し学習 l データ集合⾃自体の特徴を学習 する l データをとにかく⼊入れれば、 すぐ動く l 制御が難しく実⽤用上は⼤大変 l 教師あり学習の前処理理として も使われる 28 こっちだけ詳しく説明します
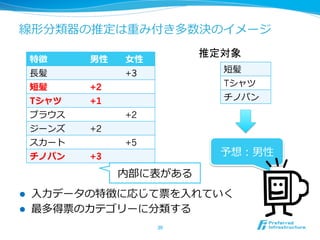
- 30. 線形分類器の推定は重み付き多数決のイメージ l ⼊入⼒力力データの特徴に応じて票を⼊入れていく l 最多得票のカテゴリーに分類する 30 特徴 男性 ⼥女女性 ⻑⾧長髪 +3 短髪 +2 Tシャツ +1 ブラウス +2 ジーンズ +2 スカート +5 チノパン +3 短髪 Tシャツ チノパン 予想:男性 推定対象 内部に表がある
- 31. 学習のステップ 1/3 l どれが重要かわからないので、全ての重みを更更新する l 結果的に、このデータは正しく予想できるようになる 31 特徴 男性 ⼥女女性 ⻑⾧長髪 0 à +1 短髪 Tシャツ 0 à +1 ブラウス ジーンズ スカート チノパン 0 à +1 ⻑⾧長髪 Tシャツ チノパン 学習データ 男性 初期値は全部0
- 32. 学習のステップ 2/4 l 間違えるたびに正しく分類できるように更更新 32 特徴 男性 ⼥女女性 ⻑⾧長髪 +1 à 0 短髪 Tシャツ +1 ブラウス 0 à +1 ジーンズ スカート 0 à +1 チノパン +1 ⻑⾧長髪 ブラウス スカート 学習データ ⼥女女性
- 33. 学習のステップ 3/4 l 何度度も更更新する 33 特徴 男性 ⼥女女性 ⻑⾧長髪 0 à +1 短髪 Tシャツ +1 à 0 ブラウス +1 ジーンズ スカート +1 à +2 チノパン +1 ⻑⾧長髪 Tシャツ スカート 学習データ ⼥女女性
- 34. 学習のステップ 4/4 l 最終的にうまく分類できるところで落落ち着く l 縦が数万〜~数百万になり、⼈人が全部調整するのは不不可能 34 特徴 男性 ⼥女女性 ⻑⾧長髪 +3 短髪 +2 Tシャツ +1 ブラウス +2 ジーンズ +2 スカート +5 チノパン +3 できた!
- 35. 機械学習を更更に発展させる l より効率率率よく更更新する l オンライン学習 l アンサンブル学習 l より⼤大規模なデータを利利⽤用する l 分散して学習 l 半教師有り学習 l より複雑な特徴を利利⽤用する l 深層学習 l カーネル法 35 Jubatusは、特にオンライ ン学習と分散処理理に注⼒力力
- 36. まとめ:機械学習の仕組み l ⼀一⼝口に機械学習といっても⾊色々 l ⼊入出⼒力力、設定、⽬目標、好き嫌い、様々 l 教師ありなし l あり:⼊入出⼒力力関係を学習する l なし:データの性質を学習する l 線形分類器は重み付き多数決 36
- 38. l NTT SIC*とPreferred Infrastructureによる共同開発 l 2011年年10⽉月よりOSSで公開 http://jubat.us/ Jubatus 38 リアルタイム ストリーム 分散並列列 深い解析 * NTT研究所 サイバーコミュニケーション研究所 ソフトウェアイノベーションセンタ
- 39. 「緩いモデル共有」による分散の仕組み l みんな個別に⾃自学⾃自習 l たまに勉強会で情報交換 l ⼀一⼈人で勉強するより効率率率がいいはず! 39 学習器 オンライン学習 分散処理理