









![【参考】Robust PCA: ADMMによる最適化
min
𝑈,𝑅
𝑈 ∗ + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅
n ADMMでは拡張ラグランジュ関数を使う。
𝐿 𝑈, 𝑅, 𝑍 = 𝑈 ∗ + 𝜆 𝑅 1 + tr 𝑍 𝑈 + 𝑅 − 𝑋 +
𝛽
2
𝑈 + 𝑅 − 𝑋 F
2
以下の3ステップを収束するまで繰り返す。
• 𝑈[𝑡+1] ← argmin 𝑈 𝐿 𝑈, 𝑅[𝑡], 𝑍[𝑡]
- 主変数その1の更新:二乗ロス + トレースノルムなので、SVDで解ける。
• 𝑅[𝑡+1] ← argmin 𝑅 𝐿 𝑈[𝑡+1], 𝑅, 𝑍[𝑡]
- 主変数その2の更新:二乗ロス + L1ノルムなので、解析的に解ける(soft-thresholding)。
• 𝑍[𝑡+1] ← 𝑍[𝑡] + 𝛽(𝑈[𝑡+1] + 𝑅[𝑡+1] − 𝑋)
- 双対変数𝑍を勾配法で更新。
11](https://image.slidesharecdn.com/harakdd17171007share-171007135622/85/KDD-17-Anomaly-Detection-with-Robust-Deep-Autoencoders-11-320.jpg)
![Robust PCAと外れ値検知
n Robust PCAでは低ランク行列𝑈とノイズ行列𝑅を同時推定する。
n ノイズの値が大きいデータ点𝑥(𝑛)が外れ値と言える。
n 例:動画の各フレームを背景(低ランク要素)と
外れ値の要因(動体)へと分解。
n [引用元] Emmanuel J. Candes, Xiaodong Li, Yi Ma,
John Wright. "Robust Principal Component Analysis?”,
2009.
12](https://image.slidesharecdn.com/harakdd17171007share-171007135622/85/KDD-17-Anomaly-Detection-with-Robust-Deep-Autoencoders-12-320.jpg)

![Autoencoder(自己符号化器)
n 入力を一旦低次元に落としてから再度復元する深層ネットワーク
• Encoder:入力𝑥 ∈ ℝ 𝑝を低次元表現𝑦 ∈ ℝ 𝑞に
非線形変換する(𝑞 < 𝑝)。
𝑦 = Enc(𝑥)
• Decoder:低次元表現𝑦から入力𝑥を復元する。
𝑥 ≈ Dec(𝑦)
- Enc, Decは適当な非線形関数(線形変換+ReLUなど)
14
[引用元] Wikipedia
https://ja.wikipedia.org/wi
ki/オートエンコーダ](https://image.slidesharecdn.com/harakdd17171007share-171007135622/85/KDD-17-Anomaly-Detection-with-Robust-Deep-Autoencoders-14-320.jpg)
















![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=560&fit=bounds)




![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=560&fit=bounds)










More Related Content
What's hot (20)
Similar to KDD'17読み会:Anomaly Detection with Robust Deep Autoencoders (20)


















More from Satoshi Hara (12)












KDD'17読み会:Anomaly Detection with Robust Deep Autoencoders
- 1. Anomaly Detection with Robust Deep Autoencoders Chong Zhou, Randy C. Paffenroth Worcester Polytechnic Institute 1 原 聡 大阪大学 産業科学研究所 KDD2017勉強会@京大, 2017/10/7
- 2. 論文の概要 n 外れ値検知のためのRobust Autoencoderを提案。 n 基本的なアイディア • 入力データを”正常な要素”と”異常要因”とに分解する。 • “異常要因”の成分が大きいデータが外れ値。 n 手法概要 • 各データ𝑥 ∈ ℝ 𝑝は正常な要素𝑢 ∈ ℝ 𝑝と異常要因𝑟 ∈ ℝ 𝑝の和に分解できるとする: 𝑥 = 𝑢 + 𝑟 - 正常な要素𝑢の学習 - 正常な要素はAutoencoderで適切に復元できる: 𝑢 ≈ 𝑓𝜃 𝑢 - 異常要因𝑟の検出 - 外れ値は異常要因𝑟を差っ引いてあげれば残ったデータが正常になる: 𝑥 − 𝑟 ≈ 𝑓𝜃 𝑥 − 𝑟 • データセット𝐷 = {𝑥(𝑛)}から正常な要素𝑈 = {𝑢(𝑛)} 、異常要因𝑅 = {𝑟(𝑛)} 、 Autoencoder𝑓𝜃を同時に学習する。 2
- 3. この論文を読んだ理由 n Deepの勉強 • 最近、深層学習の研究に興味が出てきたので、この機会にタイトルに”Deep”が入って いる論文を探して読んでみた。 n 異常検知技術の動向調査 • 最近、あまり異常検知関連の研究をしていなかったので、近年の動向を知りたくて読ん でみた。 n 自身の研究との関連 • 『入力データを”正常な要素”と”異常要因”とに分解する』というアプローチを過去の自 身の研究(量子情報データの異常検知)で使ったことがある。そのDeep版という、ある 種の拡張ということで興味があって読んでみた。 3
- 4. この論文を読んだ感想 n Deepの勉強 • 最近、深層学習の研究に興味が出てきたので、この機会にタイトルに”Deep”が入って いる論文を探して読んでみた。 → 期待したほどDeepである必然性がなかった。 n 異常検知技術の動向調査 • 最近、あまり異常検知関連の研究をしていなかったので、近年の動向を知りたくて読ん でみた。 → Isolation Forestしか他の異常検知手法に言及してなかったので、不完全燃焼。 n 自身の研究との関連 • 『入力データを”正常な要素”と”異常要因”とに分解する』というアプローチを過去の自 身の研究(量子情報データの異常検知)で使ったことがある。そのDeep版という、ある 種の拡張ということで興味があって読んでみた。 → 素直な拡張、という感じだったので、機会があったら使ってみてもいいかも。 4
- 5. ちなみに n 2017/4/22にほぼ同じ内容の論文が他のグループからarXivに投稿されている。 Raghavendra Chalapathy, Aditya Krishna Menon, Sanjay Chawla. “Robust, Deep and Inductive Anomaly Detection”, arXiv:1704.06743. 5
- 6. 目次 n Robust PCAと外れ値検知 n Autoencoerと外れ値検知 n 提案法:Robust Autoencoder n 実験結果 6
- 7. 目次 n Robust PCAと外れ値検知 n Autoencoerと外れ値検知 n 提案法:Robust Autoencoder n 実験結果 7
- 8. PCA n PCAには様々な定式化がある。 n 代表例:低次元への射影と、そこからの復元誤差の最小化 • データ行列𝑋 ∈ ℝ 𝑛×𝑝を低次元空間へと射影(𝑌 = 𝑋𝑊 ∈ ℝ 𝑛×𝑞)して、そこから再構 成する(𝑋 ≈ 𝑌𝑊⊤) 。 min 𝑊 𝑋 − 𝑋𝑊𝑊⊤ 2 , s. t. 𝑊⊤ 𝑊 = 𝐼. 8
- 9. PCA n 他の定式化例:データ行列 𝑋 ∈ ℝ 𝑛×𝑝 を最もよく近似する低ランク行列 𝑈 を求める。 min 𝑈 𝑋 − 𝑈 2 , s. t. rank 𝑈 = 𝑘. • または min 𝑈 𝑋 − 𝑈 2 + 𝜌rank 𝑈 . • 凸緩和 min 𝑈 𝑋 − 𝑈 2 + 𝜌 𝑈 ∗. 9
- 10. Robust PCA n データ行列𝑋 ∈ ℝ 𝑛×𝑝 に加法的なスパイクノイズがのっている状況を想定。スパイ クノイズの影響を除去した上で、低ランク行列𝑈を求める。 • ノイズにスパース性を仮定:低ランク行列𝑈とノイズ行列𝑅の同時推定 min 𝑈,𝑅 𝑈 ∗ + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅 • 凸最適なので、例えばADMMで解ける。 n 参考 • Emmanuel J. Candes, Xiaodong Li, Yi Ma, John Wright. "Robust Principal Component Analysis?”, 2009. 10
- 11. 【参考】Robust PCA: ADMMによる最適化 min 𝑈,𝑅 𝑈 ∗ + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅 n ADMMでは拡張ラグランジュ関数を使う。 𝐿 𝑈, 𝑅, 𝑍 = 𝑈 ∗ + 𝜆 𝑅 1 + tr 𝑍 𝑈 + 𝑅 − 𝑋 + 𝛽 2 𝑈 + 𝑅 − 𝑋 F 2 以下の3ステップを収束するまで繰り返す。 • 𝑈[𝑡+1] ← argmin 𝑈 𝐿 𝑈, 𝑅[𝑡], 𝑍[𝑡] - 主変数その1の更新:二乗ロス + トレースノルムなので、SVDで解ける。 • 𝑅[𝑡+1] ← argmin 𝑅 𝐿 𝑈[𝑡+1], 𝑅, 𝑍[𝑡] - 主変数その2の更新:二乗ロス + L1ノルムなので、解析的に解ける(soft-thresholding)。 • 𝑍[𝑡+1] ← 𝑍[𝑡] + 𝛽(𝑈[𝑡+1] + 𝑅[𝑡+1] − 𝑋) - 双対変数𝑍を勾配法で更新。 11
- 12. Robust PCAと外れ値検知 n Robust PCAでは低ランク行列𝑈とノイズ行列𝑅を同時推定する。 n ノイズの値が大きいデータ点𝑥(𝑛)が外れ値と言える。 n 例:動画の各フレームを背景(低ランク要素)と 外れ値の要因(動体)へと分解。 n [引用元] Emmanuel J. Candes, Xiaodong Li, Yi Ma, John Wright. "Robust Principal Component Analysis?”, 2009. 12
- 13. 目次 n Robust PCAと外れ値検知 n Autoencoerと外れ値検知 n 提案法:Robust Autoencoder n 実験結果 13
- 14. Autoencoder(自己符号化器) n 入力を一旦低次元に落としてから再度復元する深層ネットワーク • Encoder:入力𝑥 ∈ ℝ 𝑝を低次元表現𝑦 ∈ ℝ 𝑞に 非線形変換する(𝑞 < 𝑝)。 𝑦 = Enc(𝑥) • Decoder:低次元表現𝑦から入力𝑥を復元する。 𝑥 ≈ Dec(𝑦) - Enc, Decは適当な非線形関数(線形変換+ReLUなど) 14 [引用元] Wikipedia https://ja.wikipedia.org/wi ki/オートエンコーダ
- 15. Autoencoderの学習 n Encoder: 𝑦 = Enc(𝑥) n Decoder: 𝑥 ≈ Dec(𝑦) n Autoencoderを関数𝑓𝜃: ℝ 𝑝 → ℝ 𝑝 とする。 • 𝑓𝜃 = Dec ∘ Enc • 𝜃は関数のパラメータ。 n Minibatch-SGDによる最適化 • 学習のロス関数𝑙𝑜𝑠𝑠(𝑥, 𝑓𝜃(𝑥))を定義する。 • ランダムに𝑀個のトレーニングデータで勾配𝛻𝜃 𝑙𝑜𝑠𝑠(𝑥 𝑚 , 𝑓𝜃(𝑥 𝑚 ))を計算 - 勾配はbackpropagationで計算 • 𝜃 ← 𝜃 − 𝜂 𝑀 ∑ 𝛻𝜃 𝑙𝑜𝑠𝑠(𝑥 𝑚 , 𝑓𝜃(𝑥 𝑚 ))𝑚 15
- 16. 非線形PCAとしてのAutoencoder n PCAの定式化の一例:データ行列𝑋 ∈ ℝ 𝑛×𝑝 を低次元空間へと射影(𝑌 = 𝑋𝑊 ∈ ℝ 𝑛×𝑞 )して、そこから再構成する(𝑋 ≈ 𝑌𝑊⊤ ) 。 min 𝑊 𝑋 − 𝑋𝑊𝑊⊤ 2 , s. t. 𝑊⊤ 𝑊 = 𝐼. n 低次元への射影をEnc、再構成をDecとすると、上の式は二乗ロスを使った Autoencoderの学習問題に一致する。 min 𝜃 𝑋 − 𝑓𝜃(𝑋) 2, where 𝑓𝜃 = Dec ∘ Enc • AutoencoderはPCAを非線形変換へと一般化したものだと言える。 16
- 17. Autoencoderと外れ値検知 n 外れ値のない、正常なデータだけのデータセット𝐷でAutoencoderを学習する、i.e., 𝑥 ≈ 𝑓𝜃 𝑥 , ∀𝑥 ∈ 𝐷. n 学習した𝑓𝜃に新しい入力𝑥∗ を入力した時、一般には、出力𝑓𝜃(𝑥∗ )と𝑥∗ は十分似て いることが期待される。 • しかし、時に入力と出力が大きく異なる場合がある。どんな時か? n 𝑥∗ がデータセット𝐷の分布から外れている場合に、 𝑓𝜃(𝑥∗ )と𝑥∗ とは大きく異なるこ とがある。 • つまり、𝑓𝜃で入力𝑥∗の再構成誤差を測ると入力の外れ値度合いが測れる。 n 注意:この方法は、正常なデータだけの綺麗なデータセットがあることが前提。元 のデータセットに含まれる外れ値は検知できない。 17
- 18. 目次 n Robust PCAと外れ値検知 n Autoencoerと外れ値検知 n 提案法:Robust Autoencoder n 実験結果 18
- 19. Autoencoderを使った外れ値検知 n 今までのAutoencoderを使った外れ値検知は、正常なデータだけの綺麗なデータ セットがあることが前提だった。元のデータセットに含まれる外れ値は検知できな い。 n では、綺麗なデータがない場合は?データの中の外れ値をどうやったら検知でき るか? n 重要なObservation • Robust PCAを使えば、データの中の外れ値が検知できる。 - 推定されたノイズ行列の値が大きい要素が外れ値に対応。 • AutoencoderはPCAの非線形への一般化である。 → Robust PCAを非線形へと一般化してRobust Autoencoderにすればデータの中の 外れ値も検知できるようになるのでは!? 19
- 20. 提案法:Robust Autoencoder n Robust PCA(再掲) min 𝑈,𝑅 𝑈 ∗ + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅 n Robust Autoencoder • Robust PCAの第一項を再構成誤差に変更。 min 𝑈,𝑅,𝜃 𝑈 − 𝑓𝜃(𝑈) F 2 + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅 • データ行列𝑋から正常な要素の行列𝑈 、ノイズ成分𝑅 、正常要素を再構成する Autoencoder𝑓𝜃を同時に学習する。 20
- 21. Robust Autoencoderの学習アルゴリズム min 𝑈,𝑅,𝜃 𝑈 − 𝑓𝜃(𝑈) F 2 + 𝜆 𝑅 1, s. t. 𝑋 = 𝑈 + 𝑅 n 交互最適化ステップ1: 𝑅を固定して𝑓𝜃を最適化する。 • 𝑅を固定すると𝑈が決まるので、 𝑓𝜃の学習は通常のAutoencoderの学習に一致。 • Minibatch-SGDで最適化する。 n 交互最適化ステップ2: 𝑓𝜃を固定して𝑅を最適化する。 • 𝑈 − 𝑓𝜃 𝑈 = 𝑋 − 𝑓𝜃 𝑈 − 𝑅なので、以下の最適化を解く。 min 𝑅 𝑅 − (𝑋 − 𝑓𝜃 𝑈 ) F 2 + 𝜆 𝑅 1 • これはL1のproximity operatorなので解析的に計算できる。 21
- 22. 目次 n Robust PCAと外れ値検知 n Autoencoerと外れ値検知 n 提案法:Robust Autoencoder n 実験結果 22
- 23. MNISTによるRobust Autoencoderの性能検証実験 n MNIST:0から9までの手書き数字、28 x 28の白黒画像データ n 実験1:Robust Autoendoerと普通のAutoencoderの比較 • MNIST画像にランダムなピークノイズを負荷。 • 得られた中間表現+ラベルでRandom Forestによる分類モデルを学習。 • テストデータでの分類性能を比較。 n 実験2:Robust Autoencoderを使った外れ値検知 • 4の画像に少しだけ他の数字の画像を混入させる。 • 混入された画像がきちんと外れ値として検知できるかを検証。 23
- 24. MNISTによるRobust Autoencoderの性能検証実験 n MNIST:0から9までの手書き数字、28 x 28の白黒画像データ n 実験1:Robust Autoendoerと普通のAutoencoderの比較 • MNIST画像にランダムなピークノイズを負荷。 • 得られた中間表現+ラベルでRandom Forestによる分類モデルを学習。 • テストデータでの分類性能を比較。 n 実験2:Robust Autoencoderを使った外れ値検知 • 4の画像に少しだけ他の数字の画像を混入させる。 • 混入された画像がきちんと外れ値として検知できるかを検証。 24
- 25. 実験1:Robust Autoendoerと普通のAutoencoderの比較 n 正則化パラメータの値と ノイズレベルを色々と変えて 比較実験 • ノイズ中の時に提案法が有効 n 実験設定(再掲) • MNIST画像にランダムな ピークノイズを負荷。 • 得られた中間表現+ラベルで Random Forestによる 分類モデルを学習。 • テストデータでの分類性能を 比較。 25
- 26. MNISTによるRobust Autoencoderの性能検証実験 n MNIST:0から9までの手書き数字、28 x 28の白黒画像データ n 実験1:Robust Autoendoerと普通のAutoencoderの比較 • MNIST画像にランダムなピークノイズを負荷。 • 得られた中間表現+ラベルでRandom Forestによる分類モデルを学習。 • テストデータでの分類性能を比較。 n 実験2:Robust Autoencoderを使った外れ値検知 • 4の画像に少しだけ他の数字の画像を混入させる。 • 混入された画像がきちんと外れ値として検知できるかを検証。 26
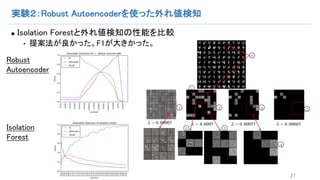
- 27. 実験2:Robust Autoencoderを使った外れ値検知 n Isolation Forestと外れ値検知の性能を比較 • 提案法が良かった。F1が大きかった。 27 Robust Autoencoder Isolation Forest
- 28. まとめ n 従来のAutoencoderでは、データセット内の外れ値は検知できなかった。 n 外れ値検知のためのRobust Autoencoderを提案。 • PCAをRobust PCAに拡張する流れをAutoencoderに適用。 • 交互最適化による学習方法を提案。 n MNIST実験でRobust Autoencoderの有効性を検証。 n コード: https://github.com/zc8340311/RobustAutoencoder 28