The Earthscope
• TheEarthscope is the world's largest science project.
• Designed to track North America's geological evolution, this
observatory records data over 3.8 million square miles, amassing
67 terabytes of data.
• It analyzes seismic slips in the San Andreas fault, sure, but also
the plume of magma underneath Yellowstone and much, much
more.
(http://www.msnbc.msn.com/id/44363598/ns/technology_and_s
cience-future_of_technology/#.TmetOdQ--uI)
Dr. Madhuri J
Big data -Definition
■Big data is a collection of data sets so large and complex that it becomes difficult to
process using on-hand database management tools
■ The challenges include capture, storage, search, sharing, analysis, and visualization.
Dr. Madhuri J
9.
Big Data: Adefinition
■ Put another way, big data is the realization of greater business intelligence by
storing, processing, and analyzing data that was previously ignored due to the
limitations of traditional data management technologies
Source: Harness the Power of Big Data: The IBM Big Data Platform
10.
Type of Data
■Relational Data (Tables/Transaction/Legacy Data)
■ Text Data (Web)
■ Semi-structured Data (XML)
■ Graph Data
– Social Network, Semantic Web (RDF), …
■ Streaming Data
– You can only scan the data once
11.
Who’s Generating BigData
■ The progress and innovation is no longer hindered by the ability to collect data
■ But, by the ability to manage, analyze, summarize, visualize, and discover
knowledge from the collected data in a timely manner and in a scalable fashion
Social media and networks
(all of us are generating data)
Scientific instruments
(collecting all sorts of data)
Mobile devices
(tracking all objects all the time)
Sensor technology and networks
(measuring all kinds of data)
Characteristics of BigData:
1-Scale (Volume)
■ Data Volume
– 44x increase from 2009 2020
– From 0.8 zettabytes to 35zb
■ Data volume is increasing exponentially
13
Exponential increase in
collected/generated data
14.
•A typical PCmight have had 10 gigabytes of storage in 2000.
•Today, Face book ingests 500 terabytes of new data every day.
•Boeing 737 will generate 240 terabytes of flight data during a single flight across
the US.
•The smart phones, the data they create and consume; sensors embedded into
everyday objects will soon result in billions of new, constantly-updated data feeds
containing environmental, location, and other information, including video.
Dr. Madhuri J
15.
Characteristics of BigData:
2-Complexity (Varity)
■ Various formats, types, and structures
■ Text, numerical, images, audio, video,
sequences, time series, social media
data, multi-dim arrays, etc…
■ Static data vs. streaming data
■ A single application can be
generating/collecting many types of
data
15
To extract knowledge all these types of
data need to linked together
Dr. Madhuri J
16.
■ Big Dataisn't just numbers, dates, and strings. Big
Data is also geospatial data, 3D data, audio and video,
and unstructured text, including log files and social
media.
■ Traditional database systems were designed to
address smaller volumes of structured data, fewer
updates or a predictable, consistent data structure.
■ Big Data analysis includes different types of data
17.
Characteristics of BigData:
3-Speed (Velocity)
■ Data is begin generated fast and need to be
processed fast
■ Online Data Analytics
■ Late decisions missing opportunities
■ Examples
– E-Promotions: Based on your current location, your purchase history, what
you like send promotions right now for store next to you
– Healthcare monitoring: sensors monitoring your activities and body any
abnormal measurements require immediate reaction
17
18.
■ Click streamsand ad impressions capture user behavior at millions of
events per second
■ high-frequency stock trading algorithms reflect market changes within
microseconds
■ machine to machine processes exchange data between billions of devices
■ infrastructure and sensors generate massive log data in real-time
■ on-line gaming systems support millions of concurrent users, each
producing multiple inputs per second.
19.
Big Data isa Hot Topic Because Technology
Makes it Possible to Analyze ALL Available Data
Cost effectively manage and analyze all available data in its native form unstructured, structured,
streaming
20.
Big Data
■ Canyou think of running a query on 20,980,000 GB file.
■ Email users send more than 204 million messages;
■ Mobile Web receives 217 new users;
■ Google receives over 2 million search queries;
■ YouTube users upload 48 hours of new video;
■ Facebook users share 684,000 bits of content;
■ Twitter users send more than 100,000 tweets;
21.
What is BigData
■ Collection of data sets so large and complex that it becomes difficult to
process using on-hand database management tools or traditional data
processing applications .
■ Big Data generates value from the storage and processing of very large
quantities of digital information that cannot be analyzed with traditional
computing techniques.
■ Traditional database systems were designed to address smaller volumes
of structured data, fewer updates or a predictable, consistent data
structure. Big Data analysis includes different types of data
Hadoop
■ Hadoop isopen source software.
■ Hadoop is a platform/framework
Which allows the user to quickly write and test distributed systems
Which is efficient in automatically distributing the data and work across machines
25.
Hadoop!
■ Created byDoug Cutting
■ Started as a module in nutch and then matured as an apache project
■ Named it after his son's stuffed elephant
25
26.
■ Apache toplevel project, open-source implementation of frameworks for reliable,
scalable, distributed computing and data storage.
■ It is a flexible and highly-available architecture for large scale computation and data
processing on a network of commodity hardware.
■ Designed to answer the question: “How to process big data with reasonable cost
and time?”
26
27.
What we’ve gotin Hadoop
■ Fault-tolerant file system
■ Hadoop Distributed File System (HDFS)
■ Modeled on Google File system
■ Takes computation to data
■ Data Locality
■ Scalability:
– Program remains same for 10, 100, 1000,… nodes
– Corresponding performance improvement
■ Parallel computation using MapReduce
■ Other components – Pig, Hbase, HIVE, ZooKeeper
27
28.
Hadoop
■ HDFS andMapReduce are two core components of Hadoop
HDFS:
■ Hadoop Distributed File System
■ makes our job easy to store the data on commodity hardware
■ Built to expect hardware failures
■ Intended for large files & batch inserts
MapReduce
■ For parallel processing
29.
RDBMS compared toMapReduce
Traditional RDBMS MapReduce
Data size Gigabytes Petabytes
Access Interactive and batch Batch
Updates Read and write many
times Write once
Read many times
Transactions ACID None
Structure Schema-on-write Schema-on-read
Integrity High Low
Scaling Nonlinear Linear
30.
Grid Computing
■ Thehigh-performance computing (HPC) and grid computing
communities have been doing large-scale data processing for
years, using such application program interfaces (APIs) as the
Message Passing Interface (MPI).
■ This works well for predominantly compute-intensive jobs, but
it becomes a problem when nodes need to access larger data
volumes.
■ MPI gives great control to programmers.
■ Hadoop tries to co-locate the data with the compute nodes, so
data access is fast because it is local. This feature, known as
data locality
31.
■ Coordinating theprocesses in a large-scale distributed computation is a
challenge.
■ Distributed processing frameworks like MapReduce has the
implementation that detects failed tasks and reschedules replacements on
machines that are healthy.
■ MapReduce is able to do this because it is a shared-nothing architecture,
meaning that tasks have no dependence on one other.
Dr. Madhuri J
32.
Volunteer Computing
■ Volunteersdonate CPU time from their otherwise idle computers to analyze radio
telescope data for signs of intelligent life outside Earth. SETI@home is the most
well known of many volunteer computing projects.
■ Volunteer computing projects work by breaking the problems they are trying to
solve into chunks called work units, which are sent to computers around the world
to be analyzed.
■ When the analysis is completed, the results are sent back to the server, and the
client gets another work unit.
■ The SETI@home problem is very CPU-intensive, which makes it suitable for
running on hundreds of thousands of computers across the world because the time
to transfer the work unit is dwarfed by the time to run the computation on it.
Dr. Madhuri J
MapReduce
A distributeddata processing model and execution environment that runs
on large clusters of commodity machines.
Can be used with Java, Ruby, Python, C++ and more
Inherently parallel, thus putting very large-scale data analysis into the
hands of anyone with enough machines at their disposal
Weather Dataset
Weather sensors collect data every hour at many locations across the globe
and gather a large volume of log data.
The data we will use is from the National Climatic Data Center, or NCDC.
The data is stored using a line-oriented ASCII format, in which each line
is a record.
■ Mission -calculate max temperature each year around the
world
■ Problem - millions of temperature measurements records
■ Challenges
– The file size for different years varies widely, so some processes
will finish much earlier than others. A better approach, is to
split the input into fixed-size chunks and assign each chunk to a
process.
– combining the results from independent processes may require
further processing as data for a particular year will typically
be split into several chunks, each processed independently.
– When we start using multiple machines, a whole host of other
factors come into play, mainly falling into the categories of
coordination and reliability. Who runs the overall job? How do
we deal with failed processes?
38.
Example: Weather Dataset
BruteForce approach – Bash:
(each year’s logs are compressed to a single yearXXXX.gz file)
■ The complete run for the century took 42 minutes in one run on a single EC2 High-CPU Extra
Large Instance.
39.
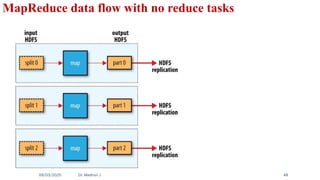
Analyzing the Datawith Hadoop MapReduce
■ MapReduce works by breaking the processing into two phases: the map phase
and the reduce phase.
■ The input to our map phase is the raw NCDC data. We choose a text input
format that gives us each line in the dataset as a text value. The key is the offset
of the beginning of the line from the beginning of the file.
■ Only air temperature and year data is required to find the maximum
temperature in every year.
40.
Map Function
■ Theraw dataset are presented to the map function as the key-value pairs:
■ The map function merely extracts the year and the air temperature (indicated
in bold text), and emits them as its output:
41.
■ This processingsorts and groups the key-value pairs by key. So, continuing the
example, our reduce function sees the following input:
Each year appears with a list of all its air temperature readings. All the reduce
function has to do now is iterate through the list and pick up the maximum
reading:
MapReduce logical data flow
Scaling Out
■ Toscale out, we need to store the data in a distributed filesystem (HDFS).
■ This allows Hadoop to move the MapReduce computation to each machine hosting a
part of the data, using Hadoop’s resource management system, called YARN
■ Data Flow
■ A MapReduce job is a unit of work that the client wants to be performed: it consists of the input
data, the MapReduce program, and configuration
■ Hadoop runs the job by dividing it into tasks, of which there are two types:
– map tasks and reduce tasks.
■ Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits, or just
splits.
■ If we are processing the splits in parallel, the processing is better load balanced when the splits are
small.
■ On the other hand, if splits are too small, the overhead of managing the splits and map task
creation begins to dominate the total job execution time
44.
■ For mostjobs, a good split size tends to be the size of an HDFS block, which is 128 MB by
default.
■ Hadoop does its best to run the map task on a node where the input data resides in HDFS,
because it doesn’t use valuable cluster bandwidth. This is called the data locality
optimization.
Data-local (a), rack-local (b), and off-rack (c) map tasks
■ Map taskswrite their output to the local disk, not to HDFS.
■ Map output is intermediate output: it’s processed by reduce tasks to produce
the final output, and once the job is complete, the map output can be thrown
away.
■ Reduce tasks don’t have the advantage of data locality; the input to a single
reduce task is normally the output from all mappers.
■ The sorted map outputs have to be transferred across the network to the node
where the reduce task is running.
■ They are merged and then passed to the user-defined reduce function.
■ The output of the reduce is normally stored in HDFS for reliability.
MapReduce
• There aretwo types of nodes that control the job execution
process: a jobtracker and a number of tasktrackers.
• Jobtracker - coordinates all the jobs run on the system by
scheduling tasks to run on tasktrackers.
• Tasktrackers - run tasks and send progress reports to the
jobtracker, which keeps a record of the overall progress of each
job.
Job Tracker
Task Tracker Task Tracker Task Tracker
Dr. Madhuri J
52.
Hadoop Streaming
■ Hadoopprovides an API to MapReduce that allows you to
write your map and reduce functions in languages other than
Java.
■ Hadoop Streaming uses Unix standard streams as the interface
between Hadoop and your program
■ Map input data is passed over standard input to your map
function, which processes it line by line and writes lines to
standard output.
■ A map output key-value pair is written as a single tab-
delimited line.
■ The reduce function reads lines from standard input, sorted by
key, and writes its results to standard output.
52
Dr. Madhuri J
Hadoop Pipes
■ Usesstandard input and output to communicate with the map
and reduce code.
■ Pipes uses sockets as the channel over which the tasktracker
communicates with the process running
54
55.
Design of HDFS
HDFSis designed for:
■ Very large Files
■ Streaming data access
■ To work with Commodity hardware
HDFS cannot be used for:
■ Low-latency data access
■ Lots of small files
■ Multiple writers, arbitrary file modifications
55
Dr. Madhuri J
56.
HDFS Concepts
-Blocks
■ Blocksize is the minimum amount of data that it can read or write.
■ HDFS block size is 128MB by default
■ If the block large enough, the time to transfer the data from the disk
can be made significantly larger than the time to seek to the start of
the block. (Minimizing the cost of seeks)
■ Replication of Blocks (3 by default)
■ Blocks are stored on different nodes and racks
56
57.
Namenode and Datanodes
Master/slavearchitecture
HDFS cluster consists of a single Namenode, a master server that manages the
file system namespace image and regulates access to files by clients (Edit Log).
Namespace image refers to the file names with their paths maintained by a
name node
Namenode maintains the filesystem tree and the metadata for all the files and
directories in the tree.
Namenode also knows the Datanode on which all the blocks for a given file
are located.
There are a number of DataNode usually one per node in a cluster.
57
The DataNodesmanage storage attached to the nodes that they run on.
A file is split into one or more blocks and set of blocks are stored in
DataNodes.
DataNodes: serves read, write requests, performs block creation, deletion, and
replication upon instruction from Namenode.
A client accesses the filesystem on behalf of the user by communicating with
the namenode and datanodes
59
Dr. Madhuri J
Secondary Namenode
■ Periodicallymerge the namespace image with the edit log to prevent the edit log
from becoming too large.
■ Runs on a separate physical machine, since it requires plenty of CPU and
memory to perform the merge.
■ It can be used at the time of primary namenode failure.
61
62.
Limitations of CurrentHDFS Architecture
■ Due to single NameNode, we can have only a limited number of DataNodes that a
single NameNode can handle.
■ The operations of the filesystem are also limited to the number of tasks that
NameNode handles at a time. Thus, the performance of the cluster depends on the
NameNode throughput.
■ Because of a single namespace, there is no isolation among the occupant
organizations which are using the cluster.
62
Dr. Madhuri J
63.
HDFS Federation
■ HDFSFederation feature introduced in Hadoop 2 enhances the existing HDFS
architecture.
■ Multiple namenodes are added which allows a cluster to scale horizontally, each of
which manages a portion of the filesystem namespace.
■ Eg: one namenode might manage all the files rooted under /user, say, and a second
namenode might handle files under /share
■ Under federation, each namenode manages a namespace volume, and a block pool.
63
64.
HDFS Federation Architecture
64
■NN1, NN2 stands for Namenode. NS1, NS2 stands for namespace.
■ Each namespace has its own block pool. (NS1 has block1)
Dr. Madhuri J
65.
HDFS Federation Architecture
■All the NameNodes uses DataNodes as the common storage.
■ Every NameNode is independent of the other and does not require any coordination
amongst themselves.
■ Each Datanode gets registered to all the NameNodes in the cluster and store blocks
for all the block pools in the cluster.
■ DataNodes periodically send heartbeats and block reports to all the NameNode in
the cluster and handles the instructions from the NameNodes.
65
Dr. Madhuri J
66.
Block pool andNamespace Volume
■ Block pool
– HDFS Federation architecture is the collection of blocks belonging to the single
namespace.
– Each block pool is managed independently from each other.
■ Namespace Volume
– Namespace with its block pool is termed as Namespace Volume.
– On deleting the NameNode or namespace, the corresponding block pool present
in the DataNodes also gets deleted.
66
Dr. Madhuri J
67.
HDFS High Availability
■High availability feature in Hadoop ensures the availability of the Hadoop cluster
without any downtime, in unfavorable conditions like NameNode failure,
DataNode failure, machine crash, etc
■ Availability if NameNode fails
– Namenode is the sole repository of the metadata and the file-to-block
mapping.
– There are a pair of namenodes in an active-standby configuration.
– In the event of the failure of the active namenode, the standby takes over its
duties to continue servicing client requests without a significant interruption
67
68.
Availability if NameNodefails
■ Architectural changes to needed to enable namespace availability.
– The namenodes must use highly available shared storage to share the edit
log.
– Datanodes must send block reports to both namenodes because the block
mappings are stored in a namenode’s memory, and not on disk.
– Clients must be configured to handle namenode failover, using a
mechanism that is transparent to users.
■ The secondary namenode’s role is subsumed by the standby.
68
Dr. Madhuri J
69.
Quorum Journal Nodes
■The active node and the passive nodes communicate with a group of separate
daemons called “Journal Nodes’
■ The active NameNode updates the edit log in the JNs.
■ The standby nodes, continuously watch the JNs for edit log change.
■ Standby nodes read the changes in edit logs and apply them to their namespace.
■ If the active NameNode fails, the standby will ensure that it has read all the edits
from Journal Nodes before promoting itself to the Active state.. This ensures
synchronization.
69
Dr. Madhuri J
70.
Failover and fencing
■The transition from the active namenode to the standby is managed by a new
entity in the system called the failover controller.
– ZooKeeper is the default implementation.
– Graceful failover and ungraceful failover.
– A network partition can trigger a failover transition, even though the
previously active namenode is still running.
■ Fencing ensures that the previously active namenode is prevented from doing
any damage and causing corruption
– STONITH or “shoot the other node in the head” is a fencing technique
which uses a specialized power distribution unit to forcibly power down the
NameNode machine.
70
Dr. Madhuri J
71.
Hadoop Filesystem
■ TheJava abstract class org.apache.hadoop.fs.FileSystem represents a filesystem
in Hadoop, and there are several concrete implementations, which are described
as follows:
71
Dr. Madhuri J
72.
Data replication
HDFSis designed to store very large files across machines in a large cluster.
Each file is a sequence of blocks.
All blocks in the file except the last are of the same size.
Blocks are replicated for fault tolerance.
Block size and replicas are configurable per file.
The Namenode receives a Heartbeat and a BlockReport from each DataNode in the cluster.
BlockReport contains all the blocks on a Datanode
The placement of the replicas is critical to HDFS reliability and performance.
Optimizing replica placement distinguishes HDFS from other distributed file systems.
72
Dr. Madhuri J
73.
Replica Placement
Rack-awarereplica placement: Many racks, communication between racks are
through switches.
Network bandwidth between machines on the same rack is greater than those in
different racks.
Namenode determines the rack id for each DataNode.
Replicas are typically placed on unique racks
Replicas are placed: one on a node in a local rack, one on a different node in the
local rack and one on a node in a different rack.
1/3 of the replica on a node, 2/3 on a rack and 1/3 distributed evenly across
remaining racks.
73
Dr. Madhuri J
74.
Replica Selection
■ Replicaselection for READ operation: HDFS tries to minimize the
bandwidth consumption and latency.
■ If there is a replica on the Reader node then that is preferred.
■ HDFS cluster may span multiple data centers: replica in the local data
center is preferred over the remote one
74
Dr. Madhuri J
Step 1: Theclient opens the file it wishes to read by calling open()
on the FileSystem object,which for HDFS is an instance of
DistributedFileSystem.
Step 2: DistributedFileSystem calls the namenode, using remote
procedure calls (RPCs), to determine the locations of the first few
blocks in the file. The namenode returns the addresses of the
datanodes that have a copy of that block.
The DistributedFileSystem returns an FSDataInputStream (an input
stream that supports file seeks) to the client for it to read data from.
FSDataInputStream in turn wraps a DFSInputStream, which
manages the datanode and namenode I/O.
77.
Step 3: Theclient then calls read() on the stream.
DFSInputStream, which has stored the datanode addresses for the
first few blocks in the file, then connects to the first (closest)
datanode for the first block in the file.
Step 4:Data is streamed from the datanode back to the client,
which calls read() repeatedly on the stream.
Step 5: When the end of the block is reached, DFSInputStream
will close the connection to the datanode, then find the best
datanode for the next block.
Step 6: Blocks are read in order, with the DFSInputStream
opening new connections to datanodes. It will also call the
namenode to retrieve the datanode locations for the next batch of
blocks as needed. When the client has finished reading, it calls
close().
78.
Network Topology andHadoop
■ The limiting factor is the rate at which we can transfer data between
nodes—bandwidth is a scarce commodity.
■ the bandwidth available for each of the following scenarios becomes
progressively less:
– Processes on the same node
– Different nodes on the same rack
– Nodes on different racks in the same data center
– Nodes in different data centers
79.
Network Topology andHadoop
■ For example, imagine a node n1 on rack r1 in data center d1. This
can be represented as /d1/r1/n1.
■ Using this notation, here are the distances for the four scenarios:
– distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same
node)
– distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the
same rack)
– distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in
the same data center)
– distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data
centers)
79
Step 1 :Theclient creates the file by calling create().
DistributedFileSystem makes an RPC call to the namenode to
create a new file in the filesystem’s namespace.
Step 2: The namenode performs various checks to record of the
new file.
Step 3: As the client writes data the DFSOutputStream splits it
into packets, which it writes to an internal queue called the data
queue. The namenode to allocate new blocks by picking a list of
suitable datanodes to store the replica.
Step 4: The DataStreamer streams the packets to the first
datanode in the pipeline,which stores each packet and forwards
it to the second datanode in the pipeline.
82
83.
Step 5: Apacket is removed from the ack queue only when it has been
acknowledged by all the datanodes in the pipeline.
Step 6: When the client has finished writing data, it calls close().
Step 7: This action flushes all the remaining packets to the datanode pipeline
and waits for acknowledgments before contacting the namenode to signal
that the file is complete.
83
84.
Replica Placement
■ Howdoes the namenode choose which datanodes to store replicas?
– placing all replicas on a single node incurs the lowest write bandwidth
penalty.
– the read bandwidth is high for off-rack reads.
– placing replicas in different data centers may maximize
– redundancy, but at the cost of bandwidth.
■ Hadoop’s default strategy
– First replica on the same node as the client
– The second replica is placed on a different rack from the first (off-rack),
chosen at random.
– The third replica is placed on the same rack as the second, but on a
different node chosen at random.
– Further replicas are placed on random nodes in the cluster, although the
system tries to avoid placing too many replicas on the same rack.
Scaling out!
■ Hadoopdivides the input to a MapReduce job into fixed-size pieces called input
splits, or just splits.
■ Splits are normally corresponds to (one or more) file blocks
■ Hadoop creates one map task for each split, which runs the user defined map
function for each record in the split.
– The processing is better load balanced when the splits are small.
– If splits are too small, the overhead of managing the splits and map task
creation begins to dominate the total job execution time.
■ A good split size tends to be the size of an HDFS block, which is 128 MB by default.
89
90.
■ Hadoop doesits best to run the map task on a node where the input data resides in
HDFS. This is called the data locality optimization.
■ If all the nodes hosting the HDFS blocks for a map task’s input split are running
other map tasks, the job scheduler will look for a free map slot on a node in the
same rack as one of the blocks.
■ If this is not possible, an off-rack node is used, which results in an inter-rack
network transfer.
■ The three possibilities of data transfer are illustrated as follows: (a), rack-local (b),
and off-rack (c) map tasks
90
91.
■ Map taskswrite their output to the local disk, not to HDFS -
Map output is intermediate output: it’s processed by
reduce tasks to produce the final output
■ Once the job is complete the map output can be thrown
away, So storing it in HDFS, with replication, would be
overkill.
91
92.
Uses of Hadoop
■Scalable: It can reliably store and process petabytes.
■ Economical: It distributes the data and processing across
clusters of commonly available computers (in thousands).
■ Efficient: By distributing the data, it can process it in
parallel on the nodes where the data is located.
■ Reliable: It automatically maintains multiple copies of data
and automatically redeploys computing tasks based on
failures.
93.
Big Data Analytics(BDA)
■Examining large amount of data
■ Appropriate information
■ Competitive advantage
■ Identification of hidden patterns, unknown
correlations
■ Better business decisions: strategic and
operational
■ Effective marketing, customer satisfaction,
increased revenue
95.
Why Big Dataand BI
Source:
Business Intelligence Strategy: A Framework for Achieving BI Excelle
nce
96.
4 types ofBig Data BI
■ Prescriptive: Analysis of actions to be taken.
■ Predictive: Analysis of scenarios that may happen.
■ Diagnostic: Look at past performance.
■ Descriptive: Real time dashboard.
97.
So, in anutshell
■ Big Data is about better analytics!
98.
Problems Associated withreading and
writing data from multiple disks
■ Hardware failure
■ Combining from different disks
Hadoop is the solution
-- reliable, scalable platform for storage and analysis
--Open sourse
100.
An OS forNetworks
■ Towards an Operating System for Networks
Global Network View
Protocols Protocols
Control via
forwarding
interface
Network Operating System
Control Programs
Software-Defined Networking (SDN)
100
Big Data Conundrum
■Problems:
– Although there is a massive spike available data, the percentage of the data
that an enterprise can understand is on the decline
– The data that the enterprise is trying to understand is saturated with both
useful signals and lots of noise
Source: IBM http://www-01.ibm.com/software/data/bigdata/
103.
The Big Dataplatform Manifesto
imperatives and underlying technologies
Hadoop
■ Hadoop isa distributed file system and data processing engine that is designed to
handle extremely high volumes of data in any structure.
■ Hadoop has two components:
– The Hadoop distributed file system (HDFS), which supports data in structured
relational form, in unstructured form, and in any form in between
– The MapReduce programing paradigm for managing applications on multiple
distributed servers
■ The focus is on supporting redundancy, distributed architectures, and parallel
processing
106.
Hadoop Related
Names toKnow
■ Apache Avro: designed for communication between Hadoop nodes through data
serialization
■ Cassandra and Hbase: a non-relational database designed for use with Hadoop
■ Hive: a query language similar to SQL (HiveQL) but compatible with Hadoop
■ Mahout: an AI tool designed for machine learning; that is, to assist with filtering data
for analysis and exploration
■ Pig Latin: A data-flow language and execution framework for parallel computation
■ ZooKeeper: Keeps all the parts coordinated and working together
107.
Some concepts
■ NoSQL(Not Only SQL): Databases that “move beyond” relational data models (i.e.,
no tables, limited or no use of SQL)
– Focus on retrieval of data and appending new data (not necessarily tables)
– Focus on key-value data stores that can be used to locate data objects
– Focus on supporting storage of large quantities of unstructured data
– SQL is not used for storage or retrieval of data
– No ACID (atomicity, consistency, isolation, durability)


















































































































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=560&fit=bounds)








































