Music Recommendations at Scale with Spark
137 likes58,806 views

Spotify uses a range of Machine Learning models to power its music recommendation features including the Discover page, Radio, and Related Artists. Due to the iterative nature of these models they are a natural fit to the Spark computation paradigm and suffer from the IO overhead incurred by Hadoop. In this talk, I review the ALS algorithm for Matrix Factorization with implicit feedback data and how we’ve scaled it up to handle 100s of Billions of data points using Scala, Breeze, and Spark.





























































































More Related Content
What's hot (20)
Similar to Music Recommendations at Scale with Spark (20)


















Recently uploaded (20)




















Music Recommendations at Scale with Spark
- 1. June 27, 2014 Music Recommendations at Scale with Spark Chris Johnson @MrChrisJohnson
- 2. Who am I?? •Chris Johnson – Machine Learning guy from NYC – Focused on music recommendations – Formerly a PhD student at UT Austin
- 3. 3 Recommendations at Spotify ! • Discover (personalized recommendations) • Radio • Related Artists • Now Playing
- 4. How can we find good recommendations? ! • Manual Curation ! ! ! • Manually Tag Attributes ! ! • Audio Content, Metadata, Text Analysis ! ! • Collaborative Filtering 4
- 5. How can we find good recommendations? ! • Manual Curation ! ! ! • Manually Tag Attributes ! ! • Audio Content, Metadata, Text Analysis ! ! • Collaborative Filtering 5
- 6. Collaborative Filtering - “The Netflix Prize” 6
- 7. Collaborative Filtering 7 Hey, I like tracks P, Q, R, S! Well, I like tracks Q, R, S, T! Then you should check out track P! Nice! Btw try track T! Image via Erik Bernhardsson
- 9. Explicit Matrix Factorization 9 Movies Users Chris Inception •Users explicitly rate a subset of the movie catalog •Goal: predict how users will rate new movies
- 10. • = bias for user • = bias for item • = regularization parameter Explicit Matrix Factorization 10 Chris Inception ? 3 5 ? 1 ? ? 1 2 ? 3 2 ? ? ? 5 5 2 ? 4 •Approximate ratings matrix by the product of low- dimensional user and movie matrices •Minimize RMSE (root mean squared error) • = user rating for movie • = user latent factor vector • = item latent factor vector X YUsers Movies
- 11. Implicit Matrix Factorization 11 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs
- 12. Alternating Least Squares (ALS) 12 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Fix songs
- 13. Alternating Least Squares (ALS) 13 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Fix songs Solve for users
- 14. Alternating Least Squares (ALS) 14 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Fix users
- 15. Alternating Least Squares (ALS) 15 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Solve for songs Fix users
- 16. Alternating Least Squares (ALS) 16 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Solve for songs Fix users Repeat until convergence…
- 17. Alternating Least Squares (ALS) 17 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Instead of explicit ratings use binary labels – 1 = streamed, 0 = never streamed •Minimize weighted RMSE (root mean squared error) using a function of total streams as weights • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • =i tem latent factor vector X YUsers Songs Solve for songs Fix users Repeat until convergence…
- 18. 18 Alternating Least Squares code: https://github.com/MrChrisJohnson/implicitMF
- 19. Section name 19
- 20. Scaling up Implicit Matrix Factorization with Hadoop 20
- 21. Hadoop at Spotify 2009 21
- 22. Hadoop at Spotify 2014 22 700 Nodes in our London data center
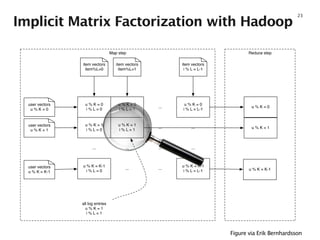
- 23. Implicit Matrix Factorization with Hadoop 23 Reduce stepMap step u % K = 0 i % L = 0 u % K = 0 i % L = 1 ... u % K = 0 i % L = L-1 u % K = 1 i % L = 0 u % K = 1 i % L = 1 ... ... ... ... ... ... u % K = K-1 i % L = 0 ... ... u % K = K-1 i % L = L-1 item vectors item%L=0 item vectors item%L=1 item vectors i % L = L-1 user vectors u % K = 0 user vectors u % K = 1 user vectors u % K = K-1 all log entries u % K = 1 i % L = 1 u % K = 0 u % K = 1 u % K = K-1 Figure via Erik Bernhardsson
- 24. Implicit Matrix Factorization with Hadoop 24 One map task Distributed cache: All user vectors where u % K = x Distributed cache: All item vectors where i % L = y Mapper Emit contributions Map input: tuples (u, i, count) where u % K = x and i % L = y Reducer New vector! Figure via Erik Bernhardsson
- 25. Hadoop suffers from I/O overhead 25 IO Bottleneck
- 26. Spark to the rescue!! 26 Vs http://www.slideshare.net/Hadoop_Summit/spark-and-shark Spark Hadoop
- 27. Section name 27
- 28. 28 ratings user vectors item vectors First Attempt (broadcast everything) worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 • For each iteration: 1. Compute YtY over item vectors and broadcast 2. Broadcast item vectors 3. Group ratings by user 4. Solve for optimal user vector
- 29. 29 ratings user vectors item vectors First Attempt (broadcast everything) worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY • For each iteration: 1. Compute YtY over item vectors and broadcast 2. Broadcast item vectors 3. Group ratings by user 4. Solve for optimal user vector
- 30. First Attempt (broadcast everything) 30 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY • For each iteration: 1. Compute YtY over item vectors and broadcast 2. Broadcast item vectors 3. Group ratings by user 4. Solve for optimal user vector
- 31. 31 ratings user vectors item vectors First Attempt (broadcast everything) worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY • For each iteration: 1. Compute YtY over item vectors and broadcast 2. Broadcast item vectors 3. Group ratings by user 4. Solve for optimal user vector
- 32. First Attempt (broadcast everything) 32 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 • For each iteration: 1. Compute YtY over item vectors and broadcast 2. Broadcast item vectors 3. Group ratings by user 4. Solve for optimal user vector
- 33. First Attempt (broadcast everything) 33
- 34. First Attempt (broadcast everything) 34 •Cons: – Unnecessarily shuffling all data across wire each iteration. – Not caching ratings data – Unnecessarily sending a full copy of user/item vectors to all workers.
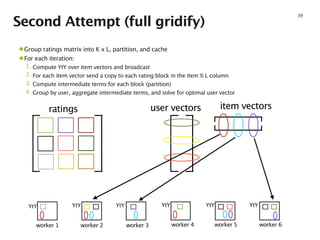
- 35. Second Attempt (full gridify) 35 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 36. Second Attempt (full gridify) 36 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 37. Second Attempt (full gridify) 37 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 38. Second Attempt (full gridify) 38 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 39. Second Attempt (full gridify) 39 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 40. Second Attempt (full gridify) 40 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 41. Second Attempt (full gridify) 41 ratings user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Group ratings matrix into K x L, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector send a copy to each rating block in the item % L column 3. Compute intermediate terms for each block (partition) 4. Group by user, aggregate intermediate terms, and solve for optimal user vector
- 43. Second Attempt 43 •Pros – Ratings get cached and never shuffled – Each partition only requires a subset of item (or user) vectors in memory each iteration – Potentially requires less local memory than a “half gridify” scheme •Cons - Sending lots of intermediate data over wire each iteration in order to aggregate and solve for optimal vectors - More IO overhead than a “half gridify” scheme
- 44. Third Attempt (half gridify) 44 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6
- 45. Third Attempt (half gridify) 45 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6
- 46. Third Attempt (half gridify) 46 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6
- 47. Third Attempt (half gridify) 47 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY
- 48. Third Attempt (half gridify) 48 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY
- 49. Third Attempt (half gridify) 49 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY
- 50. Third Attempt (half gridify) 50 ratings user vectors item vectors •Partition ratings matrix into K user (row) and item (column) blocks, partition, and cache •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY Note that we removed the extra shuffle from the full gridify approach.
- 51. 51 Third Attempt (half gridify) •Pros – Ratings get cached and never shuffled – Once item vectors are joined with ratings partitions each partition has enough information to solve optimal user vectors without any additional shuffling/aggregation (which occurs with the “full gridify” scheme) •Cons - Each partition could potentially require a copy of each item vector (which may not all fit in memory) - Potentially requires more local memory than “full gridify” scheme Actual MLlib code!
- 52. ALS Running Times 52 Hadoop Spark (full gridify) Spark (half gridify) 10 hours 3.5 hours 1.5 hours •Dataset consisting of Spotify streaming data for 4 Million users and 500k artists -Note: full dataset consists of 40M users and 20M songs but we haven’t yet successfully run with Spark •All jobs run using 40 latent factors •Spark jobs used 200 executors with 20G containers •Hadoop job used 1k mappers, 300 reducers
- 53. ALS Running Times 53 ALS runtime numbers via @evansparks using Spark version 0.8.0
- 54. Section name 54
- 55. Random Learnings 55 •PairRDDFunctions are your friend!
- 56. Random Learnings 56 •Kryo serialization faster than java serialization but may require you to write and/or register your own serializers
- 57. Random Learnings 57 •Kryo serialization faster than java serialization but may require you to write and/or register your own serializers
- 58. Random Learnings 58 •Running with larger datasets often results in failed executors and job never fully recovers
- 60. Section name 60
- 61. Section name 61
- 62. Section name 62
- 63. Section name 63
- 64. Section name 64
- 65. Section name 65