Download as PDF, PPTX





















![Snapshot Deletion ( )
● Divide deadlist into sub-lists based on birth time
● One sub-list per earlier snapshot
○ Delete snapshot: merge FS’s sublists
Snap 1 Snap 3 Snap 4 Snap 5
born < S1
born (S1, S2]
born (S3, S4]
born (S2, S3]
Deleted
snap](https://image.slidesharecdn.com/cs167zfslecture-170321194146/75/OpenZFS-novel-algorithms-snapshots-space-allocation-RAID-Z-Matt-Ahrens-23-2048.jpg)
![● Iterate over sublists
● If mintxg > prev, free all BP’s in sublist
● Merge target’s deadlist into next’s
○ Append sublist by reference -> O(1)
Snap 1 Snap 3 Snap 4 Snap 5
A: Keep
B: Keep
Free
C: Keep
Deleted
snap
Born <S1: merge to A
Born (S2, S3]: merge to C
Born (S1, S2]: merge to B
Snapshot Deletion ( )](https://image.slidesharecdn.com/cs167zfslecture-170321194146/75/OpenZFS-novel-algorithms-snapshots-space-allocation-RAID-Z-Matt-Ahrens-24-2048.jpg)


























The document details the history and architecture of the ZFS storage system, developed in 2001, highlighting its features such as snapshots, space allocation, and RAID-Z. It describes the technical workings of ZFS, including the benefits of its transactional object model and end-to-end data integrity, as well as the evolution of the filesystem over the years. Future work aims to enhance on-disk encryption, improve the performance of fragmented pools, and simplify administrative tasks.
Introduction to ZFS system by Matt Ahrens, its history from 2001, key functionality, and development milestones.
Introduction to ZFS system by Matt Ahrens, its history from 2001, key functionality, and development milestones.
Introduction to ZFS system by Matt Ahrens, its history from 2001, key functionality, and development milestones.
Introduction to ZFS system by Matt Ahrens, its history from 2001, key functionality, and development milestones.
Explains the architecture of ZFS, including its pooled storage and transaction model, and examples of commands.
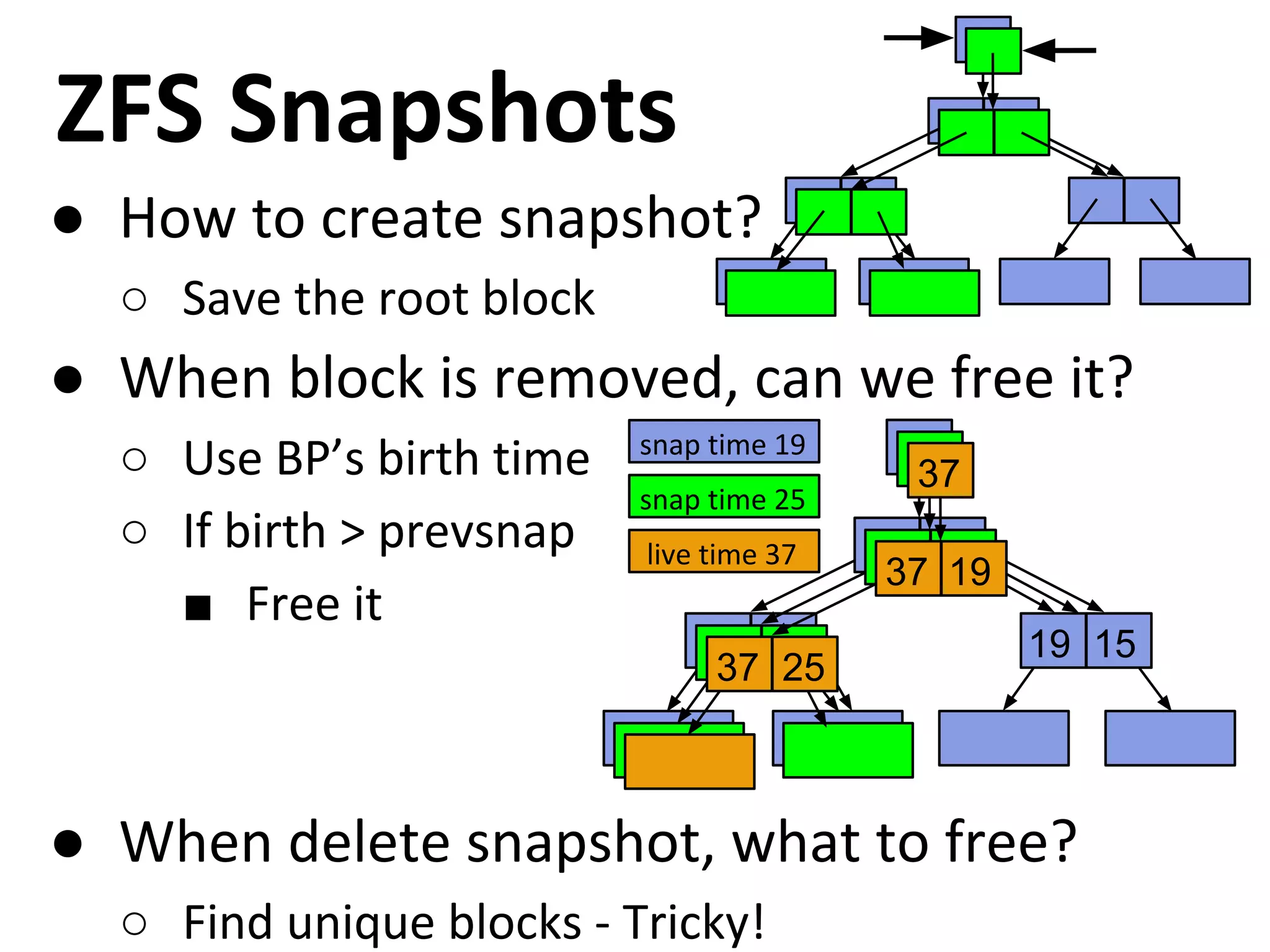
Details the snapshot mechanism of ZFS, including creation, deletion, and its efficient data handling.
Explores the strategies for efficiently deleting snapshots in ZFS and managing 'dead' block lists.
Details the snapshot mechanism of ZFS, including creation, deletion, and its efficient data handling.
Explores the strategies for efficiently deleting snapshots in ZFS and managing 'dead' block lists.
Details the snapshot mechanism of ZFS, including creation, deletion, and its efficient data handling. Explores the strategies for efficiently deleting snapshots in ZFS and managing 'dead' block lists.
Discusses ZFS's built-in compression, space allocation strategies, and the data structure's optimization.
Introduces RAID-Z, highlighting its improvements over traditional RAID and ensuring data consistency.
Proposes upcoming work including on-disk encryption, performance optimizations, and a list of resources for further reading.
Provides additional reading materials and resources about ZFS development, community contributions, and history.





















































































![[GBGCPP] MISRA C++: Safer C++17 for critical systems](https://cdn.slidesharecdn.com/ss_thumbnails/001-overview-misra-cpp17-251023093633-4690a64f-thumbnail.jpg?width=640&height=640&fit=bounds)









