Processing Large Data with Apache Spark -- HasGeek
19 likes12,743 views

Apache Spark presentation at HasGeek FifthElelephant https://fifthelephant.talkfunnel.com/2015/15-processing-large-data-with-apache-spark Covering Big Data Overview, Spark Overview, Spark Internals and its supported libraries





































































































More Related Content
What's hot (20)
Similar to Processing Large Data with Apache Spark -- HasGeek (20)


















More from Venkata Naga Ravi (11)











Recently uploaded (20)




















Processing Large Data with Apache Spark -- HasGeek
- 4. Big Data -- Digital Data growth…
- 5. V-V-V
- 6. Legacy Architecture Pain Points • Report arrival latency quite high - Hours to perform joins, aggregate data • Existing frameworks cannot do both • Either, stream processing of 100s of MB/s with low latency • Or, batch processing of TBs of data with high latency • Expressibility of business logic in Hadoop MR is challenging
- 8. Why Spark Separate, fast, Map-Reduce-like engine In-memory data storage for very fast iterative queries Better Fault Tolerance Combine SQL, Streaming and complex analytics Runs on Hadoop, Mesos, standalone, or in the cloud Data sources -> HDFS, Cassandra, HBase and S3
- 9. In Memory - Spark vs Hadoop Improve efficiency over MapReduce 100x in memory , 2-10x in disk Up to 40x faster than Hadoop
- 10. Spark In & Out RDBMS Streaming SQL GraphX BlinkDB Hadoop Input Format Apps Distributions: - CDH - HDP - MapR - DSE Tachyon MLlib Ref: http://training.databricks.com/intro.pdf
- 11. Spark Streaming + SQL Streaming SQL
- 12. Benchmarking & Best Facts
- 13. SPARK INSIDE – AROUND RDD
- 14. Resilient Distributed Data (RDD) Immutable + Distributed+ Catchable+ Lazy evaluated Distributed collections of objects Can be cached in memory across cluster nodes Manipulated through various parallel operations
- 15. RDD Types RDD
- 16. RDD Operation
- 19. Spark Cluster Overview o Application o Driver program o Cluster manage o Worker node o Job o Stage o Executor o Task
- 20. Job Flow
- 21. Task Scheduler , DAG • Pipelines functions within a stage • Cache-aware data reuse & locality • Partitioning-aware to avoid shuffles rdd1.map(splitlines).filter("ERROR") rdd2.map(splitlines).groupBy(key) rdd2.join(rdd1, key).take(10)
- 22. Fault Recovery & Checkpoints • Efficient fault recovery using Lineage • log one operation to apply to many elements (lineage) • Recomputed lost partitions on failure • Checkpoint RDDs to prevent long lineage chains during fault recovery
- 23. QUICK DEMO
- 25. Spark SQL • Seamlessly mix SQL queries with Spark programs • Load and query data from a variety of sources • Standard Connectivity through (J)ODBC • Hive Compatibility
- 26. Data Frames • A distributed collection of data organized into named columns • Like a table in a relational database Spark SQL Resilient Distributed Datasets Spark JDBC Console User Programs (Java, Scala, Python) Catalyst Optimizer DataFrame API Figur e 1: I nter faces to Spar k SQL , and inter action with Spar k. 3.1 DataFr ame API The main abstraction in Spark SQL’s API is a DataFrame, a dis- tributed collection of rows with a homogeneous schema. A DataFrame is equivalent to a table in a relational database, and can also be manipulated in similar ways to the “ native” distributed collections as well maps an to creat Spark S the quer ports us Using data fro tional d 3.3 D Users c domain Python operato aggrega jects in expressi of fema empl oy . j oi
- 27. SparkR • New R language for Spark and SparkSQL • Exposes existing Spark functionality in an R-friendly syntax view the DataFrame API
- 28. Spark Streaming File systems Databases Dashboards Flume HDFS Kinesis Kafka Twitter High-level API joins, windows, … often 5x less code Fault-tolerant Exactly-once semantics, even for stateful ops Integration Integrate with MLlib, SQL, DataFrames, GraphX Chop up the live stream into batches of X seconds. DStream is represented by a continuous series of RDDs
- 29. MLib • Scalable Machine learning library • Iterative computing -> High Quality algorithm 100x faster than hadoop
- 30. MLib Algorithms
- 31. ML Pipeline • Feature Extraction • Normalization • Dimensionality reduction • Model training
- 32. GraphX • Spark’s API For Graph and Graph-parallel computation • Graph abstraction: a directed multigraph with properties attached to each vertex and edge • Seamlessly works with both graph and collections
- 33. GraphX Framework & Algorithms Algorithms
- 34. Spark Packages
- 36. Thanks to Apache Spark by…. Started using it in our projects… Contribute to their open source community… Socialize Spark ..
- 37. Backup Slides
- 38. SPARK CLUSTER
- 39. Cluster Support • Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster • Apache Mesos – a general cluster manager that can also run Hadoop MapReduce and service applications • Hadoop YARN – the resource manager in Hadoop 2
- 40. Spark On Mesos
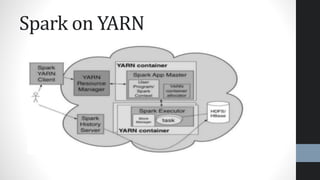
- 41. Spark on YARN
- 43. Data Science Process Data Science in Practice • Data Collection • Munging • Analysis • Visualization • Decision
- 46. Project Tungsten • Memory Management and Binary Processing: leveraging application semantics to manage memory explicitly and eliminate the overhead of JVM object model and garbage collection • Cache-aware computation: algorithms and data structures to exploit memory hierarchy • Code generation: using code generation to exploit modern compilers and CPUs
- 47. BDAS - Berkeley Data Analytics Stackhttps://amplab.cs.berkeley.edu/software/ BDAS, the Berkeley Data Analytics Stack, is an open source software stack that integrates software components being built by the AMPLab to make sense of Big Data.
- 48. Optimization • groupBy is costlier – use mapr() or reduceByKey() • RDD storage level MEMOR_ONLY is better
- 50. RDDs vs Distributed Shared Mem
- 54. PySpark
- 56. Links References • Spark • Spark Submit 2015 • Spark External Projects • Spark Central
- 58. TACHYON • Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. It achieves high performance by leveraging lineage information and using memory aggressively. Tachyon caches working set files in memory, thereby avoiding going to disk to load datasets that are frequently read. This enables different jobs/queries and frameworks to access cached files at memory speed.
- 59. Blink DB
- 61. Batches… • Chop up the live stream into batches of X seconds • Spark treats each batch of data as RDDs and processes them using RDD operations • Finally, the processed results of the RDD operations are returned in batches Micro Batch
- 62. Dstream (Discretized Streams) DStream is represented by a continuous series of RDDs
- 63. Window Operation & Checkpoint
- 64. Streaming • Scalable high-throughput streaming process of live data • Integrate with many sources • Fault-tolerant- Stateful exactly-once semantics out of box • Combine streaming with batch and interactive queries
- 65. Spark streaming data streams Receiv ers batches as RDDs results as RDDs
- 68. Micro Batch (Near Real Time) Micro Batch
- 69. Spark with Storm
Editor's Notes
- #7: https://spark-summit.org/2013/wp-content/uploads/2013/10/Tully-SparkSummit4.pdf
- #11: SparkR was introduced just a few days ago with Spark 1.4. This is Spark’s first new language API since PySpark was added in 2012. SparkR is based on Spark’s parallel DataFrame abstraction. Users can create SparkR DataFrames from “local” R data frames, or from any Spark data source such as Hive, HDFS, Parquet or JSON. SparkR DataFrames support all Spark DataFrame operations including aggregation, filtering, grouping, summary statistics, and other analytical functions. They also supports mixing-in SQL queries, and converting query results to and from DataFrames. Because SparkR uses the Spark’s parallel engine underneath, operations take advantage of multiple cores or multiple machines, and can scale to data sizes much larger than standalone R programs. The new DataFrames API was inspired by data frames in R and Pandas in Python. DataFrames integrate with Python, Java, Scala and R and give you state of the art optimization through the Spark SQL Catalyst optimizer. DataFrames are just a distributed collection of data organized into named columns and can be made from tables in Hive, external databases or existing RDDs. SQL: Spark’s module for working with structured data made of rows and columns. Spark SQL used to work against a special type of RDD called a SchemaRDD, but that is now being replaced with DataFrames. Spark SQL reuses the Hive frontend and metastore, which gives you full compatibility with existing Hive data, queries and UDFs. This allows you to run unmodified Hive queries on existing data warehouses. There is also standard connectivity through JDBC or ODBC via a Simba driver. Tableau uses this Simba driver to send queries down to Spark SQL to run at scale. Streaming: makes it easy to build scalable fault-tolerant streaming applications with stateful exactly-once symantics out of the box. Streaming allows you to reuse the same code for batch processing and stream processing. In 2012, Spark Streaming was able to process over 60 million records per second on 100 nodes at sub-second processing latency, which makes it 2 – 4x faster than comparable systems like Apache Storm on Yahoo’s S4. Netflix is one of the big users of Spark Streaming. (60 million / 100 = 600k) Spark Streaming is able to process 100,000-500,000 records/node/sec. This is much faster than Storm and comparable to other Stream processing systems. Sigmoid was able to consume 480,000 records per second per node machines using Kafka as a source. Kafka: Kafka basically acts as a buffer for incoming data. It is a high-throughput distributed messaging system. So Kafka maintains feeds of messages in categories called topics that get pushed or published into Kafka by producers. Then consumers like Spark Streaming can subscribe to topics and consume the feed of published messages. Each node in a Kafka cluster is called a broker. More than 75% of the time we see Kafka being used instead of Flume. Flume: Distributed log collection and aggregation service for moving large amounts of log data from many different sources to a centralized data store. So with Flume, data from external sources like web servers is consumed by a Flume source. When a Flume source receives an event, it stores it into one or more channels. The channels will keep the event until its consumed by a Flume sink. So, when Flume pushes the data into the sink, that’s where the data is buffered until Spark Streaming pulls the data from the sink. MLlib + GraphX: Mllib is Spark’s scalable machine learning library consisting of common algorithms and utilities including classification, regression, clustering, collaborative filtering, dimensionality reduction. MLlib’s datatypes are vectors and matrices and some of the underlying linear algebra operations on them are provided by Breeze and jblas. The major algorithmic components in Mllib are statistics (like max, min, mean, variance, # of non-zeroes, correlations (Pearson’s and Spearman’s correlations), Stratified Sampling, Hypothesis testing, Random Data Generation, Classification & Regression (like linear models, SVMs, logistic regression, linear regression, naïve Bayes, decision trees, random forests, gradient-boosted trees), Collaborative filtering (ALS), Clustering (K-means), Dimensionality reduction (Singular value decomposition/SVD and Principal Component Analysis/PCA), Feature extraction and transformation, optimization (like stochastic gradient descent and limited memory BFGS). Tachyon: memory based distributed storage system that allows data sharing across cluster frameworks like Spark or Hadoop MapReduce. Project has 60 contributors from 20 institutions. Has a Java-like API similar to that of java.io.File class providing InputStream and OutputStream interfaces. Tachyon also implements the Hadoop FileSystem interface, to allow frameworks that can read from Hadoop Input Formats like MapReduce or Spark to read the data. Tachyon has some interesting features for data in tables… like native support for multi-columned data with the option to put only hot columns in memory to save space. BlinkDB: is an approximate query engine for running interactive SQL queries on large volumes of data. It allows users to trade off query accuracy for response time by running queries on data samples and presenting results annotated with error bars. BlinkDB was demoed in 2012 on a 100 node Amazon EC2 cluster answering a range of queries on 17 TBs of data in less than 2 seconds (which is over 200x faster than Hive) with an error of 2 – 10%. To do this, BlinkDB uses an offline sampling module that creates uniform and stratified samples from underlying data. Two of the big users of BlinkDB are Conviva and Facebook. Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce
- #13: http://opensource.com/business/15/1/apache-spark-new-world-record Organizations from around the world often build dedicated sort machines (specialized software and sometimes specialized hardware) to compete in this benchmark.. Spark actually tied for 1st place with a team from University of California San Diego who have been working on creating a specialized sorting system called TritonSort. Winning this benchmark as a general, fault-tolerant system marks an important milestone for the Spark project. It demonstrates that Spark is fulfilling its promise to serve as a faster and more scalable engine for data processing of all sizes, from GBs to TBs to PBs. Named after Jim Gray, the benchmark workload is resource intensive by any measure: sorting 100 TB of data following the strict rules generates 500 TB of disk I/O and 200 TB of network I/O. Requires read and write of 500 TB of disk I/O and 200 TB of network (b/c you have to replicate the output to make it fault taulerant) First time a system based on a public cloud system has won Engineering Investment in Spark: - Sort-based shuffle (SPARK-2045) - Netty native network transport (SPARK-2468) - External shuffle service (SPARK-3796) Clever Application level Techniques: - GC and cache friendly memory layout - Pipelining More info: http://sortbenchmark.org http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html
- #15: Rresilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat. All transformations in Spark are lazy, in that they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset (e.g. a file). The transformations are only computed when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently – for example, we can realize that a dataset created through map will be used in a reduce and return only the result of the reduce to the driver, rather than the larger mapped dataset.
- #17: Transformations (eg: map, filter, group by) : Create a new dataset from an existing one Actions ( eg: count, collect, save) : Return a value to the driver program after running a computation on the dataset
- #18: Spark is persisting (or caching) a dataset in memory across operations MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. Same as the levels above, but replicate each partition on two cluster nodes. Kryo serialization: Spark can also use the Kryo library (version 2) to serialize objects more quickly. Kryo is significantly faster and more compact than Java serialization (often as much as 10x), but does not support all Serializable types and requires you to register the classes you’ll use in the program in advance for best performance. Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce
- #19: The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O. To organize data for the shuffle, Spark generates sets of tasks - map tasks to organize the data, and a set of reduce tasks to aggregate it. This nomenclature comes from MapReduce and does not directly relate to Spark’s map and reduce operations. Although the set of elements in each partition of newly shuffled data will be deterministic, and so is the ordering of partitions themselves, the ordering of these elements is not. If one desires predictably ordered data following shuffle then it’s possible to use: mapPartitions to sort each partition using, for example, .sorted repartitionAndSortWithinPartitions to efficiently sort partitions while simultaneously repartitioning sortBy to make a globally ordered RDD
- #27: The new DataFrames API was inspired by data frames in R and Pandas in Python. DataFrames integrate with Python, Java, Scala and R and give you state of the art optimization through the Spark SQL Catalyst optimizer. DataFrames are just a distributed collection of data organized into named columns and can be made from tables in Hive, external databases or existing RDDs. Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine. A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. Spark SQL supports operating on a variety of data sources through the DataFrame interface. A DataFrame can be operated on as normal RDDs and can also be registered as a temporary table
- #28: SparkR was introduced just a few days ago with Spark 1.4. This is Spark’s first new language API since PySpark was added in 2012. SparkR is based on Spark’s parallel DataFrame abstraction. Users can create SparkR DataFrames from “local” R data frames, or from any Spark data source such as Hive, HDFS, Parquet or JSON. SparkR DataFrames support all Spark DataFrame operations including aggregation, filtering, grouping, summary statistics, and other analytical functions. They also supports mixing-in SQL queries, and converting query results to and from DataFrames. Because SparkR uses the Spark’s parallel engine underneath, operations take advantage of multiple cores or multiple machines, and can scale to data sizes much larger than standalone R programs.
- #29: Chop up the live stream into batches of X seconds. Spark treats each batch of data as RDDs and processes them using RDD operations. Finally, the processed results of the RDD operations are returned in batches Streaming: makes it easy to build scalable fault-tolerant streaming applications with stateful exactly-once symantics out of the box. Streaming allows you to reuse the same code for batch processing and stream processing. In 2012, Spark Streaming was able to process over 60 million records per second on 100 nodes at sub-second processing latency, which makes it 2 – 4x faster than comparable systems like Apache Storm on Yahoo’s S4. Netflix is one of the big users of Spark Streaming. (60 million / 100 = 600k) Spark Streaming is able to process 100,000-500,000 records/node/sec. This is much faster than Storm and comparable to other Stream processing systems. Sigmoid was able to consume 480,000 records per second per node machines using Kafka as a source.
- #32: https://databricks.com/blog/2015/01/07/ml-pipelines-a-new-high-level-api-for-mllib.html A pipeline consists of a sequence of stages. There are two basic types of pipeline stages: Transformer and Estimator. A Transformer takes a dataset as input and produces an augmented dataset as output. E.g., a tokenizer is a Transformer that transforms a dataset with text into an dataset with tokenized words. An Estimator must be first fit on the input dataset to produce a model, which is a Transformer that transforms the input dataset. E.g., logistic regression is an Estimator that trains on a dataset with labels and features and produces a logistic regression model. In statistics, linear regression is an approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variable) denoted X.
- #33: GraphX is a new component in Spark for graphs and graph-parallel computation. At a high level, GraphX extends the Spark RDD by introducing a new Graph abstraction: a directed multigraph with properties attached to each vertex and edge. To support graph computation, GraphX exposes a set of fundamental operators (e.g., subgraph, joinVertices, and aggregateMessages) as well as an optimized variant of the Pregel API. In addition, GraphX includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
- #34: PageRank measures the importance of each vertex in a graph, assuming an edge from u to v represents an endorsement of v’s importance by u. For example, if a Twitter user is followed by many others, the user will be ranked highly. The connected components algorithm labels each connected component of the graph with the ID of its lowest-numbered vertex. For example, in a social network, connected components can approximate clusters. A vertex is part of a triangle when it has two adjacent vertices with an edge between them.
- #35: Spark Packages will feature integrations with various data sources, management tools, higher level domain-specific libraries, machine learning algorithms, code samples, and other Spark content.
- #36: http://www.aerospike.com/blog/what-the-spark-introduction/
- #44: https://en.wikipedia.org/wiki/Data_analysis
- #45: http://www.business-software.com/wp-content/uploads/2014/09/Spark-Storm.jpg
- #46: http://www.slideshare.net/databricks/introducing-dataframes-in-spark-for-large-scale-data-science Logical Optimization The logical optimization phase applies standard rule-based opti- mizations to the logical plan. Constant folding, Predicate pushdown Projection pruning null propagation Boolean ex- pression simplification
- #47: https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
- #53: http://apachesparkcentral.com/page/7/
- #56: GraphX adopts a vertex-cut approach to distributed graph partitioning. Rather than splitting graphs along edges, GraphX partitions the graph along vertices which can reduce both the communication and storage overhead.
- #59: http://tachyon-project.org/
- #63: https://spark.apache.org/docs/latest/streaming-programming-guide.html
- #65: Chop up the live stream into batches of X seconds. Spark treats each batch of data as RDDs and processes them using RDD operations. Finally, the processed results of the RDD operations are returned in batches Spark Streaming brings Spark's language-integrated API to stream processing, letting you write streaming applications the same way you write batch jobs. It supports both Java and Scala. Spark Streaming lets you reuse the same code for batch processing, join streams against historical data, or run ad-hoc queries on stream state Spark Streaming can read data from HDFS, Flume, Kafka, Twitter and ZeroMQ. Since Spark Streaming is built on top of Spark, users can apply Spark's in-built machine learning algorithms (MLlib), and graph processing algorithms (GraphX) on data streams
- #67: https://www.sigmoid.com/fault-tolerant-streaming-workflows/
- #73: https://www.linkedin.com/pulse/100-open-source-big-data-architecture-papers-anil-madan