


















![ast
● Python の抽象構文木を扱うためのモジュール
● compile() 関数を使って Python コードに変換できる
>>> print ast.dump(ast.parse("1 + 2 * x"))
Module(body=[
Expr(value=BinOp(op=Add(),
left=Num(n=1),
right=BinOp(op=Mult(),
left=Num(n=2),
right=Name(id='x', ctx=Load()))))
])](https://image.slidesharecdn.com/python-150327030131-conversion-gate01/85/Python-20-320.jpg)

![クエリから Python コードへの変換
#weight(3.0 #syn(カメリオ kamelio) 1.0 白ヤギ)
#weight
3.0 1.0 白ヤギ
カメリオ
def func(log_p, p):
return 0.75 * log(p("カメリオ", "kamelio")) + 0.25 * log_p["白ヤギ"]
+
* *
0.75 0.25log() []
p()
カメリ
オ
kamelio
白ヤギlog_p
クエリのパース
ast の生成
コンパイル
kamelio
#syn](https://image.slidesharecdn.com/python-150327030131-conversion-gate01/85/Python-22-320.jpg)




















More Related Content
What's hot (6)
Python を使ってカメリオを高速化した話
- 1. Python を使って カメリオを高速化 した話 白ヤギ勉強会 #13 2015.03.25 Nozomu Kaneko
- 3. カメリオ ● 気になるテーマで最新情報が追える ● 2014年 AppStore ベストアプリ ● iPhone / Android / Web
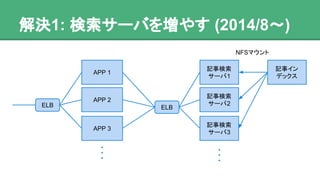
- 5. 以前の状況 (2014年後半〜) ● テーマに関連する記事の選択は、内部的に 検索で実現 o テーマ毎に異なる検索クエリが存在する ● ユーザが増えるに従い表示の遅さが目立って きた
- 6. 解決1: 検索サーバを増やす (2014/8〜) APP 1 記事イン デックス 記事検索 サーバ1 記事検索 サーバ2 記事検索 サーバ3 ELB ELB APP 2 APP 3 NFSマウント
- 7. 検索サーバを増やすようにした結果 ● ひとまずスケールするようになった o 金のチカラで解決… ● アクセスの急増に対応しきれない ● DAU と比例して徐々にサーバ台数が増加 o c3.xlarge × 6台 (MAX: 20台)
- 8. 検索の限界 ● キャッシュとの相性 o あまり長くすると新しい情報が入ってこなくなる o 1人しかフォローしていないテーマが大半 ● CPU heavy o サーバ1台で同時にさばけるリクエスト数が少ない ● 無駄が多い o 記事とテーマの関連性を毎回計算している
- 9. 解決2: 記事とテーマを事前に紐づける ● ユーザがアプリを開く前に、すべての記事に ついてすべてのテーマとの関連度を計算して おく ● 表示するときは SQL で取ってくるだけ
- 10. 目標とするパフォーマンス テーマ数: 約300万 新着記事数: 1日約2万記事 →処理速度: 1記事あたり5秒以内 最終目標: ファーストビュー1.5秒以内
- 11. 設計方針 ● 記事精度を担保するため、既存のクエリを 使って関連度スコアを計算する o 普通にやると遅すぎて話にならないので、各種の工 夫をして現実的な時間で終わるようにする ● 将来的にタグ付けのアルゴリズムを拡張可能 にする o ソースとテーマの関連付けなど
- 12. タグ付け処理の概要 ... クローラー データベース タグ付けアルゴリズム テーマ テーマ テーマ テーマ
- 13. RabbitMQ オープンソースのメッセージングミドルウェア ● 高い安定性 ● メッセージの永続化 ● 非同期タスクや PubSub など、様々な構成に対応 ● 公式のチュートリアルが 充実している
- 16. 関連度スコア計算 Q = "#weight(3.0 #syn(カメリオ kamelio) 1.0 白ヤギ)" score(Q|D) = (3.0 * log P(カメリオ or kamelio|D) + 1.0 * log P(白ヤギ|D)) / 4.0 表現rの文書D中の出現頻度 文書Dの総単語数 表現rのコーパス中の出現確率 μ=200〜2500 (スムージングパラメータ) 文書Dにおける表現 (≒単語)rの確率
- 17. スコア計算を高速化する工夫 (1) クエリの絞り込み ● クエリに含まれる単語が文書に1回も出てこなければ、 そのクエリは決してマッチしない ● 転置インデックスを使って、評価すべきクエリを絞り 込む ● フォロー中のテーマ数 約4万 → 2,000〜10,000テーマ
- 18. クエリの絞り込み カメリオは白ヤギコーポ レーションが開発した ニュースアプリです。 カメリオ カメルーン カメレオン カメラ クエリに「カメリオ」を含むテーマの リスト テーマ1 テーマ124 テーマ3357 … 転置インデックス #weight( 1.0 Python 0.5 PyPI 0.1 Guido ) 決してマッチしない
- 19. スコア計算を高速化する工夫 (2) 事前計算 ● クエリの Python コードへの変換 o それまで使っていた検索エンジンと同等の処理 (クエリのパース、スコア計算式)を Python で 再実装 ● クエリ評価に必要な統計値(各単語のコーパス中の 出現頻度)の事前取得 ● この部分の処理は全部で30分くらい。1日1回更新
- 20. ast ● Python の抽象構文木を扱うためのモジュール ● compile() 関数を使って Python コードに変換できる >>> print ast.dump(ast.parse("1 + 2 * x")) Module(body=[ Expr(value=BinOp(op=Add(), left=Num(n=1), right=BinOp(op=Mult(), left=Num(n=2), right=Name(id='x', ctx=Load())))) ])
- 21. 字句解析と構文解析 BNF の例 (数式のみ) <expression> ::= <term> ('+' <term>)* | <term> ('-' <term>)* <term> ::= <factor> ('*' <factor>)* | <factor> ('/' <factor>)* <factor> ::= '(' <expression> ')' | '+' <expression> | '-' <expression> | <number> <number> ::= <integer>('.'<digit>*)+ <integer> ::= <nonzerodigit><digit>* | '0' <nonzerodigit> ::= '1'...'9' <digit> ::= '0'...'9'
- 22. クエリから Python コードへの変換 #weight(3.0 #syn(カメリオ kamelio) 1.0 白ヤギ) #weight 3.0 1.0 白ヤギ カメリオ def func(log_p, p): return 0.75 * log(p("カメリオ", "kamelio")) + 0.25 * log_p["白ヤギ"] + * * 0.75 0.25log() [] p() カメリ オ kamelio 白ヤギlog_p クエリのパース ast の生成 コンパイル kamelio #syn
- 23. スコア計算を高速化する工夫 (3) データ構造 ● 事前計算したデータはシリアライズしてファイルに 保存する。実行時には SQL にアクセスしない。 ● 単純に pickle すると読み込みに時間がかかるので、 trie と配列を使って読み込みを高速化。 ● 300MB -> 100MB (zip 圧縮して 70MB) ここまでの工夫で、1記事あたり3〜5秒程度でタグ付けが 完了する
- 24. 結果 ● 表示速度は改善 o 最初の5テーマの表示に2秒かからない o アプリ側でも読み込みタイミングの調整を行った ● バックエンドのサーバ台数は削減 o before: c3.xlarge 7台〜 (アクセスによって変動) o after: c3.xlarge 3台 + c3.2xlarge 1台 ● 新着記事が出るまでの時間が短縮 o 以前は平均して30分程度の遅延があった
- 25. ほぼリアルタイムに記事を処理できている 通常時 tagger 10プロセス collector 2 プロセス 必要に応じてスポットインスタンスを立ち上げることでスケール可能 結果 (続き) hourly crawled contents hourly extracted contents hourly filtered contents hourly queued contents hourly tagged contents
- 26. 苦労したところ ● 精度の評価 o スコア計算のバグやパイプライン処理中の欠落など 様々な原因で、表示される記事が一致しない ランダムに選んだテーマで結果を比較 アクセスの多いテーマで誤差の原因を解析
- 27. 苦労したところ ● RabbitMQ ワーカーが安定しない o ライブラリ (pika) とマルチスレッドの相性が悪い o heartbeat が途切れるとサーバが勝手に接続を切る o 最終的には詰まっていることを検知して自動再起動 するようにした(運用でカバー)
- 28. なぜ Python か ● 高速化したいなら C++ や Go の方が Python より 100 倍高速では? ● Python を使った理由 o 構文解析のような複雑な処理を、なるべくバグを出 さずにかつ素早く書けること o コードオブジェクトのシリアライズができること o pypy は使っているライブラリが対応していなかった
- 29. おまけ