R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜
73 likes21,140 views

2013年11月期 AITCオープンラボ R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜










![R言語とは・・・?
• R言語(あーるげんご)はオープンソース・フリーソフトウェアの統計
解析向けのプログラミング言語及びその開発実行環境である。
• R言語はニュージーランドのオークランド大学のRoss Ihakaと
Robert Gentlemanにより作られた。現在ではR Development
Core Team(S言語開発者であるJohn M. Chambersも参画して
いる[1]。)によりメンテナンスと拡張がなされている。
• なお、R言語の仕様を実装した処理系の呼称名はプロジェクト
を支援するフリーソフトウェア財団によれば『GNU R』である[2]が、
他の実装形態が存在しないために日本語での慣用的呼称に
倣って、当記事では、仕様・実装を纏めて適宜にR言語や単にR
等と呼ぶ。
Wikipedia(R言語)より
「R」は開発者2人の名前から取ったという説と、基に
したS言語には一歩及ばないという説があるの
一文字の言語って検索しにくい・・・
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-11-320.jpg)









![データフレームの参照
• データフレームは名前付きの行列のデータ
• データフレームは行、または列を指定してアクセスする
ことが基本
– 列のインデックスを指定(何列目か)
> iris[,2]
– 行のインデックスを指定(何行目か)
> iris[3,]
– 列名を指定
> iris$Sepal.Width
– 左に表示される[ ]は何個目の要素か
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-21-320.jpg)
























![まずはデータを準備
• ぱっと見た感じ、こう分類されそう
– [1] setosa, setosa, versicolor, versicolor
– [5] versicolor?, virginica 5個目がどちらに分類され
るかな?
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-47-320.jpg)

![教師あり分類器(SVM)
• SVMはksvmという関数を使用する
– デフォルトでは使えないので、libraryを読み込む
> library( kernlab )
– libraryが存在しない場合は、インストールする
> install. packages( "kernlab" )
• データを学習させる
– 列はPetal.Length, Petal.Width, Speciesを使用(3~5列
)、Speciesを求めるSVM学習
> svm<-ksvm(Species ~., data=iris[,3:5])
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-49-320.jpg)
![教師あり分類器(SVM)
• 学習結果の評価
– 元データを使って、SVMにかけてみる
> predict(svm, iris)
– 元データと一致しているか?
> pre<-predict(svm, iris)
> table(pre, iris[,5])
– 用意したデータを分類しよう
> predict(svm, target)
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-50-320.jpg)
![教師あり分類器(SVM)
• versicolorとvarsinicaはやはり上手く判定されて
いない
• どんな感じでマージンが引かれているか見てみよう
– 二種だけ抽出 (51行目~150行目)
> iris2<-iris[51:150, 3:5]
> svm<-ksvm(Species ~., data=iris2)
– 分類器を使用してplotします
> plot(svm, data=iris2[,1:2])
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-51-320.jpg)


![教師なし分類器(K-means)
• K-meansを使ってみよう
– Petal.Length, Petal.Widthを3つのクラスタに分類す
る
> km<-kmeans(iris[,3:4], 3)
– どう分類されたか評価
> km$cluster
> cluster<-sapply(km$cluster, function(x)switch(
x, "1"="setosa","2"="versicolor","3"="virginica"))
> table(cluster, iris)
※Cluster IDは毎回同じ値とは限らないので、
結果が異なっている可能性もあります
km$clusterだけでもどう分類されたかは分かります
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-54-320.jpg)
![教師なし分類器(K-means)
山のあやめも合わせて分類しよう
> km_target<-rbind(iris[,3:4], target)
> km<-kmeans(km_target, 3)
– どう分類されたか評価
> km$cluster
> cluster<-sapply(km$cluster, function(x)switch(x,
"1"="setosa","2"="versicolor","3"="virginica"))
> cluster
※Cluster IDは毎回同じ値とは限らないので、
結果が異なっている可能性もあります
km$clusterだけでもどう分類されたかは分かります
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-55-320.jpg)













![台風の軌道を描いてみよう
Header部を抜き出します
> header <- read.table(textConnection(bst[grep("^66666", bst)]))
> View(header)
HeaderとRecordとで列が違うので、個別に
処理する
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-69-320.jpg)
![台風の軌道を描いてみよう
次にRecord部を処理します
> record<-read.table(textConnection(bst[-grep("^66666",
bst)]),fill=TRUE)
> record<-record[!is.na(record[,7]),]
> View(record)
レコードによって列の数が違うので、ゴミレコー
ドが発生します。ゴミの除去も行います。
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-70-320.jpg)
![台風の軌道を描いてみよう
必要な列のみ抽出し、列名を付ける
> header<-header[ , c(3,4,8)]
> names(header) <- c("NROW", "TC_NO", "NAME")
> View(header)
> record<-record[ , c(1,3:7)]
> names(record) <- c("DATE_TIME", "GRADE", "LAT", "LON",
"HPA", "KT")
> View(record)
Header: データ数(NROW)、TropicalCyclone番号(TC_NO)、
台風の国際名(NAME)
Record:観測時刻(DATE_TIME)、階級(GRADE)、緯度
(LAT)、経度(LON)、中心気圧(HPA)、最大風速(KT)
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-71-320.jpg)




![台風の軌道を描いてみよう
該当範囲の地図の座標パスを生成します
> map<-data.frame(map(plot=FALSE,
xlim=c(range_lon[1]-10, range_lon[2]+10),
ylim=c(range_lat[1]-5, range_lat[2]+5))[c("x","y")])
地図の描画ではなく、座標パスであるところが注
意。描画はggplotを使用します
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-76-320.jpg)



![台風の軌道を描いてみよう
日本付近のデータで絞り込んでみます
> target_tcno<-unique(data[(121<=data$LON&data$LON<=155)&
(20<=data$LAT&data$LAT<=50), 1])
> data2<-data[data$TC_NO%in%target_tcno,]
日本の付近の以下の範囲を通過している
台風
緯度:121~155
経度:20~50
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-80-320.jpg)









![Rで形態素解析(RMeCab) でも
• 20件以上の単語のみにフィルタリングしてゴミデー
タも除去
> part_rm<-rm[rm$Freq > 20,]
> part_rm<-part_rm[!part_rm$Info1=="記号",]
> part_rm<-part_rm[!part_rm$Info2=="数",]
> part_rm<-part_rm[!part_rm$Info1=="接続詞",]
> part_rm<-part_rm[!part_rm$Info1=="接頭詞",]
> part_rm<-part_rm[!part_rm$Info1=="連体詞",]
> part_rm<-part_rm[!part_rm$Info1=="助詞",]
> part_rm<-part_rm[!part_rm$Info1=="助動詞",]
> part_rm<-part_rm[!part_rm$Info1=="副詞",]
> part_rm<-part_rm[!part_rm$Info1=="感動詞",]
> part_rm<-part_rm[!part_rm$Info2=="接尾",]
> part_rm<-part_rm[!part_rm$Info2=="非自立",]
> part_rm<-part_rm[!part_rm$Info2=="代名詞",]
> part_rm<-part_rm[!part_rm$Info2=="サ変接続",]
予想外のデータもいっぱいできるから
こまめに削除ルールを作るの
ガツッと削除した後は個別のデータから削除対象を判断
Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.](https://image.slidesharecdn.com/20131123r-131122214447-phpapp01/85/R-90-320.jpg)





































More Related Content
What's hot (20)
Viewers also liked (14)
![[データマイニング+WEB勉強会][R勉強会] R言語によるクラスター分析 - 活用編](https://cdn.slidesharecdn.com/ss_thumbnails/cluster-100416230155-phpapp02-thumbnail.jpg?width=560&fit=bounds)

![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる R言語によるクラスター分析 - 似ているものをグループ化する-](https://cdn.slidesharecdn.com/ss_thumbnails/webmining2cluster-100319212743-phpapp01-thumbnail.jpg?width=560&fit=bounds)









Similar to R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜 (20)




















More from Yasuyuki Sugai (18)


















Recently uploaded (6)






R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜
- 1. R言語で始めよう、データサイエンス! (ハンズオン勉強会) ~機械学習・データビジュアライゼーション事始め~ 2013年11月期 AITCオープンラボ 2013/11/23 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 2. 自己紹介 •菅井 康之 • https://www.facebook.com/yasuyuki.sugai 株式会社イーグル所属 •AITC 運営委員※ •AITCクラウド・テクノロジー活用部会 サブリーダー よろしくおねがいしまーす ※先端IT活用推進コンソーシアム(AITC)は XMLコンソーシアムの後継団体です http://aitc.jp/ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. AITC非公式キャラクター ハルミン 2
- 3. 先端IT活用推進コンソーシアム Advanced IT Consortium to Evaluate, Apply and Drive Java コンソーシアム XML部会 Windows コンソーシアム 日本経営協会 XMLフェスタ 2000/07 設立宣言 2001/06~2010/03実活動 2010/03~2010/09 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 2010/09/08設立
- 4. AITCとは: 企業における先端ITの活用および 先端ITエキスパート技術者の育成を目的とし、 もって、社会に貢献することを目指す非営利団体 設 立: 2010年9月8日(会期: ~2016年8月31日) 会 長 : 鶴保 征城 (IPA顧問、HAL校長) 会 員 : 法人会員&個人事業主、個人会員、学術会員 特別会員 (産業技術総合研究所、気象庁、 消防研究センター、防災科学技術研究所) 顧 問 : 稲見 昌彦 (慶応義塾大学大学院 教授) 和泉 憲明 (産業技術総合研究所 上級主任研究員) 萩野 達也 (慶応義塾大学 教授) 橋田 浩一 (東京大学大学院 情報理工学系研究科 教授) 丸山 不二夫(早稲田大学大学院 客員教授) 山本 修一郎(名古屋大学大学院 教授) BizAR顧問:三淵 啓自 (デジタルハリウッド大学大学院 教授) 川田 十夢 (AR三兄弟 長男) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 5. 第4期活動対象分野 モノ ナチュラルユーザー インターフェース コト real ユーザーエクスペリエンス 人 ソーシャル AR コンテキスト virtual コンテキスト コンピューティング クラウド コンピューティング メタ データ 今日はクラウドなの Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 6. クラウド・テクノロジー活用部会をちょこっと紹介 •データの収集から蓄積、結合、分析、見える化までの 一連のプロセスを対象として活動 •今まで色々やってきました •クラウド基盤技術、分散技術 •気象庁防災情報XMLの利活用 •認証・認可、セキュリティ •オープンデータ、 RDF/SPARQL •統計解析・機械学習 ←今日はこれ etc.. Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 6
- 7. 本日のハンズオンの流れ •16:00~16:20 •16:20~17:00 •17:15~18:00 •18:15~19:00 •19:00~19:20 •19:20~19:30 •19:30~20:00 •懇親会 環境の確認 R基礎&グラフ描画編 Rによる機械学習編 Rによるデータビジュアライゼーション編 R+JavaScriptビジュアライゼーションご紹介 まとめ。その他お知らせなど。 撤収(ちょっとお手伝い頂ければと・・・) 長丁場なので、頑張りましょう (自分に向けて・・・) AITC非公式キャラクター ハルミン Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 7
- 8. 環境の確認 •RとR Studioをインストールして頂け てますか?? •Rはこちらから •http://www.r-project.org/ •R Studioはこちらから •http://www.rstudio.com/ide/download/desktop Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 8
- 9. 環境の確認 •コマンド全部打つのは大変、コピペ したいという方はこちらに一時的に PDFで置いておきました • https://dl.dropboxusercontent.com/u/8148946 /AITC/R/20131123_R%E8%A8%80%E8%AA %9E%E3%83%8F%E3%83%B3%E3%82%B A%E3%82%AA%E3%83%B3%E5%8B%89 %E5%BC%B7%E4%BC%9A.pdf •たぶんハンズオン終わったら見えなくなります。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 9
- 10. •R基礎&グラフ描画編 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 10
- 11. R言語とは・・・? • R言語(あーるげんご)はオープンソース・フリーソフトウェアの統計 解析向けのプログラミング言語及びその開発実行環境である。 • R言語はニュージーランドのオークランド大学のRoss Ihakaと Robert Gentlemanにより作られた。現在ではR Development Core Team(S言語開発者であるJohn M. Chambersも参画して いる[1]。)によりメンテナンスと拡張がなされている。 • なお、R言語の仕様を実装した処理系の呼称名はプロジェクト を支援するフリーソフトウェア財団によれば『GNU R』である[2]が、 他の実装形態が存在しないために日本語での慣用的呼称に 倣って、当記事では、仕様・実装を纏めて適宜にR言語や単にR 等と呼ぶ。 Wikipedia(R言語)より 「R」は開発者2人の名前から取ったという説と、基に したS言語には一歩及ばないという説があるの 一文字の言語って検索しにくい・・・ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 12. R言語の特徴 • 統計解析のためのプログラム言語 – 統計解析に関するライブラリーが豊富 – 少ないコード量で統計処理が行える • データ・ビジュアライゼーションも得意 – データを取り扱うこと全般に向いている • (最近では何でも出来るようになってきた) – 日々現れるライブラリー でもRって何だか難しそうで取っ付きにくい。。。 もっと手軽に使えるものって無いの? もちろん、他にも色々あるよ! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 13. その他の統計解析ツール • メジャーな2トップ – SPSS • http://www-01.ibm.com/software/jp/analytics/spss/products/statistics/ – SAS • http://www.sas.com/offices/asiapacific/japan/ 大学や研究ではよく使われているけど、どれも 有料のソフトウェアなの。 Rはフリーでここまで実現出来てるのが凄いの。 研究開発や個人でやる時には予算が確保し辛いから、 フリーというのは魅力的だな~。 そういやExcelでも統計解析が出来るって聞いたよ? そう、Excelも機能が豊富で、統計解析の 関数があったりするの Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 14. Excel での統計解析 • Excelのアドインである「分析ツール」を入れることで、 統計解析が可能になる – Excel上のデータに対して 関数を使用することが可能 – グラフ描画等のビジュアル面も 元々Excelでは実現していた – 使い慣れたI/F、GUI上での 操作が可能 もうExcelで良くない? そうかもね・・・ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 15. いやいや、やっぱりRでしょ・・・ • Excelに比べて・・・ – プログラムとして組んでいるので、再現性が高い • マウス操作や人の手が入らない • VBAを組むことでExcelでも同様の事が出来るが、それならExcelであるメリッ トは少ない – 幅広いOSに対応 • Windows, Mac, Linuxで動作する – オープンソース • 動作の透明性が高い – 統計処理の信頼度が高い • 世界中の人が使いながら、チェックしている – 高度なテキスト処理、高機能なライブラリが日々現れる やっぱりRが良い気がしてきた そうね・・・ 危うくExcel勉強会になるところだった・・・ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 16. 何はともあれ・・・ Rを触ってみよう! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 17. R Studioの見方 • R の IDE環境 データView ソースEdit コマンドライン コード・アシスト付き Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. コマンドの実行履歴 アクティブなデータ セット グラフのプロット パッケージ管理
- 18. Rの基礎 • 変数は自由に宣言可能 • 代入は<-で行う > var<-12+22 • データの基本はベクトル。データフレームが扱えるよう になると色々出来る > var<-c(1,2,3,4,5,6,7,8,9) > var<-data.frame("aa"=c(1,2)) • 関数は必要になった時に調べる ・・・ と、とにかく触ってみよう! 何事もやってみないと! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 19. Dataに触れてみよう • Rはサンプルデータが豊富に用意されている – 以下の関数を実行することで、どんなサンプルデータがあるか 参照可能 > data() – 気になるデータがあれば、?を付けて実行 > ?iris – 以下のコマンドで、どんな列や型を持つか確認可能 > str(iris) – データの中身を見たい場合は、そのまま実行 > iris – そのままだと見づらいので、Viewを付けて実行してみよう > View(iris) – Workspaceの左上に表示されるので見てみよう Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 20. 補足:irisの説明 • 今回頻繁に登場する予定のirisの概要 – Iris = 「あやめ」に関するデータ – あやめは、大きな花びら「Sepal:がく片」と小さな花び ら「Petal:花びら」を持つ – 以下を表現するデータである • Sepalの「Length:長さ」と「Width:幅」 • Petalの「Length:長さ」と「Width:幅」 • Speciesはあやめの三品種 今日はirisをメインに使います 終わる頃にはirisが好きになってるはず! 画像:Wikipedia(あやめ) より引用 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 21. データフレームの参照 • データフレームは名前付きの行列のデータ • データフレームは行、または列を指定してアクセスする ことが基本 – 列のインデックスを指定(何列目か) > iris[,2] – 行のインデックスを指定(何行目か) > iris[3,] – 列名を指定 > iris$Sepal.Width – 左に表示される[ ]は何個目の要素か Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 22. データフレームの参照 • 試しに関数を色々実行 • 平均 > mean(iris$Sepal.Width) • 最大 > max(iris$Sepal.Width) • 最小 > mix(iris$Sepal.Width) ちょっとずつ行きましょう • サマリー (上記がほとんど参照可能) > summary(iris$Sepal.Width) • 標準偏差(これは後で・・・) > sd(iris$Sepal.Width) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 23. まずはプロットしてみよう • 散布図にプロットしてみる – まずは何も考えずにplot関数の実施 > plot(iris) • Irisの5つの変数それぞれの組み合わせでplotされる 何事もデータをプロットするところから スタートね。図から何が見えるかな? Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 24. 2つの列で相関を見てみよう • Petal.LengthとPetal.Widthをプロットしてみる > plot(x=iris$Petal.Length, y=iris$Petal.Width) 何か相関がありそうね。でもこれだけじゃまだよくわ からないの。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 25. 色を付けてみよう • Speciesの値毎に色を分けてみる > plot(x=iris$Petal.Length, y=iris$Petal.Width, col=iris$Species) きれいに3つのクラスタにわかれてる! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 26. もう一つのがく片は? • もう一つのセットである、Sepalをプロットしてみよう > plot(x=iris$Sepal.Length, y=iris$Sepal.Width, col=iris$Species) こっちはversicolorとvirginicaの境界が あいまいね Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 27. 他のグラフも描画してみよう • ヒストグラムでPetal.Lengthの分布を見てみよう > hist(x=iris$Petal.Length) ・・・・・ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 28. まだまだ行きますよー • 疲れましたか? • 何となくR言語に慣れてきましたか? • 何をしているかイメージがわきづらいですか? 次からはちょっと流れを 変えまーす Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 29. パンに異常に固執するポアンカレさん ポアンカレはあるとき、地元のパン屋で売られ ているパンが謳い文句の1kgよりも軽いのでは ないかという疑いを抱いたのだそうです。 そこで彼は1年間毎日パンを買って帰っては、 重さを量ったそうです。1年後、彼は計測結果 をプロットして、それが平均950g、標準偏差 50gの正規分布に一致することを示しました。 彼はこの証拠をパン屋の監督機関に提出し、 件のパン屋は警告を受けたとのことです。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 30. パンに異常に固執するポアンカレさん ポアンカレさん恐ろしい!! 画像:Wikipedia(アンリ・ポアンカレ) より引用 ポアンカレさんは有名な数学者です。 またこの逸話も有名ですが、本当に本人がやったのかは確証が もてません Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 31. ポアンカレさんに近づこう! 平均950g、標準偏差50gの計測結果を作っ てみよう。 > rnorm(365, mean=950, sd=50) #1年間(365日), 平均950, 標準偏差50 ヒストグラムに表示してみよう。 > rn<-rnorm(365, mean=950, sd=50) > hist(rn) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 32. ポアンカレさんに近づこう! 平均950g、標準偏差50gの正規分布とヒス トグラムを重ねてみよう。 > rn<-rnorm(365, mean=950, sd=50) > hist(rn, freq=FALSE) #freq=TRUE(頻度), freq=FALSE(確立密度) > curve(dnorm(x, mean=950, sd=50), add=TRUE) グラフを重ね合わせる場合、範囲指定してあ げないと、2つのグラフでずれてしまう。 > rn<-rnorm(365, mean=950, sd=50) > hist(rn, breaks=seq(700, 1200, 10), freq=FALSE) #freq=TRUE(頻度), freq=FALSE(確立密度) > curve(dnorm(x, mean=950, sd=50), 700, 1200,add=TRUE) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
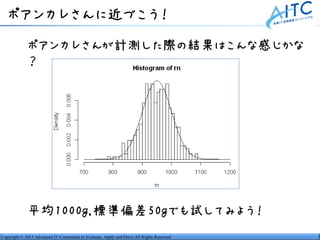
- 33. ポアンカレさんに近づこう! ポアンカレさんが計測した際の結果はこんな感じかな ? 平均1000g,標準偏差50gでも試してみよう! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 34. ちなみに、標準偏差とは・・・ 平均からどれくらいの範囲にデータが密集しているか をあらわします。σ=シグマ 画像:Wikipedia(Standard deviation) より引用 つまり、平均950g、標準偏差50gの正規分布という ことは、900g~1000gに68.2%のデータが集まっている。 850g~1050gも含めると、95%となり、800g~1100g までになると、99.7%です。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 35. まだまだパンに固執するポアンカレさん 翌年も、ポアンカレは毎日パンの重さを量る実験 を続けました。 その年の終わりには、パンの重さの平均が期待通 り1,000gであることを確かめました。 しかし、彼は再び監督機関に通告し、それによって パン屋は罰金を受けたというのです。 なぜでしょうか? なぜなら、分布の形状が非対称 だったのです。正規分布と異なり、その分布は右に 歪んでいました。 これは、パン屋が依然として950gのパンを作り続 けていたものの、ポアンカレだけには重いパンを渡し ていた、という仮説を裏付けるものだったのです。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 36. まだまだパンに固執するポアンカレさん 進撃のポアンカレさん!! vsパン屋さん 画像:Wikipedia(アンリ・ポアンカレ) より引用 ポアンカレさんは有名な数学者です。 またこの逸話も有名ですが、本当に本人がやったのかは確証が もてません Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 37. ところで何でポアンカレさんの話? クラウド部会の勉強会の題材としてThinkStatsプロ グラマのための統計入門を使用 そのなかでポアンカ レさんの逸話を基にした課題があり、部会でその場で コーディングを行いました 興味のある方はこちらの本をご覧ください Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 38. ポアンカレさんの課題 平均950g、標準偏差50gの正規分布からn 個のパンを選び、一番重いパンをポアンカレに 渡すパン屋をシミュレートしたプログラムを書い てください。nをいくらにすれば、平均が1,000g の分布を作れるでしょうか? その標準偏差は いくらになりますか? この分布を同じ平均、 標準偏差の正規分布と比較してください。 分布形状の違いは 監督機関を納得させられ るほど顕著なものですか? Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 39. 関数にしてみました poincare_bread.Rという名前で保存します poincare_bread <- function(n) { s<-c() for(i in 1:365) { rn<-rnorm(n,mean=950,sd=50) poincare<-max(rn) s=append(s, poincare) } hist(s, breaks=seq(700,1200,10), freq=FALSE) curve(dnorm(x, mean=mean(s), sd=sd(s)), 700, 1200, add=TRUE) return(data.frame(mean=mean(s), sd=sd(s))) } 以下のリンクからダウンロードできます(今日のハンズオ ンが終わったら見えなくなってるかもしれません) https://dl.dropboxusercontent.com/u/8148946/AITC/R/poincare_bread.R Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 40. 関数を読み込んで実行 作業ディレクトリを確認してみましょう > getwd() 作業ディレクトリを設定するには? > setwd("/xxxx/xxxx/xxx") 関数を読み込んで実行しよう > source("poincare_bread.R") > poincare_bread(1) > poincare_bread(2) データに人為的な操作が加わると・・・ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 41. 2013年12月号のニュートンにもポア ンカレさんの話が載っています。その他 にも広く統計を紹介していますので、 興味のある方は読んでみてください。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 42. •機械学習編 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 42
- 43. irisについて私たちが知っていること irisの三つの品種は花びら(Petal)の大 きさによって分類することができる このデータを使って機械学習をしてみよう 機械学習のなかで分類を行う分類器を 使っていきます Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 44. 分類器について 分類器では、大きく分けると「教師あり」と「教 師なし」があります 「教師あり」は正解となるデータから傾向を学習 し、新しく入力されるデータがどこに分類される かを判定します。 「教師なし」は何が正解かという情報を与えませ んが、今あるデータから推測し、どのように分類さ れるかを判定します。 今日は、「教師あり」としてサポートベクトルマシー ン(SVM)、「教師なし」としてK平均法(K-means) を使用します Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 45. まずはデータを準備 分類したいデータを準備します。 山に遊びに行くと、あやめの花を見つけ ました。このあやめの品種はなんだろう? Petal.Length, Petal.Widthを持つデータ フレームを作成 > target<-data.frame("Petal.Length"=c(1,1.5,3,4,5,6), "Petal.Width"=c(0.2,0.4,1.2,1.4, 1.6, 1.8)) > View(target) #データ確認 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 46. まずはデータを準備 irisデータと重ね合わせてみよう 2つのデータをプロットしてみる > plot(x=iris$Petal.Length, y=iris$Petal.Width, col=sapply(iris$Species, function(x) switch(x, "setosa"="red", "versicolor"="blue", "virginica"="green")), xlim=c(0,7), ylim=c(0,3)) > par(new=T) #追加書き込み > plot(x=target$Petal.Length, y=target$Petal.Width, xlim=c(0,7), ylim=c(0,3)) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 47. まずはデータを準備 • ぱっと見た感じ、こう分類されそう – [1] setosa, setosa, versicolor, versicolor – [5] versicolor?, virginica 5個目がどちらに分類され るかな? Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 48. 教師あり分類器(SVM) 分類されているデータから、クラス間の距 離がなるべく遠くなる位置で線形に分類 します 基本は線形分類ですが、カーネルトリック を使うことにより非線形データも分類す ることができます こちらのサイトをお借りして説明します http://mjin.doshisha.ac.jp/R/31/31.html Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 49. 教師あり分類器(SVM) • SVMはksvmという関数を使用する – デフォルトでは使えないので、libraryを読み込む > library( kernlab ) – libraryが存在しない場合は、インストールする > install. packages( "kernlab" ) • データを学習させる – 列はPetal.Length, Petal.Width, Speciesを使用(3~5列 )、Speciesを求めるSVM学習 > svm<-ksvm(Species ~., data=iris[,3:5]) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 50. 教師あり分類器(SVM) • 学習結果の評価 – 元データを使って、SVMにかけてみる > predict(svm, iris) – 元データと一致しているか? > pre<-predict(svm, iris) > table(pre, iris[,5]) – 用意したデータを分類しよう > predict(svm, target) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 51. 教師あり分類器(SVM) • versicolorとvarsinicaはやはり上手く判定されて いない • どんな感じでマージンが引かれているか見てみよう – 二種だけ抽出 (51行目~150行目) > iris2<-iris[51:150, 3:5] > svm<-ksvm(Species ~., data=iris2) – 分類器を使用してplotします > plot(svm, data=iris2[,1:2]) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 52. 教師あり分類器(SVM) なんとなくイメージに近いかな やっぱり判定が難しそうなところがあるね Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 53. 教師なし分類器(K-means) データの散らばり具合を計測し、散らば りが最も少なくなるよう分類します。 こちらのサイトをお借りして説明します http://tech.nitoyon.com/ja/blog/2013/11/07/k-means/ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 54. 教師なし分類器(K-means) • K-meansを使ってみよう – Petal.Length, Petal.Widthを3つのクラスタに分類す る > km<-kmeans(iris[,3:4], 3) – どう分類されたか評価 > km$cluster > cluster<-sapply(km$cluster, function(x)switch( x, "1"="setosa","2"="versicolor","3"="virginica")) > table(cluster, iris) ※Cluster IDは毎回同じ値とは限らないので、 結果が異なっている可能性もあります km$clusterだけでもどう分類されたかは分かります Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 55. 教師なし分類器(K-means) 山のあやめも合わせて分類しよう > km_target<-rbind(iris[,3:4], target) > km<-kmeans(km_target, 3) – どう分類されたか評価 > km$cluster > cluster<-sapply(km$cluster, function(x)switch(x, "1"="setosa","2"="versicolor","3"="virginica")) > cluster ※Cluster IDは毎回同じ値とは限らないので、 結果が異なっている可能性もあります km$clusterだけでもどう分類されたかは分かります Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 56. 演習問題? 今までやってきた機械学習のちょうど 良さそうな課題がありました http://next.rikunabi.com/tech/docs/ct_s03600.jsp?p=002315 まだまだやりたいけど、一旦ここまでにして次に進んでいきます! 時間があったら、、、 SVMのマッチング率確認、交差検定、SVMチューニング Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 57. •データ・ •ビジュアライゼーション編 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 57
- 58. ggplot2 • デフォルトの作図よりも効率的、かつ美しい図を描 くことが出来る – 層を重ねることで図を作成する • ビジュアライズの基本だよね • とっても流行ってる – 標準plotよりも使われてるぐらい、みんな使ってる こんな図が簡単(?)に作れちゃう! 頑張ればもっと美しい図も Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 59. ggplot2を触ってみよう • まずはlibraryのインストールから > install.packages("ggplot2") – 関数にした場合に毎回インストールを叩くのは無駄なの で、必要な場合のみインストールする場合は、こんな感 じ > if(!("ggplot2" %in% installed.packages())){ + install.packages("ggplot2") + } ちなみにqplotはquick plot • libraryの読み込み の略よ > library(ggplot2) • irisをプロットしてみよう > qplot(data=iris, x=Petal.Length, y=Petal.Width) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 60. ggplot2を触ってみよう • 色々試してみよう! – Species毎に色を変えてみる > qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species) – Species毎に色ではなく、形を変えてみる(色との組み合わせも可 能) > qplot(data=iris, x=Petal.Length, y=Petal.Width, shape=Species) ※数値で形を変えたい場合は、factor( ) 関数をかまして変換する必要あり – Sepal.Length毎に大きさを変えてみる > qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species, size=Sepal.Length) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 61. ggplot2を触ってみよう • 層を重ねるイメージを体感 – 回帰直線を描いてみる > qplot(data=iris, x=Petal.Length, y=Petal.Width)+stat_smooth() – 品種毎に回帰直線を描いてみる > qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species)+ stat_smooth() Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 62. ggplot2を触ってみよう • 散布図以外の図も描画してみよう • ヒストグラム – ヒストグラムでPetal.Lengthの分布を見てみよう > qplot(data=iris, x=Petal.Length, geom="histogram") – Species毎に塗りつぶしてみよう > qplot(data=iris, x=Petal.Length, geom="histogram", fill=Species) • 密度グラフ – 密度グラフでPetal.Lengthを積み重ねてみよう > qplot(data=iris, x=Petal.Length, geom="density") – 品種毎に描いてみよう > qplot(data=iris, x=Petal.Length, geom="density", fill=Species) – 半透明にすると、良い感じ! > qplot(data=iris, x=Petal.Length, geom="density", fill=Species, alpha=0.3) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 63. ggplot2を触ってみよう • こんな感じの図が描けました 見た目がきれいだと、楽しくな るね! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 64. ビジュアライゼーション? • 今やったのってグラフ描画であって、 ビジュアライゼーションとは違うんじ ゃない? Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 65. 台風の軌道を描いてみよう • 気象庁が公開しているベストトラックデー タを使用します http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/besttrack.html • 台風の軌道を後から分析するので、 1ヶ月位前のデータ(らしい)です –予報ではなく、実測値 • フォーマットはこんな感じです http://homepage3.nifty.com/typhoon21/general/bst-format.html Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 66. 台風の軌道を描いてみよう • まずはRで日本辺りを描いてみまし ょう • libraryはmapsを使用します > install.packages("maps") > library(maps) > map(xlim=c(121, 155), ylim=c(20, 50)) #緯度経度の範囲を指定して描画 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 67. 台風の軌道を描いてみよう • mapsは高機能な地図描画library • plotだけでなく、描画パスを取得でき る(ggplot2との相性良し) > map(plot=FALSE, xlim=c(121, 155), ylim=c(20, 50)) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 68. 台風の軌道を描いてみよう 2013年分の気象庁のベストトラックデータを 読み込みます > bst<-readLines('http://www.jma.go.jp/jma/jma-eng/jmacenter/rsmc-hp-pub-eg/Besttracks/bst2013.txt') > View(bst) # Web上のテキストファイルを直接読み込む Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 69. 台風の軌道を描いてみよう Header部を抜き出します > header <- read.table(textConnection(bst[grep("^66666", bst)])) > View(header) HeaderとRecordとで列が違うので、個別に 処理する Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 70. 台風の軌道を描いてみよう 次にRecord部を処理します > record<-read.table(textConnection(bst[-grep("^66666", bst)]),fill=TRUE) > record<-record[!is.na(record[,7]),] > View(record) レコードによって列の数が違うので、ゴミレコー ドが発生します。ゴミの除去も行います。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 71. 台風の軌道を描いてみよう 必要な列のみ抽出し、列名を付ける > header<-header[ , c(3,4,8)] > names(header) <- c("NROW", "TC_NO", "NAME") > View(header) > record<-record[ , c(1,3:7)] > names(record) <- c("DATE_TIME", "GRADE", "LAT", "LON", "HPA", "KT") > View(record) Header: データ数(NROW)、TropicalCyclone番号(TC_NO)、 台風の国際名(NAME) Record:観測時刻(DATE_TIME)、階級(GRADE)、緯度 (LAT)、経度(LON)、中心気圧(HPA)、最大風速(KT) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 72. 台風の軌道を描いてみよう RecordにHeaderのID(TC_NO)を付与します > record$TC_NO <- rep(header$TC_NO, header$NROW) > View(record) NROWに行数を持っているので行数分TC_NOを付 与していくと、すべてのRecordにTC_NOが付与で きます Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 73. 台風の軌道を描いてみよう TC_NOを基に、RecordとHeaderを結合します > data <- merge(header, record, by = "TC_NO") > View(data) ここまでの作業は、気象庁ベストトラックデータの 正規化を崩して処理しやすい形に変換していま す Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 74. 台風の軌道を描いてみよう 気象庁のデータでは緯度経度が10倍されている ので補正します。 > data <- transform(data, LAT = LAT / 10, LON = LON / 10) > View(data) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 75. 台風の軌道を描いてみよう 緯度経度の範囲を確認します > range_lon<-range(data$LON) > range_lat<-range(data$LAT) > range_lon > range_lat 地図の描画時にデータの範囲よりも余裕を持た せた地図領域を確保するためです Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 76. 台風の軌道を描いてみよう 該当範囲の地図の座標パスを生成します > map<-data.frame(map(plot=FALSE, xlim=c(range_lon[1]-10, range_lon[2]+10), ylim=c(range_lat[1]-5, range_lat[2]+5))[c("x","y")]) 地図の描画ではなく、座標パスであるところが注 意。描画はggplotを使用します Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 77. 台風の軌道を描いてみよう 一度描画してみます > ggplot(data, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE)) + geom_path(aes(x, y, colour = NULL), map) 台風の強さ(Grade)を大きさにしています 台風の名前で色づけしています Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 78. 台風の軌道を描いてみよう 少し台風の軌道っぽくしてみます > ggplot(data, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE), shape = 1, alpha = 0.5) + geom_path() + geom_path(aes(x, y, colour = NULL), map) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 79. 台風の軌道を描いてみよう もう少しきれいにしてみましょう > ggplot(data, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE), shape = 1, alpha = 0.5, show_guide=FALSE) + geom_path() + geom_path(aes(x, y, colour = NULL), map) + theme_bw() + labs(title = "2013's typhoons", x="",y="") + guides(col = guide_legend(nrow = 16)) 背景、ラベル、凡例をそれぞれカスタマイズ Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 80. 台風の軌道を描いてみよう 日本付近のデータで絞り込んでみます > target_tcno<-unique(data[(121<=data$LON&data$LON<=155)& (20<=data$LAT&data$LAT<=50), 1]) > data2<-data[data$TC_NO%in%target_tcno,] 日本の付近の以下の範囲を通過している 台風 緯度:121~155 経度:20~50 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 81. 台風の軌道を描いてみよう > ggplot(data2, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE), shape = 1, alpha = 0.7, show_guide=FALSE) + geom_path() + geom_path(aes(x, y, colour = NULL), map) + theme_bw() + labs(title = "2013's typhoons in Japan", x="",y="") + guides(col = guide_legend(nrow = 16)) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 82. 台風の軌道を描いてみよう 最後に画像で保存します > p<-ggplot(data2, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE), shape = 1, alpha = 0.7, show_guide=FALSE) + geom_path() + geom_path(aes(x, y, colour = NULL), map) + theme_bw() + labs(title = "2013's typhoons in Japan", x="",y="") + guides(col = guide_legend(nrow = 16)) > ggsave("typhoons.png", p) ggsaveは拡張子から保存形式を判断してくれる偉い子 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 83. 台風の軌道を描いてみよう その他:色もカスタマイズできたりします > colours<-c("#F66262","#E00000", "#E07000", "#11d445", "#eb9f03", "#9d5e09", "#16a394", "#e426b0", "#999b64", "#d73e43", "#9d75f7", "#cc1850", "#ccd21c", "#9e0be0", "#144fde", "#f9af4b", "#529748", "#58d2a3", "#2c5107", "#565a24", "#be875a", "#e3730c") > ggplot(data2, aes(LON, LAT, colour = NAME)) + geom_point(aes(size = GRADE), shape = 1, alpha = 0.8, show_guide=FALSE) + geom_path() + geom_path(aes(x, y, colour = NULL), map) + theme_bw() + labs(title = "2013's typhoons in Japan", x="",y="") + guides(col = guide_legend(nrow = 16)) + scale_color_manual("NAME", values= colours) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 84. 完成!! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 85. •R言語いろいろ •ご紹介コーナー Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 85
- 86. Rコマンダー(Rcmdr) • Rの基本的な統計関数を使いやすくするための GUIパッケージ • 慣れないうちは重宝するかも? – GUIで操作した結果は全てコマンドとして出力 • グラフィックが重かったりたまに不安定になったりす るけどね あくまでサポート的なツールなのかな 最新のMacだとXCode入れないと動かない かもね Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 87. Rコマンダー(Rcmdr) でも • まずはRコマンダーを立ち上げる > install.packages("Rcmdr") > library(Rcmdr) • アクティブなデータセットを使って、色々いじってみよ う – グラフを描画したり、統計関数を使ってみたり、、、 – GUI操作の結果、コードが出力される Rで何が出来るか参考にしよう! Rでも頑張れば、こんな3Dモデルも作れる よ! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 88. Rで形態素解析(RMeCab) • 汎用の形態素解析MeCabをRから操作 • MeCabをインストールしていないといけないのでちょっ と環境構築が難しいかも? • MeCabのデフォルト辞書が貧弱なので、ユーザ辞書 を入れて使用する – Wikipedia、hatenaが公開している単語リストをまずは 組み込むのが一般的 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 89. Rで形態素解析(RMeCab) でも • まずはRMeCabの読み込み(MeCabをインストールし ていないと動きません) > install.packages("RMeCab") > library(RMeCab) • テキストファイルを読み込み、形態素解析して単 語の出現頻度をカウント(今回のデータは TwitterStreamingで収集) > rm<-RMeCabFreq("XXXXX.txt") > rm<-RMeCabFreq("/Users/sugawi/develop/ruby/tweet/2013091614.txt") # MyMemo Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 90. Rで形態素解析(RMeCab) でも • 20件以上の単語のみにフィルタリングしてゴミデー タも除去 > part_rm<-rm[rm$Freq > 20,] > part_rm<-part_rm[!part_rm$Info1=="記号",] > part_rm<-part_rm[!part_rm$Info2=="数",] > part_rm<-part_rm[!part_rm$Info1=="接続詞",] > part_rm<-part_rm[!part_rm$Info1=="接頭詞",] > part_rm<-part_rm[!part_rm$Info1=="連体詞",] > part_rm<-part_rm[!part_rm$Info1=="助詞",] > part_rm<-part_rm[!part_rm$Info1=="助動詞",] > part_rm<-part_rm[!part_rm$Info1=="副詞",] > part_rm<-part_rm[!part_rm$Info1=="感動詞",] > part_rm<-part_rm[!part_rm$Info2=="接尾",] > part_rm<-part_rm[!part_rm$Info2=="非自立",] > part_rm<-part_rm[!part_rm$Info2=="代名詞",] > part_rm<-part_rm[!part_rm$Info2=="サ変接続",] 予想外のデータもいっぱいできるから こまめに削除ルールを作るの ガツッと削除した後は個別のデータから削除対象を判断 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 91. RでSPARQL(SPARQL) • RDFを操作するクエリ「SPARQL」をRから 実行する • SPARQLで取得したデータをそのままRで 解析することが可能 • RDF、SPARQLの説明は割愛。。。 –たぶんこれだけで半日掛かりそう Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 92. RでSPARQL(SPARQL) でも • まずはSPARQLの読み込み > install.packages("SPARQL") > library(SPARQL) • DBPediaから東京に関するものを抽出 読み込んでから何をするかがRの出 > url<-http://dbpedia.org/sparql > query="SELECT * 番なの WHERE { <http://dbpedia.org/resource/Tokyo> ?p ?o } LIMIT 400" > res<-SPARQL(url=url,query=query) Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 93. その他 • 豊富なパッケージにより、いろいろなことが実 現可能になってきました • さらには分散処理できるようにRHadoopなる ものもあります – HadoopをRから実行 – Hadoopに関する知識が必要なため、かなり敷居が高 い • DBもMongoDBと連携できるRMongoなどもあり、もう 何でもできるんじゃないかっていう錯覚も Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 94. •第二部はこちらへ •http://www.slideshare.net/yasuyukisugai/rja vascript-visualization Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 94
- 95. お疲れ様でした! R言語はどうでしたか? 楽しんでいただけましたか? AITC非公式キャラクター ハルミン Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved.
- 96. •次回のAITCオープンラボは「RDF/SPARQL」勉強会を予 定しています •LinkedOpendDataなどでは当たり前に使われていますが、 まだまだ一般的には普及していません •AITCでも情報を蓄積する際にRDFを、取り出す際には SPARQLを使用しています •「RDFとは」から始まり、後半ではSPARQLを皆で書いて みよう!と考えております •また日程が決まり次第イベントをお知らせします! Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 96
- 97. •本日はお集まり頂き、ありがと うございました。 •アンケートにもご協力ください。 Copyright © 2013 Advanced IT Consortium to Evaluate, Apply and Drive All Rights Reserved. 97